 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Knowledge Distillation for Embedding Refinement in Personalized Speech Enhancement
Jan 21, 2026Personalized speech enhancement (PSE) has shown convincing results when it comes to extracting a known target voice among interfering ones. The corresponding systems usually incorporate a representation of the target voice within the enhancement system, which is extracted from an enrollment clip of the target voice with upstream models. Those models are generally heavy as the speaker embedding's quality directly affects PSE performances. Yet, embeddings generated beforehand cannot account for the variations of the target voice during inference time. In this paper, we propose to perform on-thefly refinement of the speaker embedding using a tiny speaker encoder. We first introduce a novel contrastive knowledge distillation methodology in order to train a 150k-parameter encoder from complex embeddings. We then use this encoder within the enhancement system during inference and show that the proposed method greatly improves PSE performances while maintaining a low computational load.
O-EENC-SD: Efficient Online End-to-End Neural Clustering for Speaker Diarization
Dec 17, 2025We introduce O-EENC-SD: an end-to-end online speaker diarization system based on EEND-EDA, featuring a novel RNN-based stitching mechanism for online prediction. In particular, we develop a novel centroid refinement decoder whose usefulness is assessed through a rigorous ablation study. Our system provides key advantages over existing methods: a hyperparameter-free solution compared to unsupervised clustering approaches, and a more efficient alternative to current online end-to-end methods, which are computationally costly. We demonstrate that O-EENC-SD is competitive with the state of the art in the two-speaker conversational telephone speech domain, as tested on the CallHome dataset. Our results show that O-EENC-SD provides a great trade-off between DER and complexity, even when working on independent chunks with no overlap, making the system extremely efficient.
Run-Time Adaptation of Neural Beamforming for Robust Speech Dereverberation and Denoising
Oct 30, 2024This paper describes speech enhancement for realtime automatic speech recognition (ASR) in real environments. A standard approach to this task is to use neural beamforming that can work efficiently in an online manner. It estimates the masks of clean dry speech from a noisy echoic mixture spectrogram with a deep neural network (DNN) and then computes a enhancement filter used for beamforming. The performance of such a supervised approach, however, is drastically degraded under mismatched conditions. This calls for run-time adaptation of the DNN. Although the ground-truth speech spectrogram required for adaptation is not available at run time, blind dereverberation and separation methods such as weighted prediction error (WPE) and fast multichannel nonnegative matrix factorization (FastMNMF) can be used for generating pseudo groundtruth data from a mixture. Based on this idea, a prior work proposed a dual-process system based on a cascade of WPE and minimum variance distortionless response (MVDR) beamforming asynchronously fine-tuned by block-online FastMNMF. To integrate the dereverberation capability into neural beamforming and make it fine-tunable at run time, we propose to use weighted power minimization distortionless response (WPD) beamforming, a unified version of WPE and minimum power distortionless response (MPDR), whose joint dereverberation and denoising filter is estimated using a DNN. We evaluated the impact of run-time adaptation under various conditions with different numbers of speakers, reverberation times, and signal-to-noise ratios (SNRs).
Speech dereverberation constrained on room impulse response characteristics
Jul 10, 2024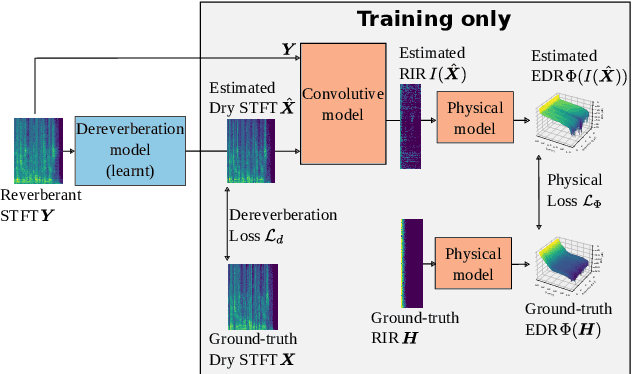
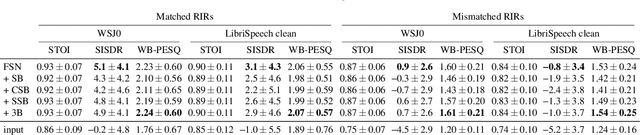
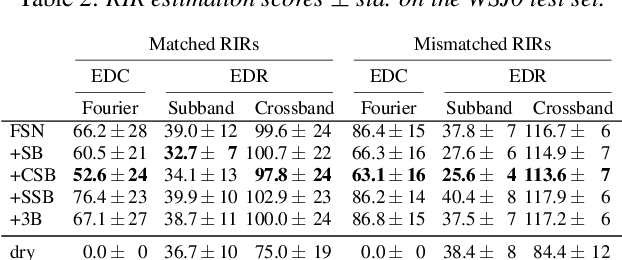
Single-channel speech dereverberation aims at extracting a dry speech signal from a recording affected by the acoustic reflections in a room. However, most current deep learning-based approaches for speech dereverberation are not interpretable for room acoustics, and can be considered as black-box systems in that regard. In this work, we address this problem by regularizing the training loss using a novel physical coherence loss which encourages the room impulse response (RIR) induced by the dereverberated output of the model to match the acoustic properties of the room in which the signal was recorded. Our investigation demonstrates the preservation of the original dereverberated signal alongside the provision of a more physically coherent RIR.
Winner-takes-all learners are geometry-aware conditional density estimators
Jun 07, 2024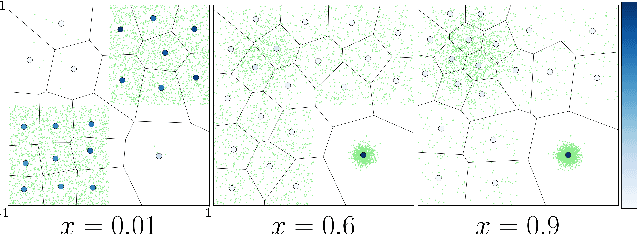
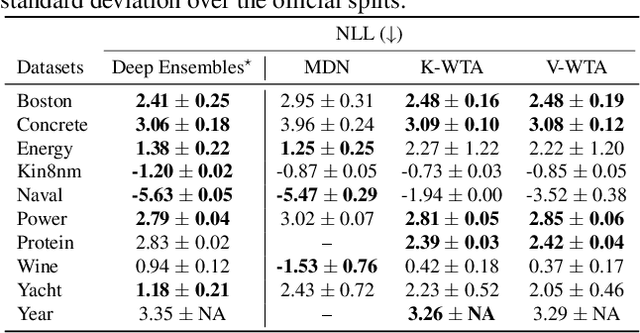
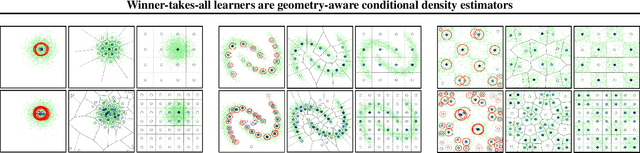
Winner-takes-all training is a simple learning paradigm, which handles ambiguous tasks by predicting a set of plausible hypotheses. Recently, a connection was established between Winner-takes-all training and centroidal Voronoi tessellations, showing that, once trained, hypotheses should quantize optimally the shape of the conditional distribution to predict. However, the best use of these hypotheses for uncertainty quantification is still an open question.In this work, we show how to leverage the appealing geometric properties of the Winner-takes-all learners for conditional density estimation, without modifying its original training scheme. We theoretically establish the advantages of our novel estimator both in terms of quantization and density estimation, and we demonstrate its competitiveness on synthetic and real-world datasets, including audio data.
A lightweight dual-stage framework for personalized speech enhancement based on DeepFilterNet2
Apr 11, 2024Isolating the desired speaker's voice amidst multiplespeakers in a noisy acoustic context is a challenging task. Per-sonalized speech enhancement (PSE) endeavours to achievethis by leveraging prior knowledge of the speaker's voice.Recent research efforts have yielded promising PSE mod-els, albeit often accompanied by computationally intensivearchitectures, unsuitable for resource-constrained embeddeddevices. In this paper, we introduce a novel method to per-sonalize a lightweight dual-stage Speech Enhancement (SE)model and implement it within DeepFilterNet2, a SE modelrenowned for its state-of-the-art performance. We seek anoptimal integration of speaker information within the model,exploring different positions for the integration of the speakerembeddings within the dual-stage enhancement architec-ture. We also investigate a tailored training strategy whenadapting DeepFilterNet2 to a PSE task. We show that ourpersonalization method greatly improves the performancesof DeepFilterNet2 while preserving minimal computationaloverhead.
* Accepted at HSCMA24, Satellite workshop of ICASSP24
GLA-Grad: A Griffin-Lim Extended Waveform Generation Diffusion Model
Feb 09, 2024Diffusion models are receiving a growing interest for a variety of signal generation tasks such as speech or music synthesis. WaveGrad, for example, is a successful diffusion model that conditionally uses the mel spectrogram to guide a diffusion process for the generation of high-fidelity audio. However, such models face important challenges concerning the noise diffusion process for training and inference, and they have difficulty generating high-quality speech for speakers that were not seen during training. With the aim of minimizing the conditioning error and increasing the efficiency of the noise diffusion process, we propose in this paper a new scheme called GLA-Grad, which consists in introducing a phase recovery algorithm such as the Griffin-Lim algorithm (GLA) at each step of the regular diffusion process. Furthermore, it can be directly applied to an already-trained waveform generation model, without additional training or fine-tuning. We show that our algorithm outperforms state-of-the-art diffusion models for speech generation, especially when generating speech for a previously unseen target speaker.
* Accepted at ICASSP 2024
SpecDiff-GAN: A Spectrally-Shaped Noise Diffusion GAN for Speech and Music Synthesis
Jan 30, 2024Generative adversarial network (GAN) models can synthesize highquality audio signals while ensuring fast sample generation. However, they are difficult to train and are prone to several issues including mode collapse and divergence. In this paper, we introduce SpecDiff-GAN, a neural vocoder based on HiFi-GAN, which was initially devised for speech synthesis from mel spectrogram. In our model, the training stability is enhanced by means of a forward diffusion process which consists in injecting noise from a Gaussian distribution to both real and fake samples before inputting them to the discriminator. We further improve the model by exploiting a spectrally-shaped noise distribution with the aim to make the discriminator's task more challenging. We then show the merits of our proposed model for speech and music synthesis on several datasets. Our experiments confirm that our model compares favorably in audio quality and efficiency compared to several baselines.
* Accepted at ICASSP 2024
Online speaker diarization of meetings guided by speech separation
Jan 30, 2024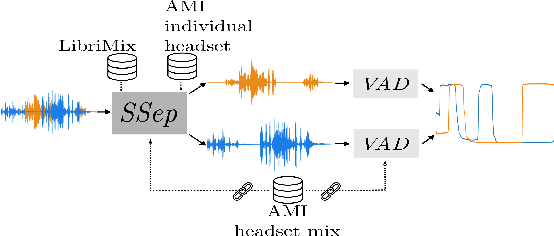
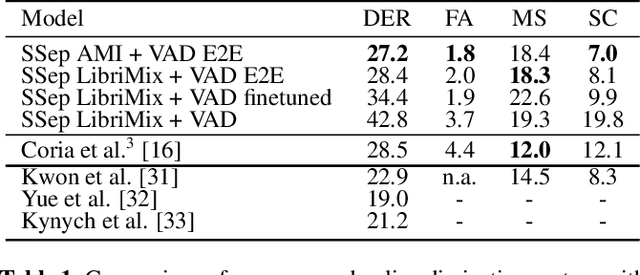
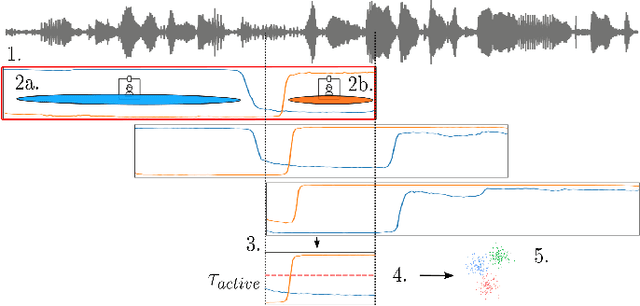
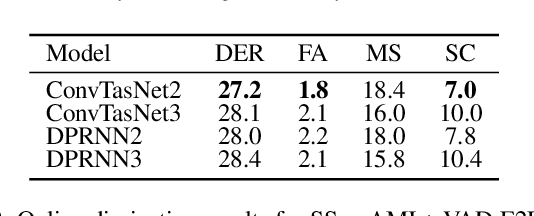
Overlapped speech is notoriously problematic for speaker diarization systems. Consequently, the use of speech separation has recently been proposed to improve their performance. Although promising, speech separation models struggle with realistic data because they are trained on simulated mixtures with a fixed number of speakers. In this work, we introduce a new speech separation-guided diarization scheme suitable for the online speaker diarization of long meeting recordings with a variable number of speakers, as present in the AMI corpus. We envisage ConvTasNet and DPRNN as alternatives for the separation networks, with two or three output sources. To obtain the speaker diarization result, voice activity detection is applied on each estimated source. The final model is fine-tuned end-to-end, after first adapting the separation to real data using AMI. The system operates on short segments, and inference is performed by stitching the local predictions using speaker embeddings and incremental clustering. The results show that our system improves the state-of-the-art on the AMI headset mix, using no oracle information and under full evaluation (no collar and including overlapped speech). Finally, we show the strength of our system particularly on overlapped speech sections.
* Accepted at ICASSP 2024
Resilient Multiple Choice Learning: A learned scoring scheme with application to audio scene analysis
Nov 16, 2023We introduce Resilient Multiple Choice Learning (rMCL), an extension of the MCL approach for conditional distribution estimation in regression settings where multiple targets may be sampled for each training input. Multiple Choice Learning is a simple framework to tackle multimodal density estimation, using the Winner-Takes-All (WTA) loss for a set of hypotheses. In regression settings, the existing MCL variants focus on merging the hypotheses, thereby eventually sacrificing the diversity of the predictions. In contrast, our method relies on a novel learned scoring scheme underpinned by a mathematical framework based on Voronoi tessellations of the output space, from which we can derive a probabilistic interpretation. After empirically validating rMCL with experiments on synthetic data, we further assess its merits on the sound source localization problem, demonstrating its practical usefulness and the relevance of its interpretation.