 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS-PRESSO: Ultra Low Bitrate Sound Effect Compression With Diffusion Autoencoders And Offline Quantization
Feb 16, 2026Neural audio compression models have recently achieved extreme compression rates, enabling efficient latent generative modeling. Conversely, latent generative models have been applied to compression, pushing the limits of continuous and discrete approaches. However, existing methods remain constrained to low-resolution audio and degrade substantially at very low bitrates, where audible artifacts are prominent. In this paper, we present S-PRESSO, a 48kHz sound effect compression model that produces both continuous and discrete embeddings at ultra-low bitrates, down to 0.096 kbps, via offline quantization. Our model relies on a pretrained latent diffusion model to decode compressed audio embeddings learned by a latent encoder. Leveraging the generative priors of the diffusion decoder, we achieve extremely low frame rates, down to 1Hz (750x compression rate), producing convincing and realistic reconstructions at the cost of exact fidelity. Despite operating at high compression rates, we demonstrate that S-PRESSO outperforms both continuous and discrete baselines in audio quality, acoustic similarity and reconstruction metrics.
Melody-Lyrics Matching with Contrastive Alignment Loss
Jul 31, 2025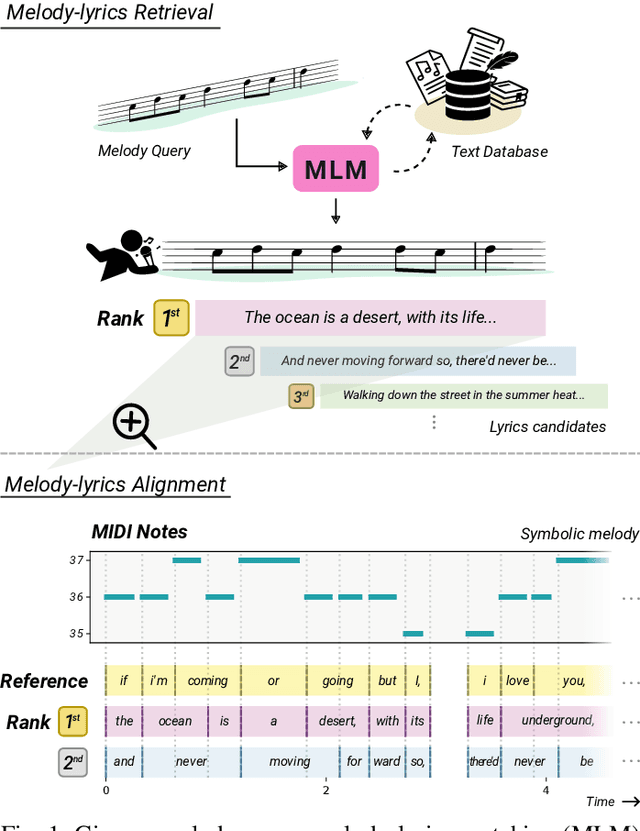
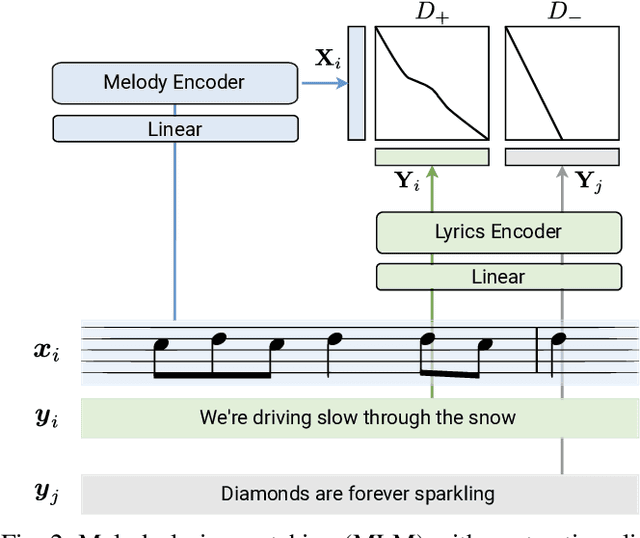
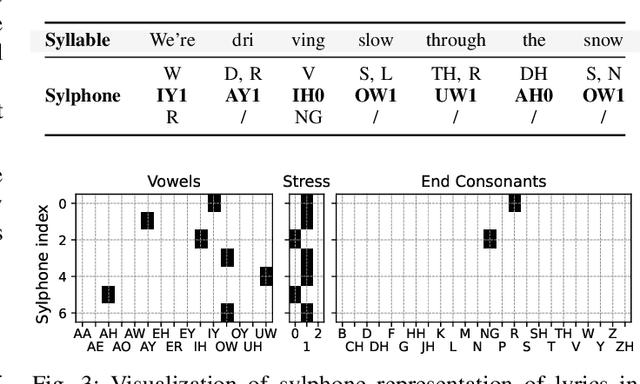
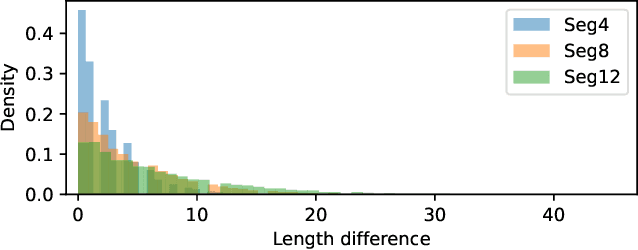
The connection between music and lyrics is far beyond semantic bonds. Conceptual pairs in the two modalities such as rhythm and rhyme, note duration and syllabic stress, and structure correspondence, raise a compelling yet seldom-explored direction in the field of music information retrieval. In this paper, we present melody-lyrics matching (MLM), a new task which retrieves potential lyrics for a given symbolic melody from text sources. Rather than generating lyrics from scratch, MLM essentially exploits the relationships between melody and lyrics. We propose a self-supervised representation learning framework with contrastive alignment loss for melody and lyrics. This has the potential to leverage the abundance of existing songs with paired melody and lyrics. No alignment annotations are required. Additionally, we introduce sylphone, a novel representation for lyrics at syllable-level activated by phoneme identity and vowel stress. We demonstrate that our method can match melody with coherent and singable lyrics with empirical results and intuitive examples. We open source code and provide matching examples on the companion webpage: https://github.com/changhongw/mlm.
Diff-TONE: Timestep Optimization for iNstrument Editing in Text-to-Music Diffusion Models
Jun 18, 2025Breakthroughs in text-to-music generation models are transforming the creative landscape, equipping musicians with innovative tools for composition and experimentation like never before. However, controlling the generation process to achieve a specific desired outcome remains a significant challenge. Even a minor change in the text prompt, combined with the same random seed, can drastically alter the generated piece. In this paper, we explore the application of existing text-to-music diffusion models for instrument editing. Specifically, for an existing audio track, we aim to leverage a pretrained text-to-music diffusion model to edit the instrument while preserving the underlying content. Based on the insight that the model first focuses on the overall structure or content of the audio, then adds instrument information, and finally refines the quality, we show that selecting a well-chosen intermediate timestep, identified through an instrument classifier, yields a balance between preserving the original piece's content and achieving the desired timbre. Our method does not require additional training of the text-to-music diffusion model, nor does it compromise the generation process's speed.
AnCoGen: Analysis, Control and Generation of Speech with a Masked Autoencoder
Jan 09, 2025This article introduces AnCoGen, a novel method that leverages a masked autoencoder to unify the analysis, control, and generation of speech signals within a single model. AnCoGen can analyze speech by estimating key attributes, such as speaker identity, pitch, content, loudness, signal-to-noise ratio, and clarity index. In addition, it can generate speech from these attributes and allow precise control of the synthesized speech by modifying them. Extensive experiments demonstrated the effectiveness of AnCoGen across speech analysis-resynthesis, pitch estimation, pitch modification, and speech enhancement.
Multiple Choice Learning for Efficient Speech Separation with Many Speakers
Nov 27, 2024Training speech separation models in the supervised setting raises a permutation problem: finding the best assignation between the model predictions and the ground truth separated signals. This inherently ambiguous task is customarily solved using Permutation Invariant Training (PIT). In this article, we instead consider using the Multiple Choice Learning (MCL) framework, which was originally introduced to tackle ambiguous tasks. We demonstrate experimentally on the popular WSJ0-mix and LibriMix benchmarks that MCL matches the performances of PIT, while being computationally advantageous. This opens the door to a promising research direction, as MCL can be naturally extended to handle a variable number of speakers, or to tackle speech separation in the unsupervised setting.
Episodic fine-tuning prototypical networks for optimization-based few-shot learning: Application to audio classification
Oct 04, 2024The Prototypical Network (ProtoNet) has emerged as a popular choice in Few-shot Learning (FSL) scenarios due to its remarkable performance and straightforward implementation. Building upon such success, we first propose a simple (yet novel) method to fine-tune a ProtoNet on the (labeled) support set of the test episode of a C-way-K-shot test episode (without using the query set which is only used for evaluation). We then propose an algorithmic framework that combines ProtoNet with optimization-based FSL algorithms (MAML and Meta-Curvature) to work with such a fine-tuning method. Since optimization-based algorithms endow the target learner model with the ability to fast adaption to only a few samples, we utilize ProtoNet as the target model to enhance its fine-tuning performance with the help of a specifically designed episodic fine-tuning strategy. The experimental results confirm that our proposed models, MAML-Proto and MC-Proto, combined with our unique fine-tuning method, outperform regular ProtoNet by a large margin in few-shot audio classification tasks on the ESC-50 and Speech Commands v2 datasets. We note that although we have only applied our model to the audio domain, it is a general method and can be easily extended to other domains.
* Accepted at MLSP 2024
Using Random Codebooks for Audio Neural AutoEncoders
Sep 25, 2024



Latent representation learning has been an active field of study for decades in numerous applications. Inspired among others by the tokenization from Natural Language Processing and motivated by the research of a simple data representation, recent works have introduced a quantization step into the feature extraction. In this work, we propose a novel strategy to build the neural discrete representation by means of random codebooks. These codebooks are obtained by randomly sampling a large, predefined fixed codebook. We experimentally show the merits and potential of our approach in a task of audio compression and reconstruction.
Learning Source Disentanglement in Neural Audio Codec
Sep 17, 2024



Neural audio codecs have significantly advanced audio compression by efficiently converting continuous audio signals into discrete tokens. These codecs preserve high-quality sound and enable sophisticated sound generation through generative models trained on these tokens. However, existing neural codec models are typically trained on large, undifferentiated audio datasets, neglecting the essential discrepancies between sound domains like speech, music, and environmental sound effects. This oversight complicates data modeling and poses additional challenges to the controllability of sound generation. To tackle these issues, we introduce the Source-Disentangled Neural Audio Codec (SD-Codec), a novel approach that combines audio coding and source separation. By jointly learning audio resynthesis and separation, SD-Codec explicitly assigns audio signals from different domains to distinct codebooks, sets of discrete representations. Experimental results indicate that SD-Codec not only maintains competitive resynthesis quality but also, supported by the separation results, demonstrates successful disentanglement of different sources in the latent space, thereby enhancing interpretability in audio codec and providing potential finer control over the audio generation process.
Annealed Multiple Choice Learning: Overcoming limitations of Winner-takes-all with annealing
Jul 22, 2024



We introduce Annealed Multiple Choice Learning (aMCL) which combines simulated annealing with MCL. MCL is a learning framework handling ambiguous tasks by predicting a small set of plausible hypotheses. These hypotheses are trained using the Winner-takes-all (WTA) scheme, which promotes the diversity of the predictions. However, this scheme may converge toward an arbitrarily suboptimal local minimum, due to the greedy nature of WTA. We overcome this limitation using annealing, which enhances the exploration of the hypothesis space during training. We leverage insights from statistical physics and information theory to provide a detailed description of the model training trajectory. Additionally, we validate our algorithm by extensive experiments on synthetic datasets, on the standard UCI benchmark, and on speech separation.
Speech dereverberation constrained on room impulse response characteristics
Jul 10, 2024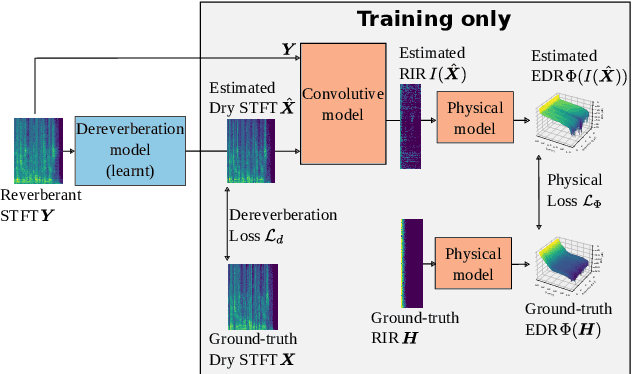
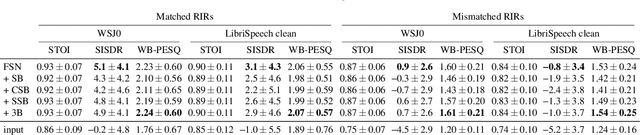
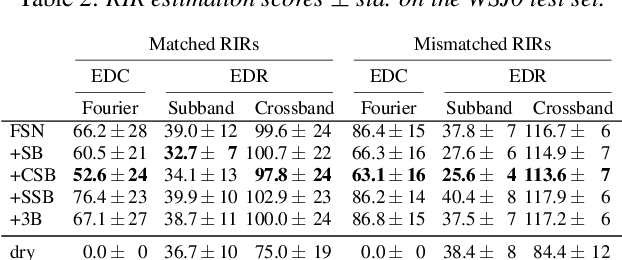
Single-channel speech dereverberation aims at extracting a dry speech signal from a recording affected by the acoustic reflections in a room. However, most current deep learning-based approaches for speech dereverberation are not interpretable for room acoustics, and can be considered as black-box systems in that regard. In this work, we address this problem by regularizing the training loss using a novel physical coherence loss which encourages the room impulse response (RIR) induced by the dereverberated output of the model to match the acoustic properties of the room in which the signal was recorded. Our investigation demonstrates the preservation of the original dereverberated signal alongside the provision of a more physically coherent RIR.