 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Piano Transcription Based on Consistent Onset and Offset Decoding with Sustain Pedal Detection
Mar 03, 2025This paper describes a streaming audio-to-MIDI piano transcription approach that aims to sequentially translate a music signal into a sequence of note onset and offset events. The sequence-to-sequence nature of this task may call for the computationally-intensive transformer model for better performance, which has recently been used for offline transcription benchmarks and could be extended for streaming transcription with causal attention mechanisms. We assume that the performance limitation of this naive approach lies in the decoder. Although time-frequency features useful for onset detection are considerably different from those for offset detection, the single decoder is trained to output a mixed sequence of onset and offset events without guarantee of the correspondence between the onset and offset events of the same note. To overcome this limitation, we propose a streaming encoder-decoder model that uses a convolutional encoder aggregating local acoustic features, followed by an autoregressive Transformer decoder detecting a variable number of onset events and another decoder detecting the offset events for the active pitches with validation of the sustain pedal at each time frame. Experiments using the MAESTRO dataset showed that the proposed streaming method performed comparably with or even better than the state-of-the-art offline methods while significantly reducing the computational cost.
DOA-Aware Audio-Visual Self-Supervised Learning for Sound Event Localization and Detection
Oct 30, 2024This paper describes sound event localization and detection (SELD) for spatial audio recordings captured by firstorder ambisonics (FOA) microphones. In this task, one may train a deep neural network (DNN) using FOA data annotated with the classes and directions of arrival (DOAs) of sound events. However, the performance of this approach is severely bounded by the amount of annotated data. To overcome this limitation, we propose a novel method of pretraining the feature extraction part of the DNN in a self-supervised manner. We use spatial audio-visual recordings abundantly available as virtual reality contents. Assuming that sound objects are concurrently observed by the FOA microphones and the omni-directional camera, we jointly train audio and visual encoders with contrastive learning such that the audio and visual embeddings of the same recording and DOA are made close. A key feature of our method is that the DOA-wise audio embeddings are jointly extracted from the raw audio data, while the DOA-wise visual embeddings are separately extracted from the local visual crops centered on the corresponding DOA. This encourages the latent features of the audio encoder to represent both the classes and DOAs of sound events. The experiment using the DCASE2022 Task 3 dataset of 20 hours shows non-annotated audio-visual recordings of 100 hours reduced the error score of SELD from 36.4 pts to 34.9 pts.
Run-Time Adaptation of Neural Beamforming for Robust Speech Dereverberation and Denoising
Oct 30, 2024This paper describes speech enhancement for realtime automatic speech recognition (ASR) in real environments. A standard approach to this task is to use neural beamforming that can work efficiently in an online manner. It estimates the masks of clean dry speech from a noisy echoic mixture spectrogram with a deep neural network (DNN) and then computes a enhancement filter used for beamforming. The performance of such a supervised approach, however, is drastically degraded under mismatched conditions. This calls for run-time adaptation of the DNN. Although the ground-truth speech spectrogram required for adaptation is not available at run time, blind dereverberation and separation methods such as weighted prediction error (WPE) and fast multichannel nonnegative matrix factorization (FastMNMF) can be used for generating pseudo groundtruth data from a mixture. Based on this idea, a prior work proposed a dual-process system based on a cascade of WPE and minimum variance distortionless response (MVDR) beamforming asynchronously fine-tuned by block-online FastMNMF. To integrate the dereverberation capability into neural beamforming and make it fine-tunable at run time, we propose to use weighted power minimization distortionless response (WPD) beamforming, a unified version of WPE and minimum power distortionless response (MPDR), whose joint dereverberation and denoising filter is estimated using a DNN. We evaluated the impact of run-time adaptation under various conditions with different numbers of speakers, reverberation times, and signal-to-noise ratios (SNRs).
Neural Fast Full-Rank Spatial Covariance Analysis for Blind Source Separation
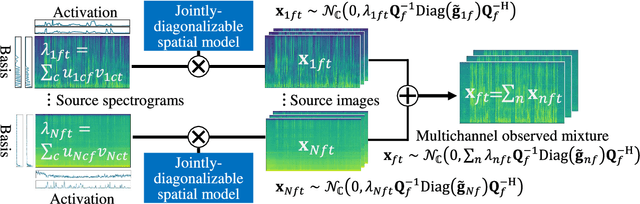
Jun 17, 2023This paper describes an efficient unsupervised learning method for a neural source separation model that utilizes a probabilistic generative model of observed multichannel mixtures proposed for blind source separation (BSS). For this purpose, amortized variational inference (AVI) has been used for directly solving the inverse problem of BSS with full-rank spatial covariance analysis (FCA). Although this unsupervised technique called neural FCA is in principle free from the domain mismatch problem, it is computationally demanding due to the full rankness of the spatial model in exchange for robustness against relatively short reverberations. To reduce the model complexity without sacrificing performance, we propose neural FastFCA based on the jointly-diagonalizable yet full-rank spatial model. Our neural separation model introduced for AVI alternately performs neural network blocks and single steps of an efficient iterative algorithm called iterative source steering. This alternating architecture enables the separation model to quickly separate the mixture spectrogram by leveraging both the deep neural network and the multichannel optimization algorithm. The training objective with AVI is derived to maximize the marginalized likelihood of the observed mixtures. The experiment using mixture signals of two to four sound sources shows that neural FastFCA outperforms conventional BSS methods and reduces the computational time to about 2% of that for the neural FCA.
Neural Steerer: Novel Steering Vector Synthesis with a Causal Neural Field over Frequency and Source Positions
May 08, 2023Neural fields have successfully been used in many research fields for their native ability to estimate a continuous function from a finite number of observations. In audio processing, this technique has been applied to acoustic and head-related transfer function interpolation. However, most of the existing methods estimate the real-valued magnitude function over a predefined discrete set of frequencies. In this study, we propose a novel approach for steering vector interpolation that regards frequencies as continuous input variables. Moreover, we propose a novel unsupervised regularization term enforcing the estimated filters to be causal. The experiment using real steering vectors show that the proposed frequency resolution-free method outperformed the existing methods operating over discrete set of frequencies.
DNN-Free Low-Latency Adaptive Speech Enhancement Based on Frame-Online Beamforming Powered by Block-Online FastMNMF
Jul 22, 2022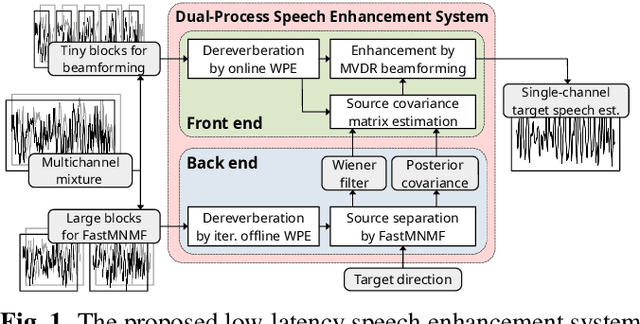
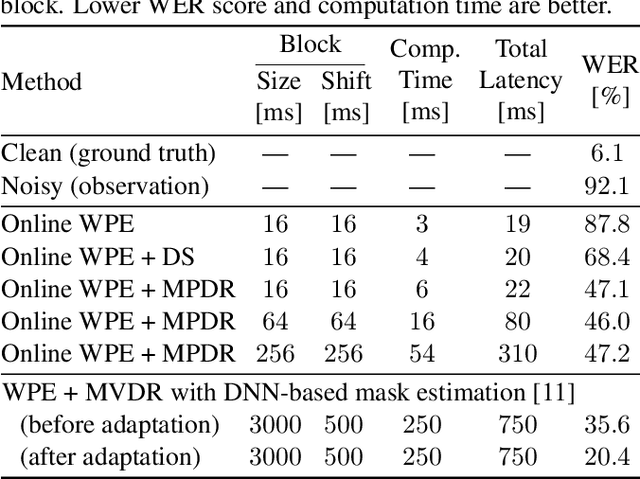

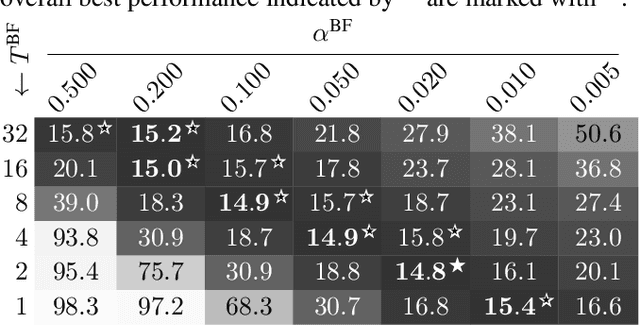
This paper describes a practical dual-process speech enhancement system that adapts environment-sensitive frame-online beamforming (front-end) with help from environment-free block-online source separation (back-end). To use minimum variance distortionless response (MVDR) beamforming, one may train a deep neural network (DNN) that estimates time-frequency masks used for computing the covariance matrices of sources (speech and noise). Backpropagation-based run-time adaptation of the DNN was proposed for dealing with the mismatched training-test conditions. Instead, one may try to directly estimate the source covariance matrices with a state-of-the-art blind source separation method called fast multichannel non-negative matrix factorization (FastMNMF). In practice, however, neither the DNN nor the FastMNMF can be updated in a frame-online manner due to its computationally-expensive iterative nature. Our DNN-free system leverages the posteriors of the latest source spectrograms given by block-online FastMNMF to derive the current source covariance matrices for frame-online beamforming. The evaluation shows that our frame-online system can quickly respond to scene changes caused by interfering speaker movements and outperformed an existing block-online system with DNN-based beamforming by 5.0 points in terms of the word error rate.
Direction-Aware Adaptive Online Neural Speech Enhancement with an Augmented Reality Headset in Real Noisy Conversational Environments
Jul 15, 2022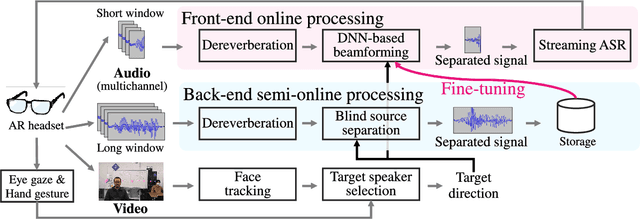

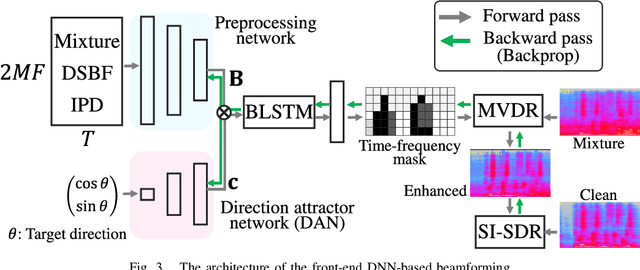
This paper describes the practical response- and performance-aware development of online speech enhancement for an augmented reality (AR) headset that helps a user understand conversations made in real noisy echoic environments (e.g., cocktail party). One may use a state-of-the-art blind source separation method called fast multichannel nonnegative matrix factorization (FastMNMF) that works well in various environments thanks to its unsupervised nature. Its heavy computational cost, however, prevents its application to real-time processing. In contrast, a supervised beamforming method that uses a deep neural network (DNN) for estimating spatial information of speech and noise readily fits real-time processing, but suffers from drastic performance degradation in mismatched conditions. Given such complementary characteristics, we propose a dual-process robust online speech enhancement method based on DNN-based beamforming with FastMNMF-guided adaptation. FastMNMF (back end) is performed in a mini-batch style and the noisy and enhanced speech pairs are used together with the original parallel training data for updating the direction-aware DNN (front end) with backpropagation at a computationally-allowable interval. This method is used with a blind dereverberation method called weighted prediction error (WPE) for transcribing the noisy reverberant speech of a speaker, which can be detected from video or selected by a user's hand gesture or eye gaze, in a streaming manner and spatially showing the transcriptions with an AR technique. Our experiment showed that the word error rate was improved by more than 10 points with the run-time adaptation using only twelve minutes of observation.
Direction-Aware Joint Adaptation of Neural Speech Enhancement and Recognition in Real Multiparty Conversational Environments
Jul 15, 2022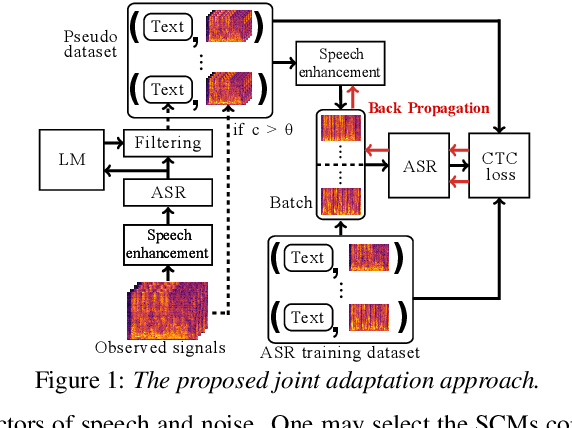
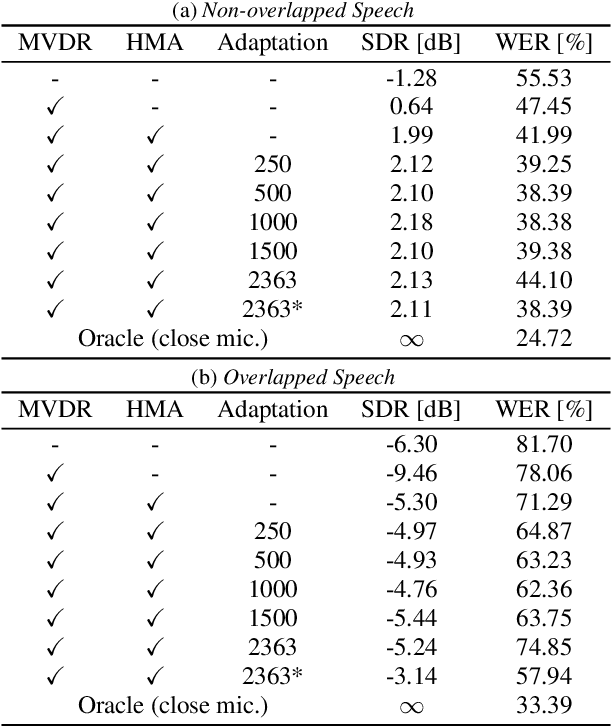
This paper describes noisy speech recognition for an augmented reality headset that helps verbal communication within real multiparty conversational environments. A major approach that has actively been studied in simulated environments is to sequentially perform speech enhancement and automatic speech recognition (ASR) based on deep neural networks (DNNs) trained in a supervised manner. In our task, however, such a pretrained system fails to work due to the mismatch between the training and test conditions and the head movements of the user. To enhance only the utterances of a target speaker, we use beamforming based on a DNN-based speech mask estimator that can adaptively extract the speech components corresponding to a head-relative particular direction. We propose a semi-supervised adaptation method that jointly updates the mask estimator and the ASR model at run-time using clean speech signals with ground-truth transcriptions and noisy speech signals with highly-confident estimated transcriptions. Comparative experiments using the state-of-the-art distant speech recognition system show that the proposed method significantly improves the ASR performance.
Generalized Fast Multichannel Nonnegative Matrix Factorization Based on Gaussian Scale Mixtures for Blind Source Separation
May 11, 2022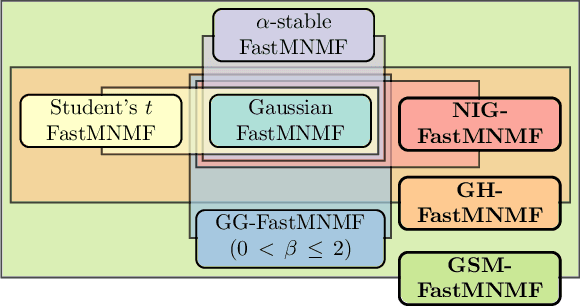
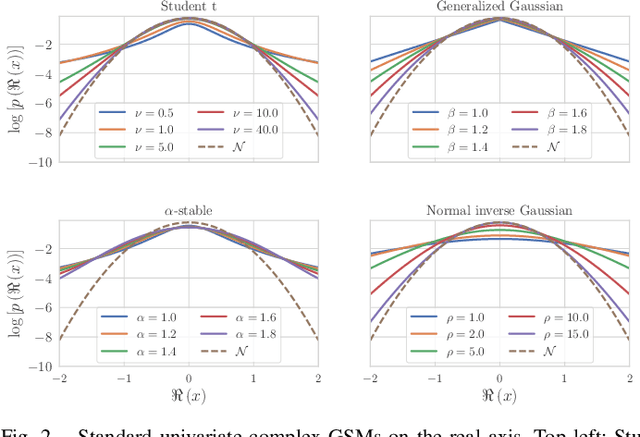
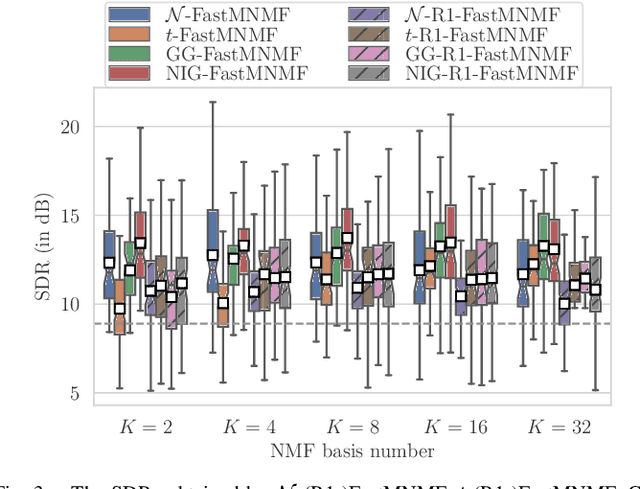
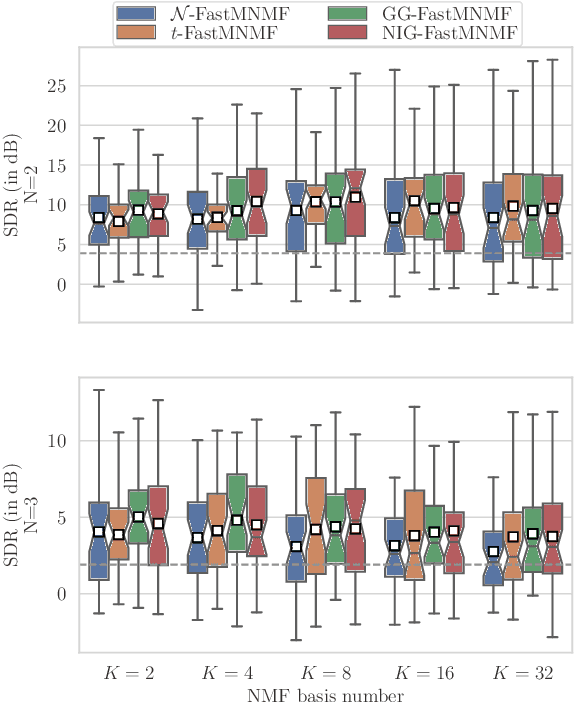
This paper describes heavy-tailed extensions of a state-of-the-art versatile blind source separation method called fast multichannel nonnegative matrix factorization (FastMNMF) from a unified point of view. The common way of deriving such an extension is to replace the multivariate complex Gaussian distribution in the likelihood function with its heavy-tailed generalization, e.g., the multivariate complex Student's t and leptokurtic generalized Gaussian distributions, and tailor-make the corresponding parameter optimization algorithm. Using a wider class of heavy-tailed distributions called a Gaussian scale mixture (GSM), i.e., a mixture of Gaussian distributions whose variances are perturbed by positive random scalars called impulse variables, we propose GSM-FastMNMF and develop an expectationmaximization algorithm that works even when the probability density function of the impulse variables have no analytical expressions. We show that existing heavy-tailed FastMNMF extensions are instances of GSM-FastMNMF and derive a new instance based on the generalized hyperbolic distribution that include the normal-inverse Gaussian, Student's t, and Gaussian distributions as the special cases. Our experiments show that the normalinverse Gaussian FastMNMF outperforms the state-of-the-art FastMNMF extensions and ILRMA model in speech enhancement and separation in terms of the signal-to-distortion ratio.
Global Structure-Aware Drum Transcription Based on Self-Attention Mechanisms
May 12, 2021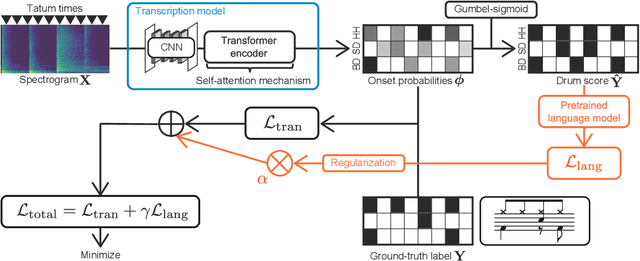
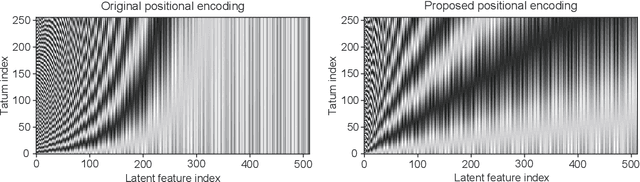
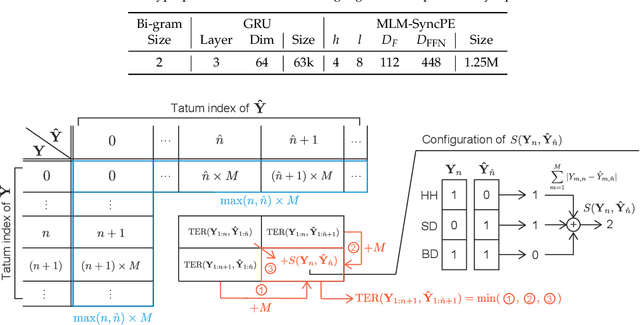
This paper describes an automatic drum transcription (ADT) method that directly estimates a tatum-level drum score from a music signal, in contrast to most conventional ADT methods that estimate the frame-level onset probabilities of drums. To estimate a tatum-level score, we propose a deep transcription model that consists of a frame-level encoder for extracting the latent features from a music signal and a tatum-level decoder for estimating a drum score from the latent features pooled at the tatum level. To capture the global repetitive structure of drum scores, which is difficult to learn with a recurrent neural network (RNN), we introduce a self-attention mechanism with tatum-synchronous positional encoding into the decoder. To mitigate the difficulty of training the self-attention-based model from an insufficient amount of paired data and improve the musical naturalness of the estimated scores, we propose a regularized training method that uses a global structure-aware masked language (score) model with a self-attention mechanism pretrained from an extensive collection of drum scores. Experimental results showed that the proposed regularized model outperformed the conventional RNN-based model in terms of the tatum-level error rate and the frame-level F-measure, even when only a limited amount of paired data was available so that the non-regularized model underperformed the RNN-based model.