 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltra-light deep MIR by trimming lottery tickets
Jul 31, 2020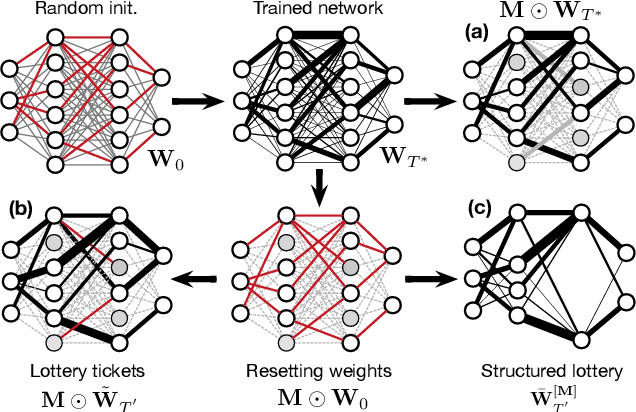
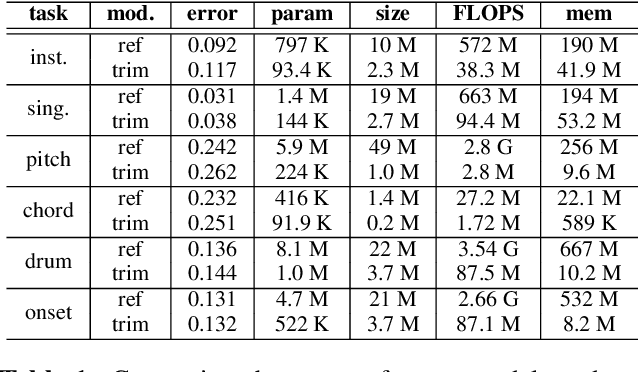
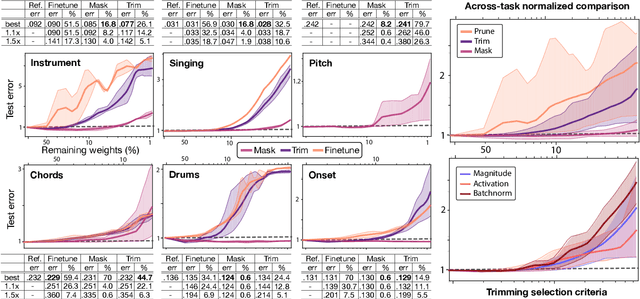
Current state-of-the-art results in Music Information Retrieval are largely dominated by deep learning approaches. These provide unprecedented accuracy across all tasks. However, the consistently overlooked downside of these models is their stunningly massive complexity, which seems concomitantly crucial to their success. In this paper, we address this issue by proposing a model pruning method based on the lottery ticket hypothesis. We modify the original approach to allow for explicitly removing parameters, through structured trimming of entire units, instead of simply masking individual weights. This leads to models which are effectively lighter in terms of size, memory and number of operations. We show that our proposal can remove up to 90% of the model parameters without loss of accuracy, leading to ultra-light deep MIR models. We confirm the surprising result that, at smaller compression ratios (removing up to 85% of a network), lighter models consistently outperform their heavier counterparts. We exhibit these results on a large array of MIR tasks including audio classification, pitch recognition, chord extraction, drum transcription and onset estimation. The resulting ultra-light deep learning models for MIR can run on CPU, and can even fit on embedded devices with minimal degradation of accuracy.