 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRun-Time Adaptation of Neural Beamforming for Robust Speech Dereverberation and Denoising
Oct 30, 2024This paper describes speech enhancement for realtime automatic speech recognition (ASR) in real environments. A standard approach to this task is to use neural beamforming that can work efficiently in an online manner. It estimates the masks of clean dry speech from a noisy echoic mixture spectrogram with a deep neural network (DNN) and then computes a enhancement filter used for beamforming. The performance of such a supervised approach, however, is drastically degraded under mismatched conditions. This calls for run-time adaptation of the DNN. Although the ground-truth speech spectrogram required for adaptation is not available at run time, blind dereverberation and separation methods such as weighted prediction error (WPE) and fast multichannel nonnegative matrix factorization (FastMNMF) can be used for generating pseudo groundtruth data from a mixture. Based on this idea, a prior work proposed a dual-process system based on a cascade of WPE and minimum variance distortionless response (MVDR) beamforming asynchronously fine-tuned by block-online FastMNMF. To integrate the dereverberation capability into neural beamforming and make it fine-tunable at run time, we propose to use weighted power minimization distortionless response (WPD) beamforming, a unified version of WPE and minimum power distortionless response (MPDR), whose joint dereverberation and denoising filter is estimated using a DNN. We evaluated the impact of run-time adaptation under various conditions with different numbers of speakers, reverberation times, and signal-to-noise ratios (SNRs).
Neural Fast Full-Rank Spatial Covariance Analysis for Blind Source Separation
Jun 17, 2023This paper describes an efficient unsupervised learning method for a neural source separation model that utilizes a probabilistic generative model of observed multichannel mixtures proposed for blind source separation (BSS). For this purpose, amortized variational inference (AVI) has been used for directly solving the inverse problem of BSS with full-rank spatial covariance analysis (FCA). Although this unsupervised technique called neural FCA is in principle free from the domain mismatch problem, it is computationally demanding due to the full rankness of the spatial model in exchange for robustness against relatively short reverberations. To reduce the model complexity without sacrificing performance, we propose neural FastFCA based on the jointly-diagonalizable yet full-rank spatial model. Our neural separation model introduced for AVI alternately performs neural network blocks and single steps of an efficient iterative algorithm called iterative source steering. This alternating architecture enables the separation model to quickly separate the mixture spectrogram by leveraging both the deep neural network and the multichannel optimization algorithm. The training objective with AVI is derived to maximize the marginalized likelihood of the observed mixtures. The experiment using mixture signals of two to four sound sources shows that neural FastFCA outperforms conventional BSS methods and reduces the computational time to about 2% of that for the neural FCA.
Neural Steerer: Novel Steering Vector Synthesis with a Causal Neural Field over Frequency and Source Positions
May 08, 2023Neural fields have successfully been used in many research fields for their native ability to estimate a continuous function from a finite number of observations. In audio processing, this technique has been applied to acoustic and head-related transfer function interpolation. However, most of the existing methods estimate the real-valued magnitude function over a predefined discrete set of frequencies. In this study, we propose a novel approach for steering vector interpolation that regards frequencies as continuous input variables. Moreover, we propose a novel unsupervised regularization term enforcing the estimated filters to be causal. The experiment using real steering vectors show that the proposed frequency resolution-free method outperformed the existing methods operating over discrete set of frequencies.
DNN-Free Low-Latency Adaptive Speech Enhancement Based on Frame-Online Beamforming Powered by Block-Online FastMNMF
Jul 22, 2022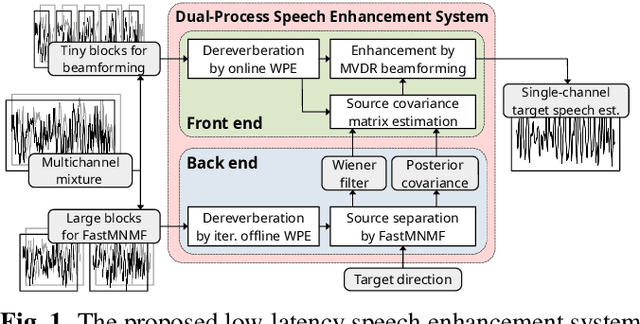
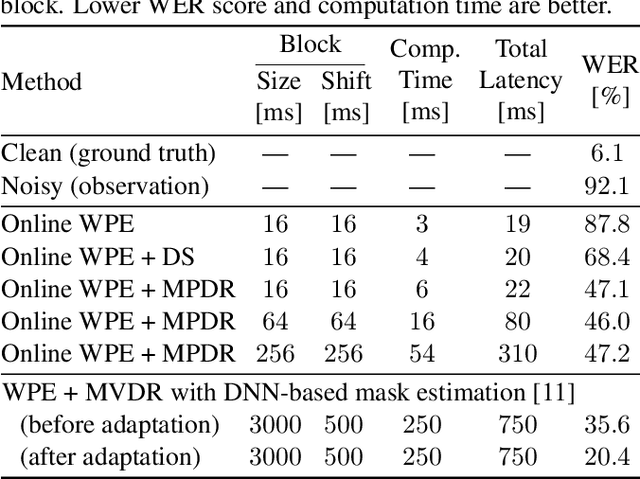

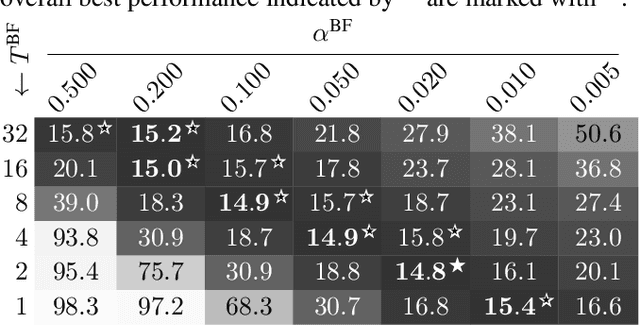
This paper describes a practical dual-process speech enhancement system that adapts environment-sensitive frame-online beamforming (front-end) with help from environment-free block-online source separation (back-end). To use minimum variance distortionless response (MVDR) beamforming, one may train a deep neural network (DNN) that estimates time-frequency masks used for computing the covariance matrices of sources (speech and noise). Backpropagation-based run-time adaptation of the DNN was proposed for dealing with the mismatched training-test conditions. Instead, one may try to directly estimate the source covariance matrices with a state-of-the-art blind source separation method called fast multichannel non-negative matrix factorization (FastMNMF). In practice, however, neither the DNN nor the FastMNMF can be updated in a frame-online manner due to its computationally-expensive iterative nature. Our DNN-free system leverages the posteriors of the latest source spectrograms given by block-online FastMNMF to derive the current source covariance matrices for frame-online beamforming. The evaluation shows that our frame-online system can quickly respond to scene changes caused by interfering speaker movements and outperformed an existing block-online system with DNN-based beamforming by 5.0 points in terms of the word error rate.
Direction-Aware Adaptive Online Neural Speech Enhancement with an Augmented Reality Headset in Real Noisy Conversational Environments
Jul 15, 2022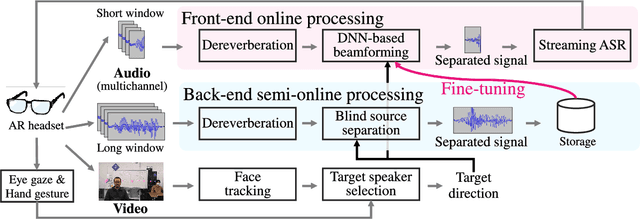

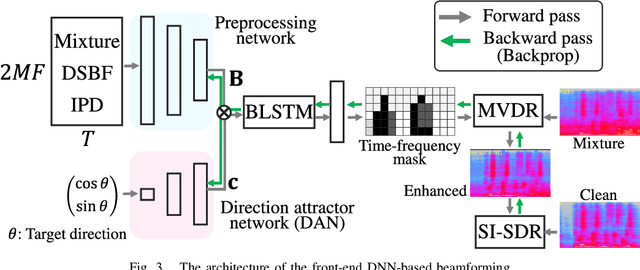
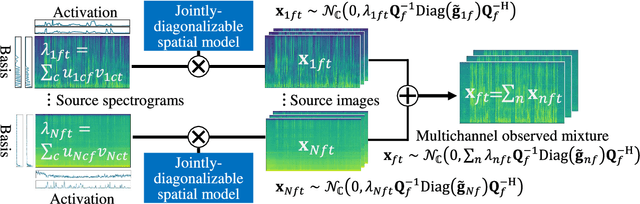
This paper describes the practical response- and performance-aware development of online speech enhancement for an augmented reality (AR) headset that helps a user understand conversations made in real noisy echoic environments (e.g., cocktail party). One may use a state-of-the-art blind source separation method called fast multichannel nonnegative matrix factorization (FastMNMF) that works well in various environments thanks to its unsupervised nature. Its heavy computational cost, however, prevents its application to real-time processing. In contrast, a supervised beamforming method that uses a deep neural network (DNN) for estimating spatial information of speech and noise readily fits real-time processing, but suffers from drastic performance degradation in mismatched conditions. Given such complementary characteristics, we propose a dual-process robust online speech enhancement method based on DNN-based beamforming with FastMNMF-guided adaptation. FastMNMF (back end) is performed in a mini-batch style and the noisy and enhanced speech pairs are used together with the original parallel training data for updating the direction-aware DNN (front end) with backpropagation at a computationally-allowable interval. This method is used with a blind dereverberation method called weighted prediction error (WPE) for transcribing the noisy reverberant speech of a speaker, which can be detected from video or selected by a user's hand gesture or eye gaze, in a streaming manner and spatially showing the transcriptions with an AR technique. Our experiment showed that the word error rate was improved by more than 10 points with the run-time adaptation using only twelve minutes of observation.
Direction-Aware Joint Adaptation of Neural Speech Enhancement and Recognition in Real Multiparty Conversational Environments
Jul 15, 2022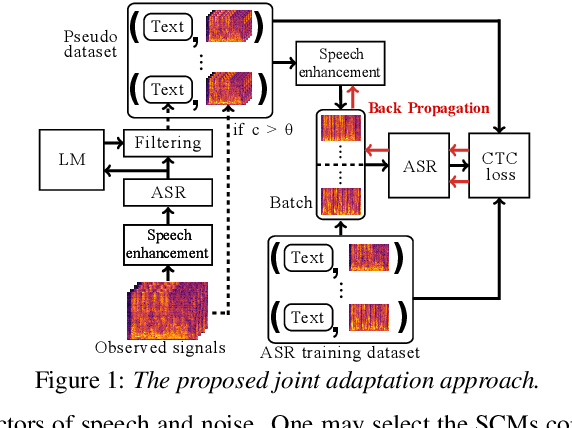
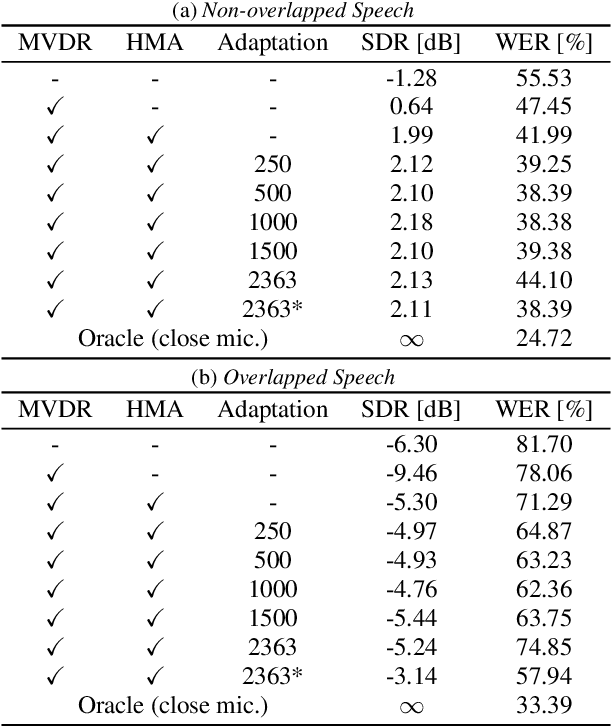
This paper describes noisy speech recognition for an augmented reality headset that helps verbal communication within real multiparty conversational environments. A major approach that has actively been studied in simulated environments is to sequentially perform speech enhancement and automatic speech recognition (ASR) based on deep neural networks (DNNs) trained in a supervised manner. In our task, however, such a pretrained system fails to work due to the mismatch between the training and test conditions and the head movements of the user. To enhance only the utterances of a target speaker, we use beamforming based on a DNN-based speech mask estimator that can adaptively extract the speech components corresponding to a head-relative particular direction. We propose a semi-supervised adaptation method that jointly updates the mask estimator and the ASR model at run-time using clean speech signals with ground-truth transcriptions and noisy speech signals with highly-confident estimated transcriptions. Comparative experiments using the state-of-the-art distant speech recognition system show that the proposed method significantly improves the ASR performance.
A Deep Generative Model of Speech Complex Spectrograms
Mar 08, 2019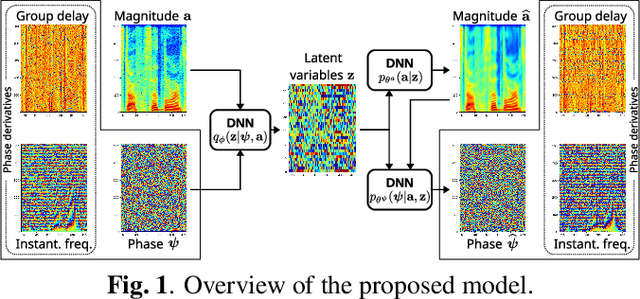

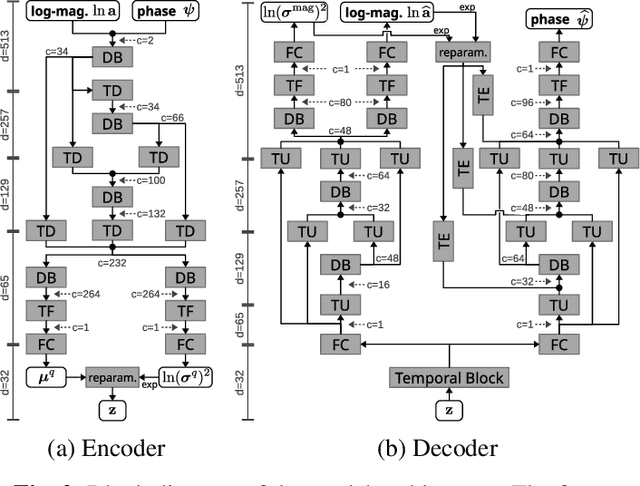

This paper proposes an approach to the joint modeling of the short-time Fourier transform magnitude and phase spectrograms with a deep generative model. We assume that the magnitude follows a Gaussian distribution and the phase follows a von Mises distribution. To improve the consistency of the phase values in the time-frequency domain, we also apply the von Mises distribution to the phase derivatives, i.e., the group delay and the instantaneous frequency. Based on these assumptions, we explore and compare several combinations of loss functions for training our models. Built upon the variational autoencoder framework, our model consists of three convolutional neural networks acting as an encoder, a magnitude decoder, and a phase decoder. In addition to the latent variables, we propose to also condition the phase estimation on the estimated magnitude. Evaluated for a time-domain speech reconstruction task, our models could generate speech with a high perceptual quality and a high intelligibility.
Fast Multichannel Source Separation Based on Jointly Diagonalizable Spatial Covariance Matrices
Mar 08, 2019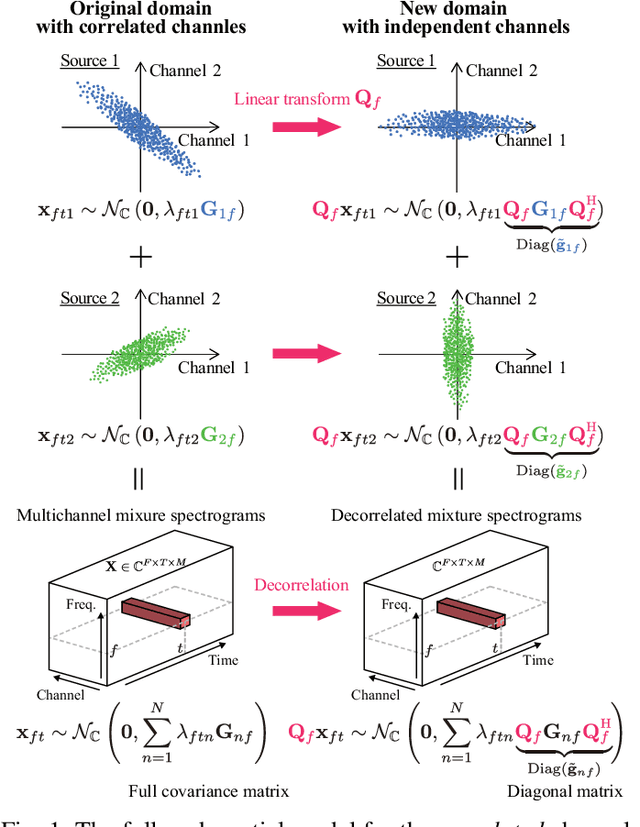
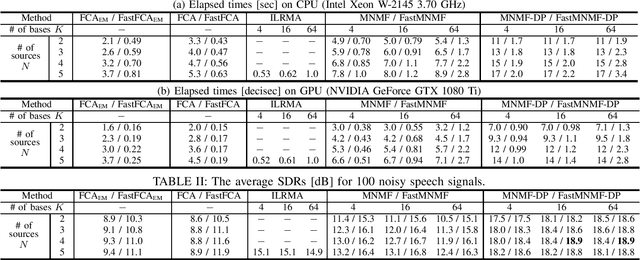
This paper describes a versatile method that accelerates multichannel source separation methods based on full-rank spatial modeling. A popular approach to multichannel source separation is to integrate a spatial model with a source model for estimating the spatial covariance matrices (SCMs) and power spectral densities (PSDs) of each sound source in the time-frequency domain. One of the most successful examples of this approach is multichannel nonnegative matrix factorization (MNMF) based on a full-rank spatial model and a low-rank source model. MNMF, however, is computationally expensive and often works poorly due to the difficulty of estimating the unconstrained full-rank SCMs. Instead of restricting the SCMs to rank-1 matrices with the severe loss of the spatial modeling ability as in independent low-rank matrix analysis (ILRMA), we restrict the SCMs of each frequency bin to jointly-diagonalizable but still full-rank matrices. For such a fast version of MNMF, we propose a computationally-efficient and convergence-guaranteed algorithm that is similar in form to that of ILRMA. Similarly, we propose a fast version of a state-of-the-art speech enhancement method based on a deep speech model and a low-rank noise model. Experimental results showed that the fast versions of MNMF and the deep speech enhancement method were several times faster and performed even better than the original versions of those methods, respectively.