 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreative divergent synthesis with generative models
Nov 16, 2022

Machine learning approaches now achieve impressive generation capabilities in numerous domains such as image, audio or video. However, most training \& evaluation frameworks revolve around the idea of strictly modelling the original data distribution rather than trying to extrapolate from it. This precludes the ability of such models to diverge from the original distribution and, hence, exhibit some creative traits. In this paper, we propose various perspectives on how this complicated goal could ever be achieved, and provide preliminary results on our novel training objective called \textit{Bounded Adversarial Divergence} (BAD).
Challenges in creative generative models for music: a divergence maximization perspective
Nov 16, 2022
The development of generative Machine Learning (ML) models in creative practices, enabled by the recent improvements in usability and availability of pre-trained models, is raising more and more interest among artists, practitioners and performers. Yet, the introduction of such techniques in artistic domains also revealed multiple limitations that escape current evaluation methods used by scientists. Notably, most models are still unable to generate content that lay outside of the domain defined by the training dataset. In this paper, we propose an alternative prospective framework, starting from a new general formulation of ML objectives, that we derive to delineate possible implications and solutions that already exist in the ML literature (notably for the audio and musical domain). We also discuss existing relations between generative models and computational creativity and how our framework could help address the lack of creativity in existing models.
Diet deep generative audio models with structured lottery
Jul 31, 2020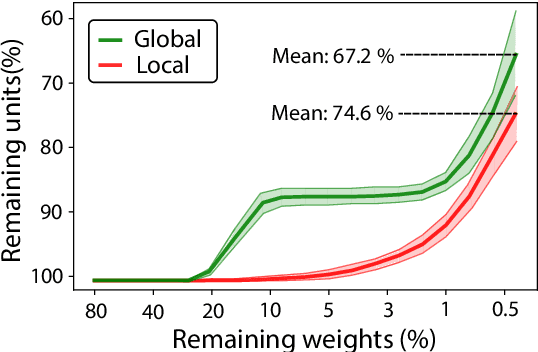
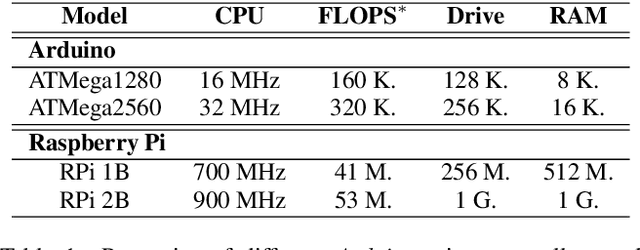
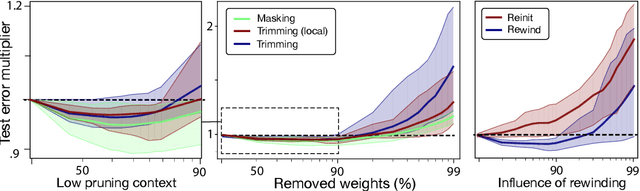
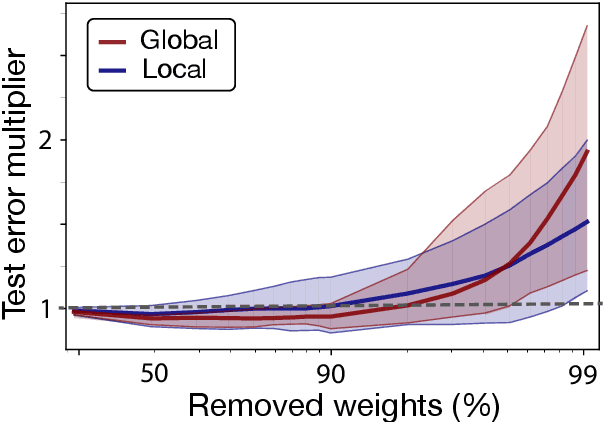
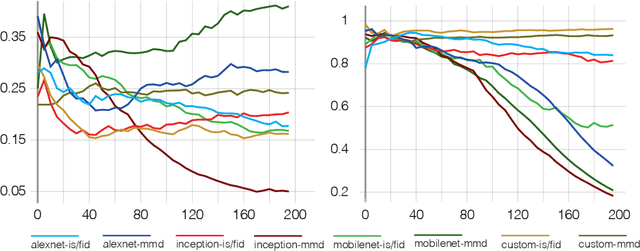
Deep learning models have provided extremely successful solutions in most audio application fields. However, the high accuracy of these models comes at the expense of a tremendous computation cost. This aspect is almost always overlooked in evaluating the quality of proposed models. However, models should not be evaluated without taking into account their complexity. This aspect is especially critical in audio applications, which heavily relies on specialized embedded hardware with real-time constraints. In this paper, we build on recent observations that deep models are highly overparameterized, by studying the lottery ticket hypothesis on deep generative audio models. This hypothesis states that extremely efficient small sub-networks exist in deep models and would provide higher accuracy than larger models if trained in isolation. However, lottery tickets are found by relying on unstructured masking, which means that resulting models do not provide any gain in either disk size or inference time. Instead, we develop here a method aimed at performing structured trimming. We show that this requires to rely on global selection and introduce a specific criterion based on mutual information. First, we confirm the surprising result that smaller models provide higher accuracy than their large counterparts. We further show that we can remove up to 95% of the model weights without significant degradation in accuracy. Hence, we can obtain very light models for generative audio across popular methods such as Wavenet, SING or DDSP, that are up to 100 times smaller with commensurate accuracy. We study the theoretical bounds for embedding these models on Raspberry Pi and Arduino, and show that we can obtain generative models on CPU with equivalent quality as large GPU models. Finally, we discuss the possibility of implementing deep generative audio models on embedded platforms.
Cross-modal variational inference for bijective signal-symbol translation
Feb 10, 2020
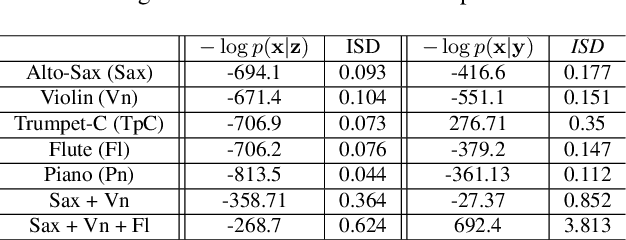
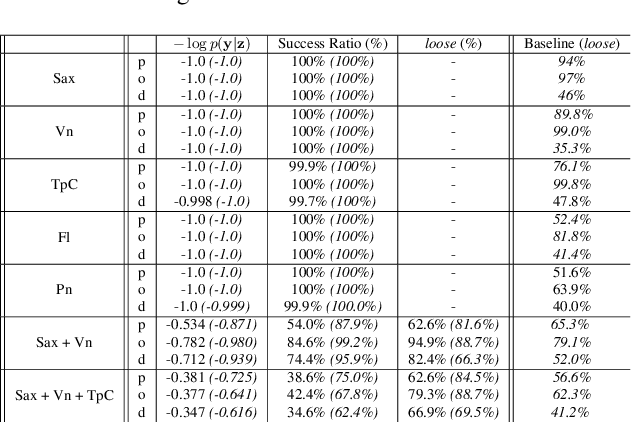

Extraction of symbolic information from signals is an active field of research enabling numerous applications especially in the Musical Information Retrieval domain. This complex task, that is also related to other topics such as pitch extraction or instrument recognition, is a demanding subject that gave birth to numerous approaches, mostly based on advanced signal processing-based algorithms. However, these techniques are often non-generic, allowing the extraction of definite physical properties of the signal (pitch, octave), but not allowing arbitrary vocabularies or more general annotations. On top of that, these techniques are one-sided, meaning that they can extract symbolic data from an audio signal, but cannot perform the reverse process and make symbol-to-signal generation. In this paper, we propose an bijective approach for signal/symbol translation by turning this problem into a density estimation task over signal and symbolic domains, considered both as related random variables. We estimate this joint distribution with two different variational auto-encoders, one for each domain, whose inner representations are forced to match with an additive constraint, allowing both models to learn and generate separately while allowing signal-to-symbol and symbol-to-signal inference. In this article, we test our models on pitch, octave and dynamics symbols, which comprise a fundamental step towards music transcription and label-constrained audio generation. In addition to its versatility, this system is rather light during training and generation while allowing several interesting creative uses that we outline at the end of the article.
Universal audio synthesizer control with normalizing flows
Jul 01, 2019
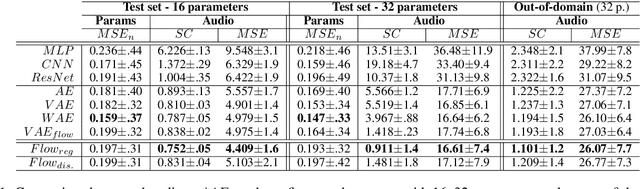
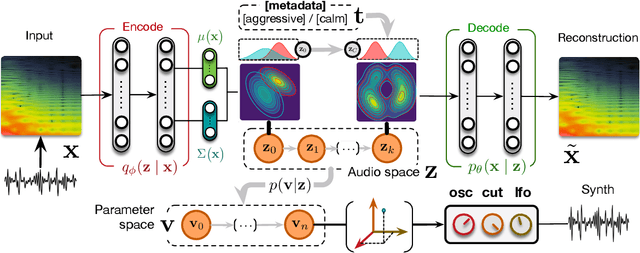
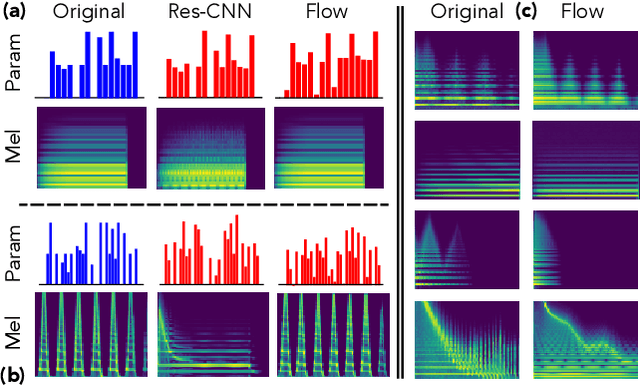
The ubiquity of sound synthesizers has reshaped music production and even entirely defined new music genres. However, the increasing complexity and number of parameters in modern synthesizers make them harder to master. Hence, the development of methods allowing to easily create and explore with synthesizers is a crucial need. Here, we introduce a novel formulation of audio synthesizer control. We formalize it as finding an organized latent audio space that represents the capabilities of a synthesizer, while constructing an invertible mapping to the space of its parameters. By using this formulation, we show that we can address simultaneously automatic parameter inference, macro-control learning and audio-based preset exploration within a single model. To solve this new formulation, we rely on Variational Auto-Encoders (VAE) and Normalizing Flows (NF) to organize and map the respective auditory and parameter spaces. We introduce the disentangling flows, which allow to perform the invertible mapping between separate latent spaces, while steering the organization of some latent dimensions to match target variation factors by splitting the objective as partial density evaluation. We evaluate our proposal against a large set of baseline models and show its superiority in both parameter inference and audio reconstruction. We also show that the model disentangles the major factors of audio variations as latent dimensions, that can be directly used as macro-parameters. We also show that our model is able to learn semantic controls of a synthesizer by smoothly mapping to its parameters. Finally, we discuss the use of our model in creative applications and its real-time implementation in Ableton Live