 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirection-Aware Adaptive Online Neural Speech Enhancement with an Augmented Reality Headset in Real Noisy Conversational Environments
Jul 15, 2022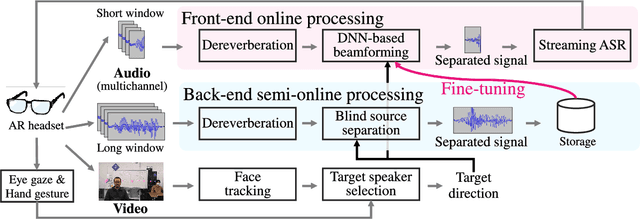

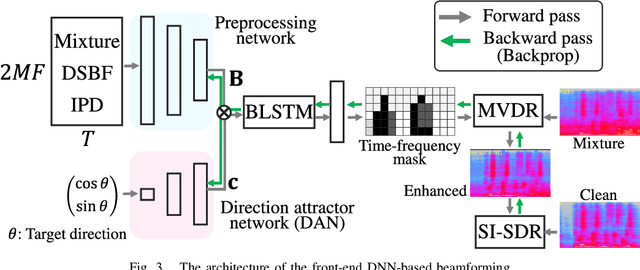
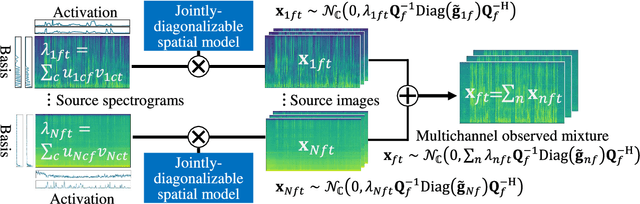
This paper describes the practical response- and performance-aware development of online speech enhancement for an augmented reality (AR) headset that helps a user understand conversations made in real noisy echoic environments (e.g., cocktail party). One may use a state-of-the-art blind source separation method called fast multichannel nonnegative matrix factorization (FastMNMF) that works well in various environments thanks to its unsupervised nature. Its heavy computational cost, however, prevents its application to real-time processing. In contrast, a supervised beamforming method that uses a deep neural network (DNN) for estimating spatial information of speech and noise readily fits real-time processing, but suffers from drastic performance degradation in mismatched conditions. Given such complementary characteristics, we propose a dual-process robust online speech enhancement method based on DNN-based beamforming with FastMNMF-guided adaptation. FastMNMF (back end) is performed in a mini-batch style and the noisy and enhanced speech pairs are used together with the original parallel training data for updating the direction-aware DNN (front end) with backpropagation at a computationally-allowable interval. This method is used with a blind dereverberation method called weighted prediction error (WPE) for transcribing the noisy reverberant speech of a speaker, which can be detected from video or selected by a user's hand gesture or eye gaze, in a streaming manner and spatially showing the transcriptions with an AR technique. Our experiment showed that the word error rate was improved by more than 10 points with the run-time adaptation using only twelve minutes of observation.
Direction-Aware Joint Adaptation of Neural Speech Enhancement and Recognition in Real Multiparty Conversational Environments
Jul 15, 2022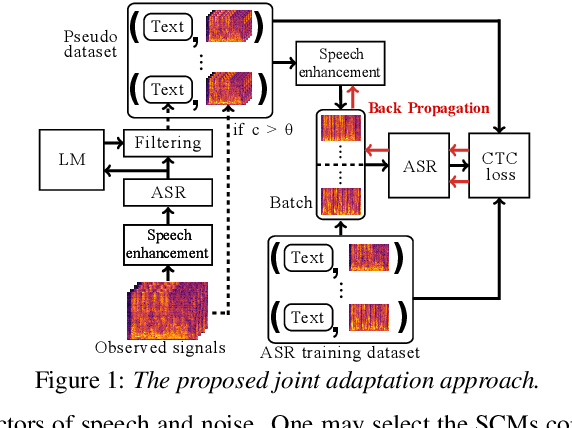
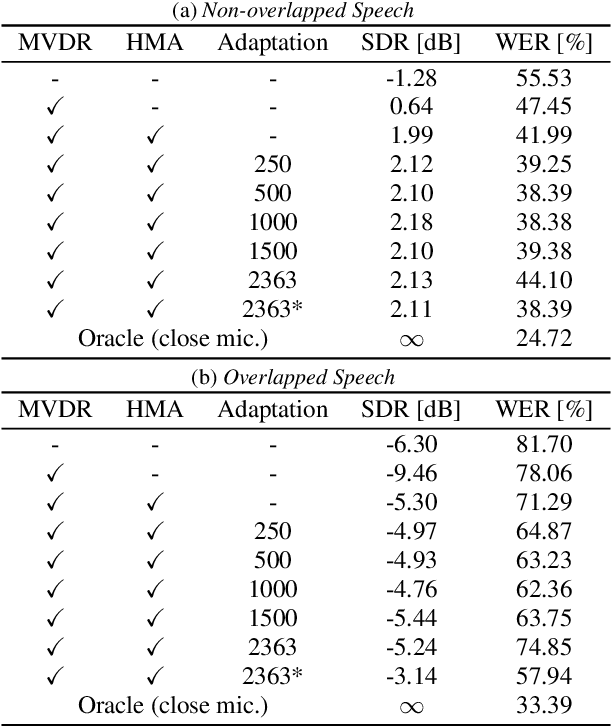
This paper describes noisy speech recognition for an augmented reality headset that helps verbal communication within real multiparty conversational environments. A major approach that has actively been studied in simulated environments is to sequentially perform speech enhancement and automatic speech recognition (ASR) based on deep neural networks (DNNs) trained in a supervised manner. In our task, however, such a pretrained system fails to work due to the mismatch between the training and test conditions and the head movements of the user. To enhance only the utterances of a target speaker, we use beamforming based on a DNN-based speech mask estimator that can adaptively extract the speech components corresponding to a head-relative particular direction. We propose a semi-supervised adaptation method that jointly updates the mask estimator and the ASR model at run-time using clean speech signals with ground-truth transcriptions and noisy speech signals with highly-confident estimated transcriptions. Comparative experiments using the state-of-the-art distant speech recognition system show that the proposed method significantly improves the ASR performance.