 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltra-light deep MIR by trimming lottery tickets
Jul 31, 2020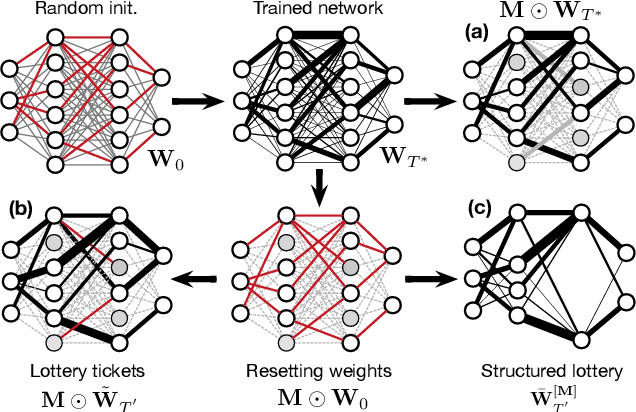
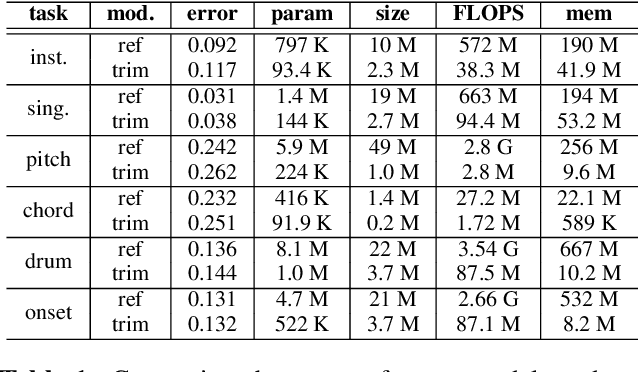
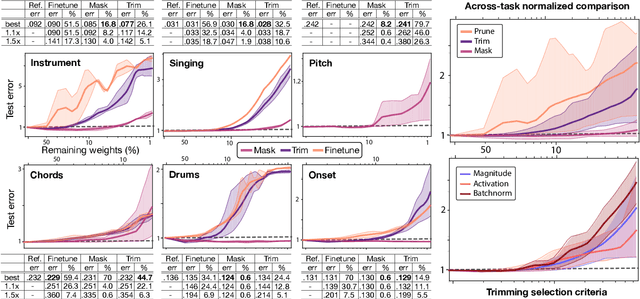
Current state-of-the-art results in Music Information Retrieval are largely dominated by deep learning approaches. These provide unprecedented accuracy across all tasks. However, the consistently overlooked downside of these models is their stunningly massive complexity, which seems concomitantly crucial to their success. In this paper, we address this issue by proposing a model pruning method based on the lottery ticket hypothesis. We modify the original approach to allow for explicitly removing parameters, through structured trimming of entire units, instead of simply masking individual weights. This leads to models which are effectively lighter in terms of size, memory and number of operations. We show that our proposal can remove up to 90% of the model parameters without loss of accuracy, leading to ultra-light deep MIR models. We confirm the surprising result that, at smaller compression ratios (removing up to 85% of a network), lighter models consistently outperform their heavier counterparts. We exhibit these results on a large array of MIR tasks including audio classification, pitch recognition, chord extraction, drum transcription and onset estimation. The resulting ultra-light deep learning models for MIR can run on CPU, and can even fit on embedded devices with minimal degradation of accuracy.
Semi-supervised Neural Chord Estimation Based on a Variational Autoencoder with Discrete Labels and Continuous Textures of Chords
May 14, 2020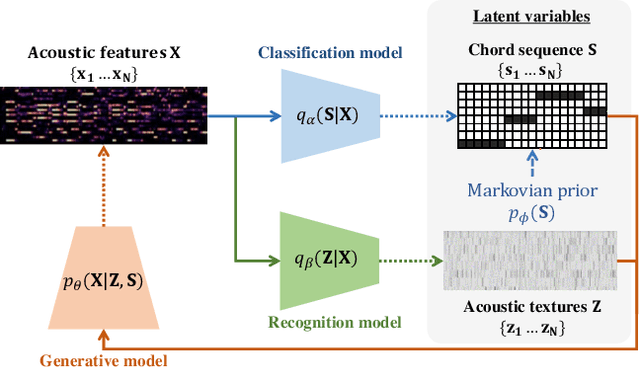
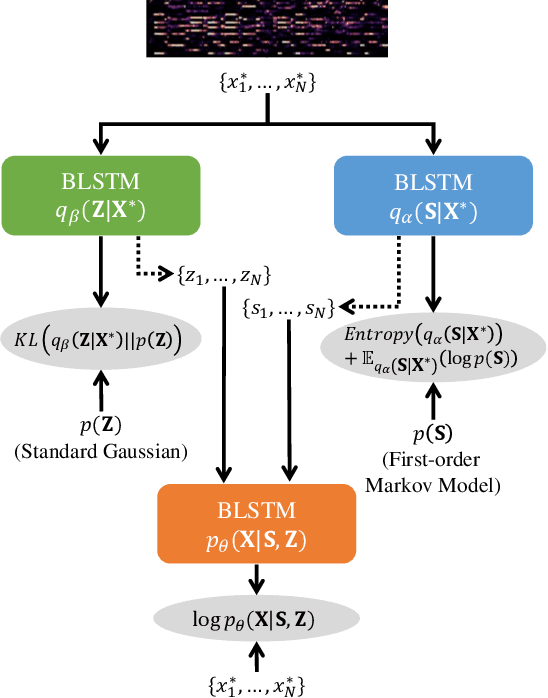

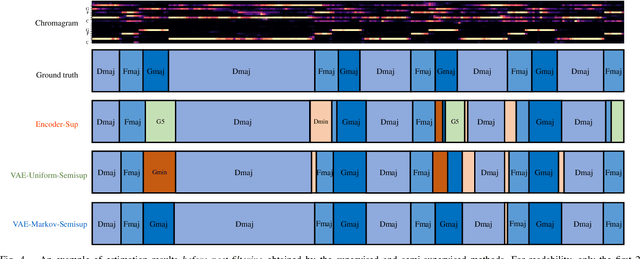
This paper describes a statistically-principled semi-supervised method of automatic chord estimation (ACE) that can make effective use of any music signals regardless of the availability of chord annotations. The typical approach to ACE is to train a deep classification model (neural chord estimator) in a supervised manner by using only a limited amount of annotated music signals. In this discriminative approach, prior knowledge about chord label sequences (characteristics of model output) has scarcely been taken into account. In contract, we propose a unified generative and discriminative approach in the framework of amortized variational inference. More specifically, we formulate a deep generative model that represents the complex generative process of chroma vectors (observed variables) from the discrete labels and continuous textures of chords (latent variables). Chord labels and textures are assumed to follow a Markov model favoring self-transitions and a standard Gaussian distribution, respectively. Given chroma vectors as observed data, the posterior distributions of latent chord labels and textures are computed approximately by using deep classification and recognition models, respectively. These three models are combined to form a variational autoencoder and trained jointly in a semi-supervised manner. The experimental results show that the performance of the classification model can be improved by additionally using non-annotated music signals and/or by regularizing the classification model with the Markov model of chord labels and the generative model of chroma vectors even in the fully-supervised condition.
Using musical relationships between chord labels in automatic chord extraction tasks
Nov 14, 2019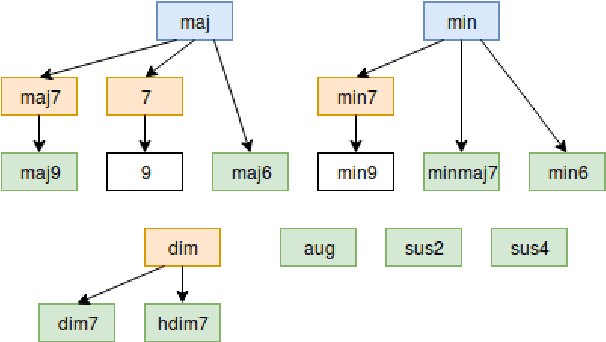
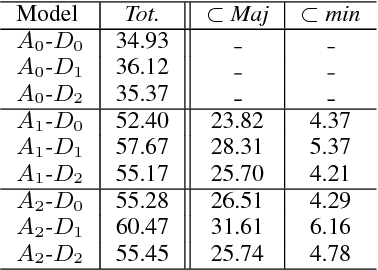
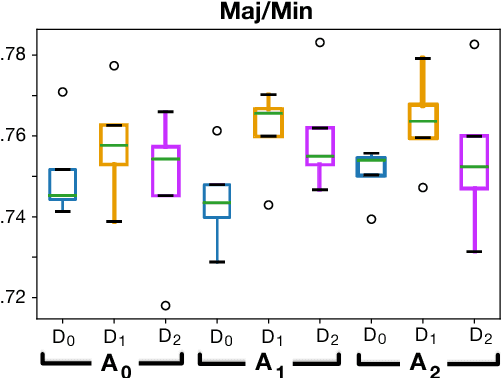
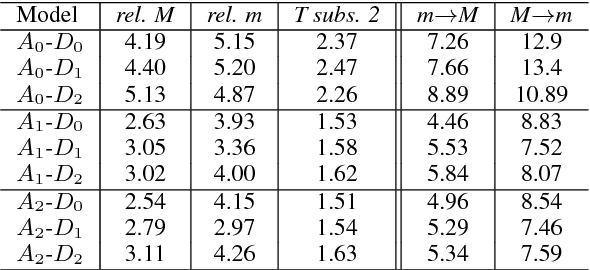
Recent researches on Automatic Chord Extraction (ACE) have focused on the improvement of models based on machine learning. However, most models still fail to take into account the prior knowledge underlying the labeling alphabets (chord labels). Furthermore, recent works have shown that ACE performances are converging towards a glass ceiling. Therefore, this prompts the need to focus on other aspects of the task, such as the introduction of musical knowledge in the representation, the improvement of the models towards more complex chord alphabets and the development of more adapted evaluation methods. In this paper, we propose to exploit specific properties and relationships between chord labels in order to improve the learning of statistical ACE models. Hence, we analyze the interdependence of the representations of chords and their associated distances, the precision of the chord alphabets, and the impact of the reduction of the alphabet before or after training of the model. Furthermore, we propose new training losses based on musical theory. We show that these improve the results of ACE systems based on Convolutional Neural Networks. By performing an in-depth analysis of our results, we uncover a set of related insights on ACE tasks based on statistical models, and also formalize the musical meaning of some classification errors.
Multi-Step Chord Sequence Prediction Based on Aggregated Multi-Scale Encoder-Decoder Network
Nov 12, 2019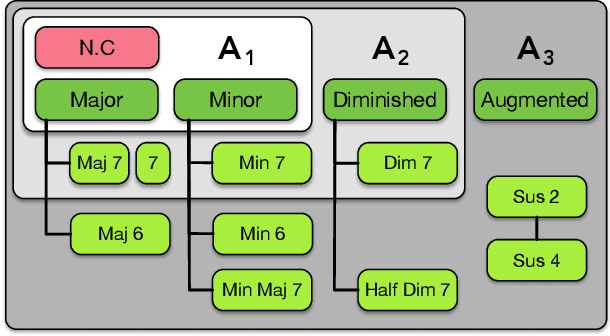
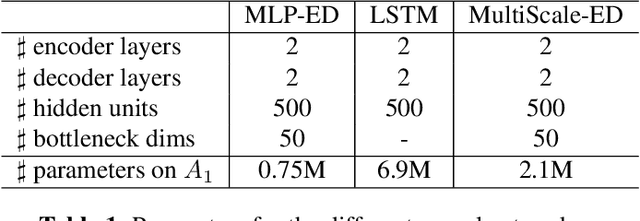
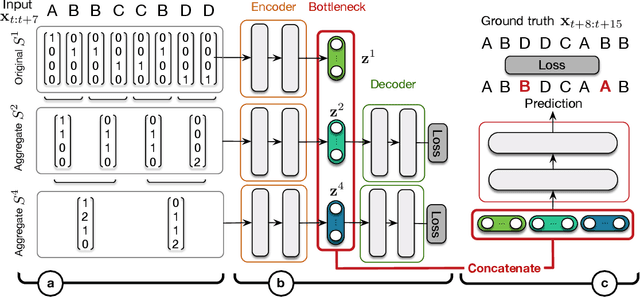
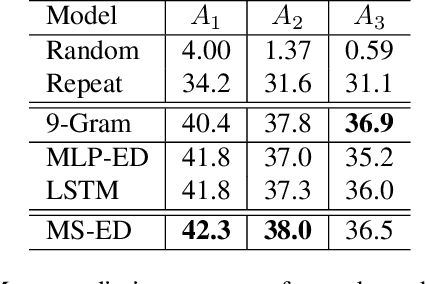
This paper studies the prediction of chord progressions for jazz music by relying on machine learning models. The motivation of our study comes from the recent success of neural networks for performing automatic music composition. Although high accuracies are obtained in single-step prediction scenarios, most models fail to generate accurate multi-step chord predictions. In this paper, we postulate that this comes from the multi-scale structure of musical information and propose new architectures based on an iterative temporal aggregation of input labels. Specifically, the input and ground truth labels are merged into increasingly large temporal bags, on which we train a family of encoder-decoder networks for each temporal scale. In a second step, we use these pre-trained encoder bottleneck features at each scale in order to train a final encoder-decoder network. Furthermore, we rely on different reductions of the initial chord alphabet into three adapted chord alphabets. We perform evaluations against several state-of-the-art models and show that our multi-scale architecture outperforms existing methods in terms of accuracy and perplexity, while requiring relatively few parameters. We analyze musical properties of the results, showing the influence of downbeat position within the analysis window on accuracy, and evaluate errors using a musically-informed distance metric.