 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiet deep generative audio models with structured lottery
Paper and Code
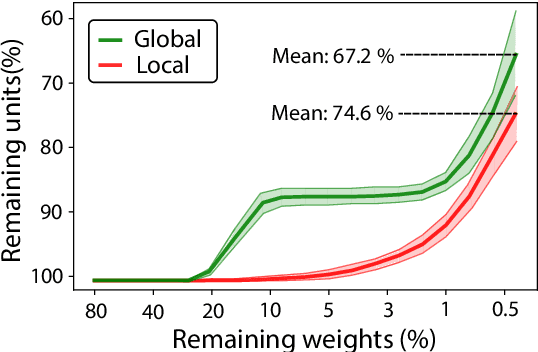
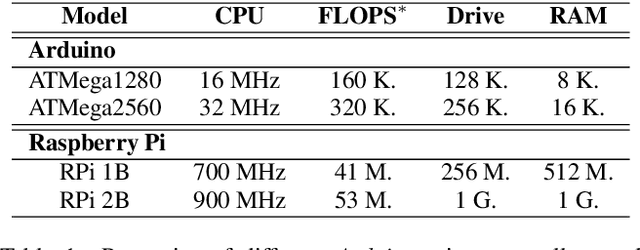
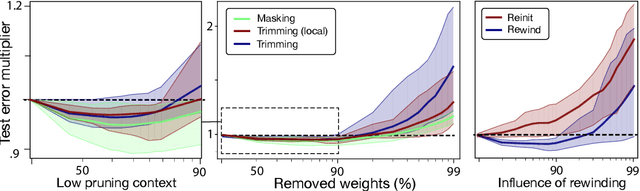
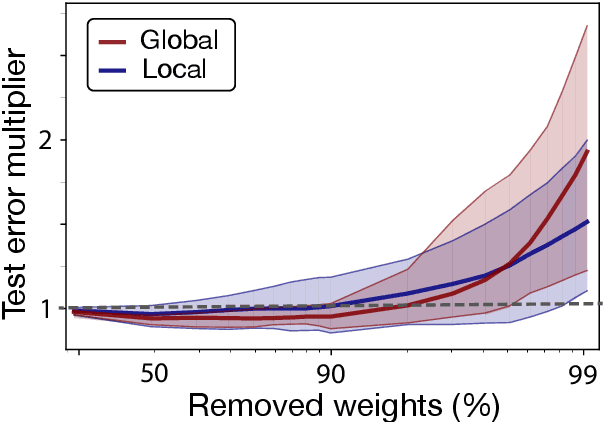
Deep learning models have provided extremely successful solutions in most audio application fields. However, the high accuracy of these models comes at the expense of a tremendous computation cost. This aspect is almost always overlooked in evaluating the quality of proposed models. However, models should not be evaluated without taking into account their complexity. This aspect is especially critical in audio applications, which heavily relies on specialized embedded hardware with real-time constraints. In this paper, we build on recent observations that deep models are highly overparameterized, by studying the lottery ticket hypothesis on deep generative audio models. This hypothesis states that extremely efficient small sub-networks exist in deep models and would provide higher accuracy than larger models if trained in isolation. However, lottery tickets are found by relying on unstructured masking, which means that resulting models do not provide any gain in either disk size or inference time. Instead, we develop here a method aimed at performing structured trimming. We show that this requires to rely on global selection and introduce a specific criterion based on mutual information. First, we confirm the surprising result that smaller models provide higher accuracy than their large counterparts. We further show that we can remove up to 95% of the model weights without significant degradation in accuracy. Hence, we can obtain very light models for generative audio across popular methods such as Wavenet, SING or DDSP, that are up to 100 times smaller with commensurate accuracy. We study the theoretical bounds for embedding these models on Raspberry Pi and Arduino, and show that we can obtain generative models on CPU with equivalent quality as large GPU models. Finally, we discuss the possibility of implementing deep generative audio models on embedded platforms.