 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRun-Time Adaptation of Neural Beamforming for Robust Speech Dereverberation and Denoising
Oct 30, 2024This paper describes speech enhancement for realtime automatic speech recognition (ASR) in real environments. A standard approach to this task is to use neural beamforming that can work efficiently in an online manner. It estimates the masks of clean dry speech from a noisy echoic mixture spectrogram with a deep neural network (DNN) and then computes a enhancement filter used for beamforming. The performance of such a supervised approach, however, is drastically degraded under mismatched conditions. This calls for run-time adaptation of the DNN. Although the ground-truth speech spectrogram required for adaptation is not available at run time, blind dereverberation and separation methods such as weighted prediction error (WPE) and fast multichannel nonnegative matrix factorization (FastMNMF) can be used for generating pseudo groundtruth data from a mixture. Based on this idea, a prior work proposed a dual-process system based on a cascade of WPE and minimum variance distortionless response (MVDR) beamforming asynchronously fine-tuned by block-online FastMNMF. To integrate the dereverberation capability into neural beamforming and make it fine-tunable at run time, we propose to use weighted power minimization distortionless response (WPD) beamforming, a unified version of WPE and minimum power distortionless response (MPDR), whose joint dereverberation and denoising filter is estimated using a DNN. We evaluated the impact of run-time adaptation under various conditions with different numbers of speakers, reverberation times, and signal-to-noise ratios (SNRs).
Implicit neural representation for change detection
Jul 28, 2023



Detecting changes that occurred in a pair of 3D airborne LiDAR point clouds, acquired at two different times over the same geographical area, is a challenging task because of unmatching spatial supports and acquisition system noise. Most recent attempts to detect changes on point clouds are based on supervised methods, which require large labelled data unavailable in real-world applications. To address these issues, we propose an unsupervised approach that comprises two components: Neural Field (NF) for continuous shape reconstruction and a Gaussian Mixture Model for categorising changes. NF offer a grid-agnostic representation to encode bi-temporal point clouds with unmatched spatial support that can be regularised to increase high-frequency details and reduce noise. The reconstructions at each timestamp are compared at arbitrary spatial scales, leading to a significant increase in detection capabilities. We apply our method to a benchmark dataset of simulated LiDAR point clouds for urban sprawling. The dataset offers different challenging scenarios with different resolutions, input modalities and noise levels, allowing a multi-scenario comparison of our method with the current state-of-the-art. We boast the previous methods on this dataset by a 10% margin in intersection over union metric. In addition, we apply our methods to a real-world scenario to identify illegal excavation (looting) of archaeological sites and confirm that they match findings from field experts.
Neural Steerer: Novel Steering Vector Synthesis with a Causal Neural Field over Frequency and Source Positions
May 08, 2023Neural fields have successfully been used in many research fields for their native ability to estimate a continuous function from a finite number of observations. In audio processing, this technique has been applied to acoustic and head-related transfer function interpolation. However, most of the existing methods estimate the real-valued magnitude function over a predefined discrete set of frequencies. In this study, we propose a novel approach for steering vector interpolation that regards frequencies as continuous input variables. Moreover, we propose a novel unsupervised regularization term enforcing the estimated filters to be causal. The experiment using real steering vectors show that the proposed frequency resolution-free method outperformed the existing methods operating over discrete set of frequencies.
Mean absorption estimation from room impulse responses using virtually supervised learning
Sep 01, 2021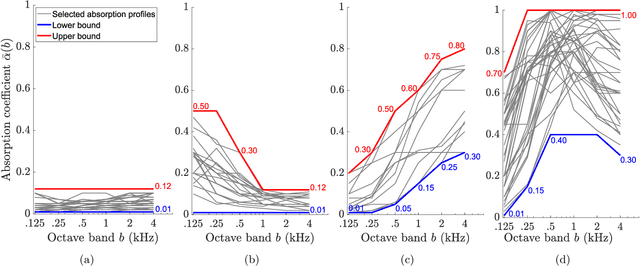
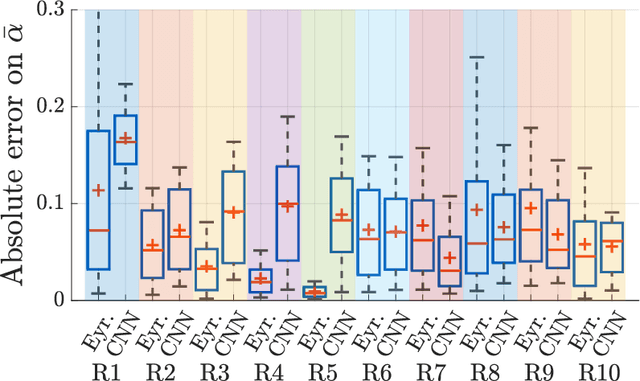
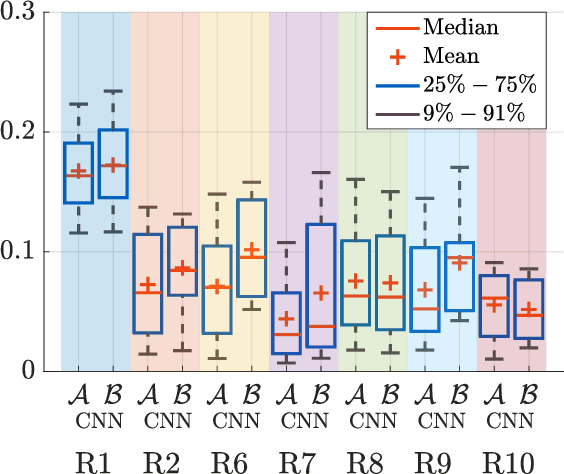
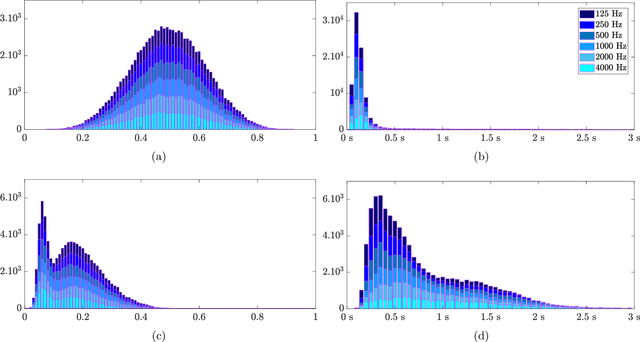
In the context of building acoustics and the acoustic diagnosis of an existing room, this paper introduces and investigates a new approach to estimate mean absorption coefficients solely from a room impulse response (RIR). This inverse problem is tackled via virtually-supervised learning, namely, the RIR-to-absorption mapping is implicitly learned by regression on a simulated dataset using artificial neural networks. We focus on simple models based on well-understood architectures. The critical choices of geometric, acoustic and simulation parameters used to train the models are extensively discussed and studied, while keeping in mind conditions that are representative of the field of building acoustics. Estimation errors from the learned neural models are compared to those obtained with classical formulas that require knowledge of the room's geometry and reverberation times. Extensive comparisons made on a variety of simulated test sets highlight different conditions under which the learned models can overcome the well-known limitations of the diffuse sound field hypothesis underlying these formulas. Results obtained on real RIRs measured in an acoustically configurable room show that at 1~kHz and above, the proposed approach performs comparably to classical models when reverberation times can be reliably estimated, and continues to work even when they cannot.
dEchorate: a Calibrated Room Impulse Response Database for Echo-aware Signal Processing
Apr 27, 2021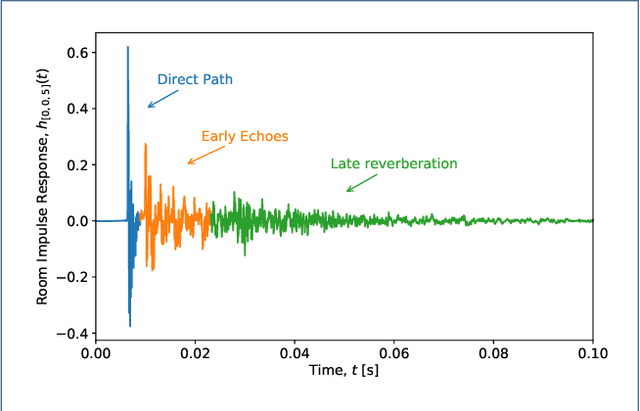
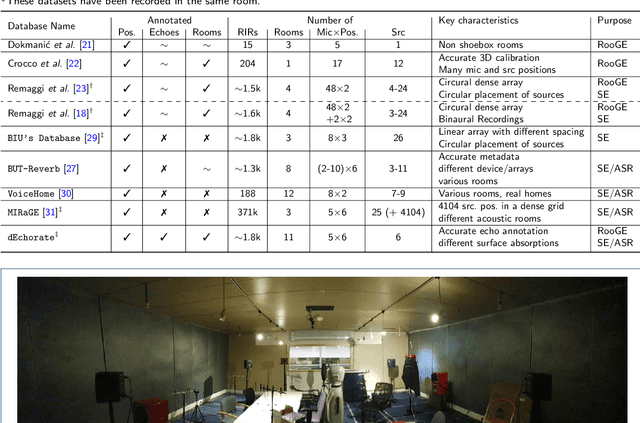

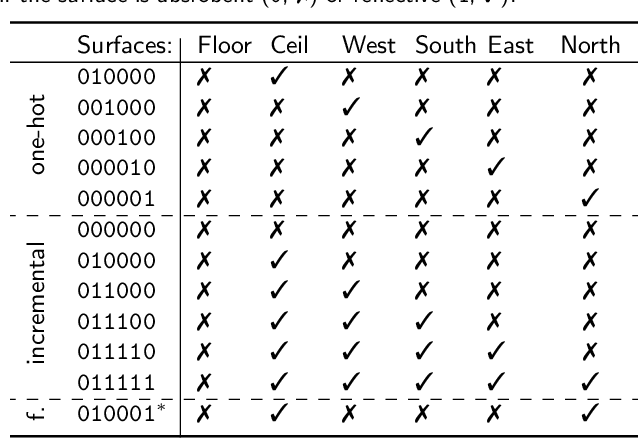
This paper presents dEchorate: a new database of measured multichannel Room Impulse Responses (RIRs) including annotations of early echo timings and 3D positions of microphones, real sources and image sources under different wall configurations in a cuboid room. These data provide a tool for benchmarking recent methods in echo-aware speech enhancement, room geometry estimation, RIR estimation, acoustic echo retrieval, microphone calibration, echo labeling and reflectors estimation. The database is accompanied with software utilities to easily access, manipulate and visualize the data as well as baseline methods for echo-related tasks.