 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Sample-Based Musical Instruments Using Neural Audio Codec Language Models
Jul 22, 2024In this paper, we propose and investigate the use of neural audio codec language models for the automatic generation of sample-based musical instruments based on text or reference audio prompts. Our approach extends a generative audio framework to condition on pitch across an 88-key spectrum, velocity, and a combined text/audio embedding. We identify maintaining timbral consistency within the generated instruments as a major challenge. To tackle this issue, we introduce three distinct conditioning schemes. We analyze our methods through objective metrics and human listening tests, demonstrating that our approach can produce compelling musical instruments. Specifically, we introduce a new objective metric to evaluate the timbral consistency of the generated instruments and adapt the average Contrastive Language-Audio Pretraining (CLAP) score for the text-to-instrument case, noting that its naive application is unsuitable for assessing this task. Our findings reveal a complex interplay between timbral consistency, the quality of generated samples, and their correspondence to the input prompt.
Continuous descriptor-based control for deep audio synthesis
Feb 27, 2023



Despite significant advances in deep models for music generation, the use of these techniques remains restricted to expert users. Before being democratized among musicians, generative models must first provide expressive control over the generation, as this conditions the integration of deep generative models in creative workflows. In this paper, we tackle this issue by introducing a deep generative audio model providing expressive and continuous descriptor-based control, while remaining lightweight enough to be embedded in a hardware synthesizer. We enforce the controllability of real-time generation by explicitly removing salient musical features in the latent space using an adversarial confusion criterion. User-specified features are then reintroduced as additional conditioning information, allowing for continuous control of the generation, akin to a synthesizer knob. We assess the performance of our method on a wide variety of sounds including instrumental, percussive and speech recordings while providing both timbre and attributes transfer, allowing new ways of generating sounds.
Creativity in the era of artificial intelligence
Aug 13, 2020Creativity is a deeply debated topic, as this concept is arguably quintessential to our humanity. Across different epochs, it has been infused with an extensive variety of meanings relevant to that era. Along these, the evolution of technology have provided a plurality of novel tools for creative purposes. Recently, the advent of Artificial Intelligence (AI), through deep learning approaches, have seen proficient successes across various applications. The use of such technologies for creativity appear in a natural continuity to the artistic trend of this century. However, the aura of a technological artefact labeled as intelligent has unleashed passionate and somewhat unhinged debates on its implication for creative endeavors. In this paper, we aim to provide a new perspective on the question of creativity at the era of AI, by blurring the frontier between social and computational sciences. To do so, we rely on reflections from social science studies of creativity to view how current AI would be considered through this lens. As creativity is a highly context-prone concept, we underline the limits and deficiencies of current AI, requiring to move towards artificial creativity. We argue that the objective of trying to purely mimic human creative traits towards a self-contained ex-nihilo generative machine would be highly counterproductive, putting us at risk of not harnessing the almost unlimited possibilities offered by the sheer computational power of artificial agents.
Ultra-light deep MIR by trimming lottery tickets
Jul 31, 2020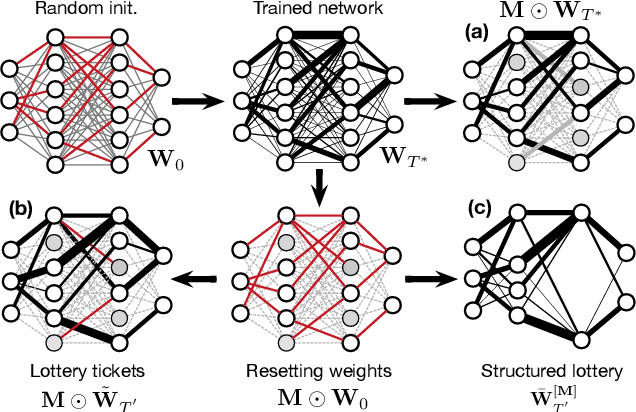
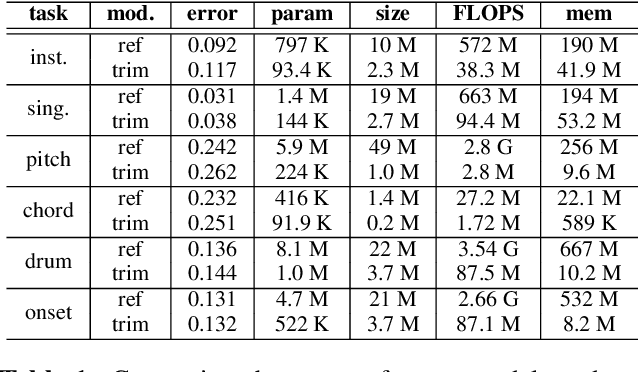
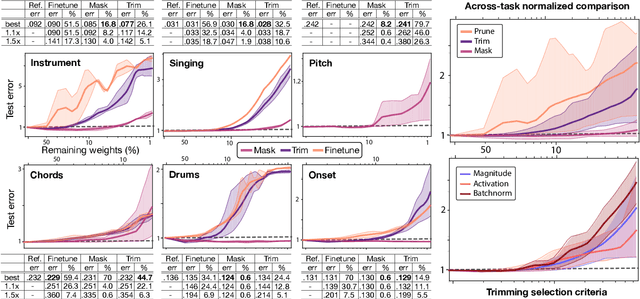
Current state-of-the-art results in Music Information Retrieval are largely dominated by deep learning approaches. These provide unprecedented accuracy across all tasks. However, the consistently overlooked downside of these models is their stunningly massive complexity, which seems concomitantly crucial to their success. In this paper, we address this issue by proposing a model pruning method based on the lottery ticket hypothesis. We modify the original approach to allow for explicitly removing parameters, through structured trimming of entire units, instead of simply masking individual weights. This leads to models which are effectively lighter in terms of size, memory and number of operations. We show that our proposal can remove up to 90% of the model parameters without loss of accuracy, leading to ultra-light deep MIR models. We confirm the surprising result that, at smaller compression ratios (removing up to 85% of a network), lighter models consistently outperform their heavier counterparts. We exhibit these results on a large array of MIR tasks including audio classification, pitch recognition, chord extraction, drum transcription and onset estimation. The resulting ultra-light deep learning models for MIR can run on CPU, and can even fit on embedded devices with minimal degradation of accuracy.
Diet deep generative audio models with structured lottery
Jul 31, 2020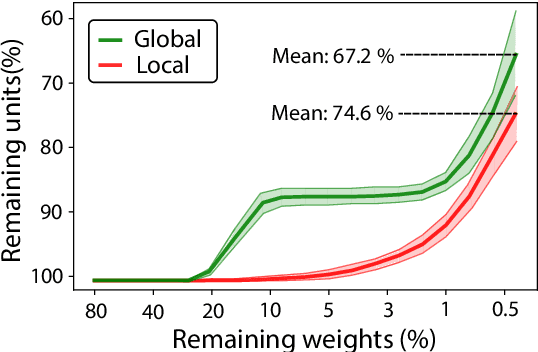
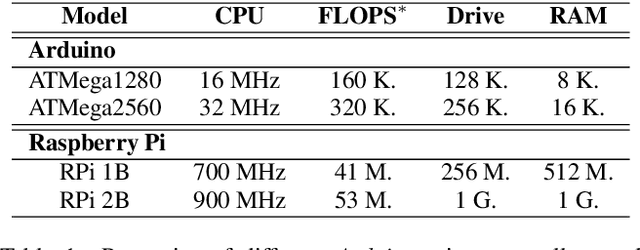
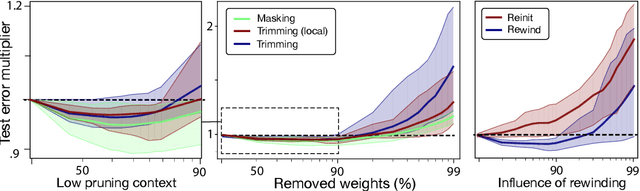
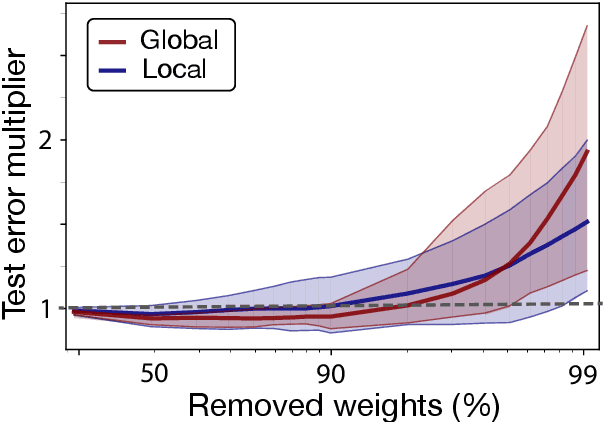
Deep learning models have provided extremely successful solutions in most audio application fields. However, the high accuracy of these models comes at the expense of a tremendous computation cost. This aspect is almost always overlooked in evaluating the quality of proposed models. However, models should not be evaluated without taking into account their complexity. This aspect is especially critical in audio applications, which heavily relies on specialized embedded hardware with real-time constraints. In this paper, we build on recent observations that deep models are highly overparameterized, by studying the lottery ticket hypothesis on deep generative audio models. This hypothesis states that extremely efficient small sub-networks exist in deep models and would provide higher accuracy than larger models if trained in isolation. However, lottery tickets are found by relying on unstructured masking, which means that resulting models do not provide any gain in either disk size or inference time. Instead, we develop here a method aimed at performing structured trimming. We show that this requires to rely on global selection and introduce a specific criterion based on mutual information. First, we confirm the surprising result that smaller models provide higher accuracy than their large counterparts. We further show that we can remove up to 95% of the model weights without significant degradation in accuracy. Hence, we can obtain very light models for generative audio across popular methods such as Wavenet, SING or DDSP, that are up to 100 times smaller with commensurate accuracy. We study the theoretical bounds for embedding these models on Raspberry Pi and Arduino, and show that we can obtain generative models on CPU with equivalent quality as large GPU models. Finally, we discuss the possibility of implementing deep generative audio models on embedded platforms.