 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple Choice Learning for Efficient Speech Separation with Many Speakers
Nov 27, 2024Training speech separation models in the supervised setting raises a permutation problem: finding the best assignation between the model predictions and the ground truth separated signals. This inherently ambiguous task is customarily solved using Permutation Invariant Training (PIT). In this article, we instead consider using the Multiple Choice Learning (MCL) framework, which was originally introduced to tackle ambiguous tasks. We demonstrate experimentally on the popular WSJ0-mix and LibriMix benchmarks that MCL matches the performances of PIT, while being computationally advantageous. This opens the door to a promising research direction, as MCL can be naturally extended to handle a variable number of speakers, or to tackle speech separation in the unsupervised setting.
Annealed Multiple Choice Learning: Overcoming limitations of Winner-takes-all with annealing
Jul 22, 2024



We introduce Annealed Multiple Choice Learning (aMCL) which combines simulated annealing with MCL. MCL is a learning framework handling ambiguous tasks by predicting a small set of plausible hypotheses. These hypotheses are trained using the Winner-takes-all (WTA) scheme, which promotes the diversity of the predictions. However, this scheme may converge toward an arbitrarily suboptimal local minimum, due to the greedy nature of WTA. We overcome this limitation using annealing, which enhances the exploration of the hypothesis space during training. We leverage insights from statistical physics and information theory to provide a detailed description of the model training trajectory. Additionally, we validate our algorithm by extensive experiments on synthetic datasets, on the standard UCI benchmark, and on speech separation.
Predefined Prototypes for Intra-Class Separation and Disentanglement
Jun 23, 2024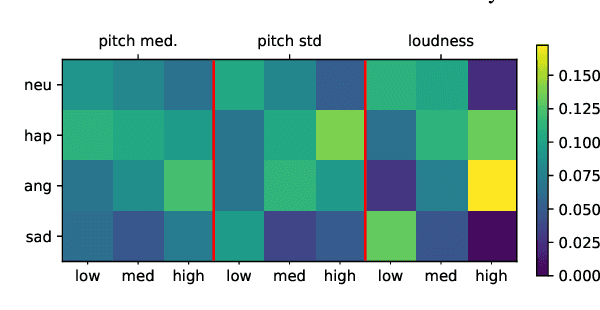
Prototypical Learning is based on the idea that there is a point (which we call prototype) around which the embeddings of a class are clustered. It has shown promising results in scenarios with little labeled data or to design explainable models. Typically, prototypes are either defined as the average of the embeddings of a class or are designed to be trainable. In this work, we propose to predefine prototypes following human-specified criteria, which simplify the training pipeline and brings different advantages. Specifically, in this work we explore two of these advantages: increasing the inter-class separability of embeddings and disentangling embeddings with respect to different variance factors, which can translate into the possibility of having explainable predictions. Finally, we propose different experiments that help to understand our proposal and demonstrate empirically the mentioned advantages.
Explainable by-design Audio Segmentation through Non-Negative Matrix Factorization and Probing
Jun 19, 2024
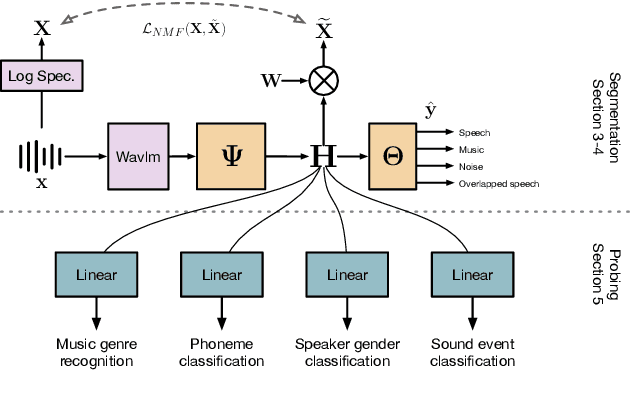
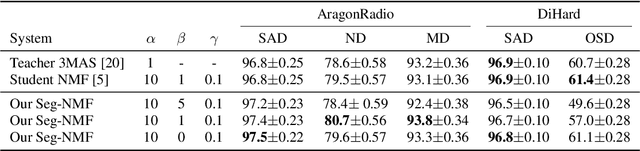
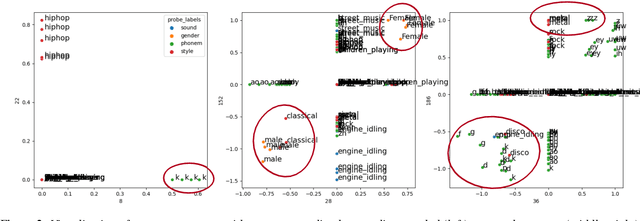
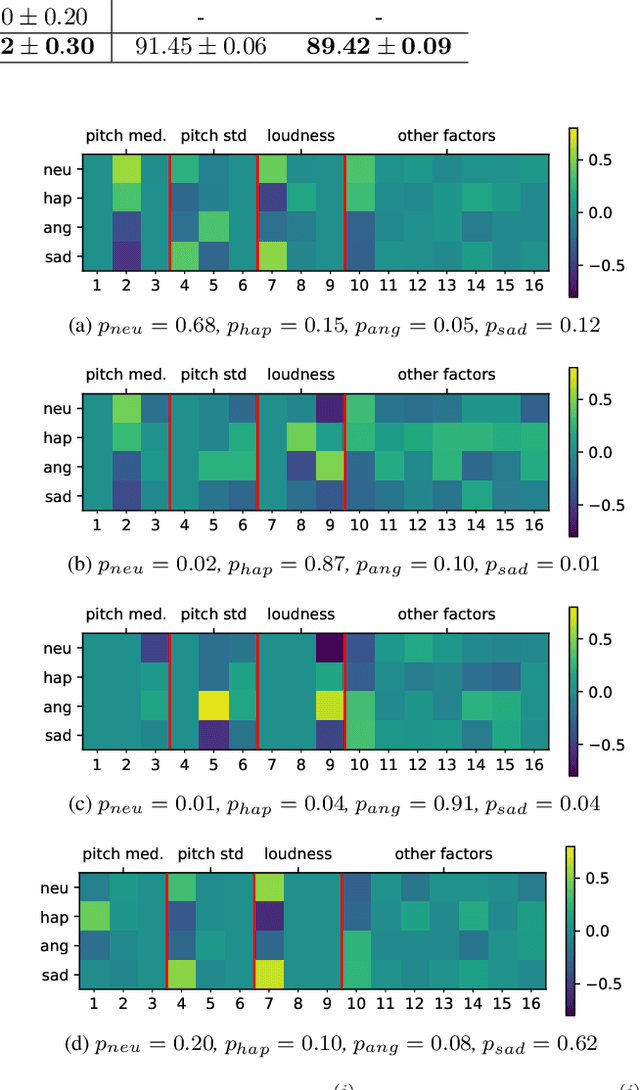
Audio segmentation is a key task for many speech technologies, most of which are based on neural networks, usually considered as black boxes, with high-level performances. However, in many domains, among which health or forensics, there is not only a need for good performance but also for explanations about the output decision. Explanations derived directly from latent representations need to satisfy "good" properties, such as informativeness, compactness, or modularity, to be interpretable. In this article, we propose an explainable-by-design audio segmentation model based on non-negative matrix factorization (NMF) which is a good candidate for the design of interpretable representations. This paper shows that our model reaches good segmentation performances, and presents deep analyses of the latent representation extracted from the non-negative matrix. The proposed approach opens new perspectives toward the evaluation of interpretable representations according to "good" properties.
Channel-Combination Algorithms for Robust Distant Voice Activity and Overlapped Speech Detection
Feb 13, 2024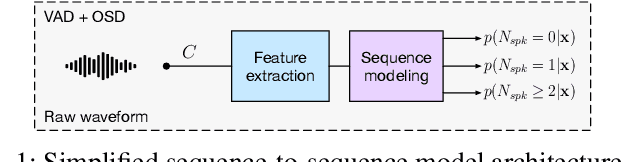
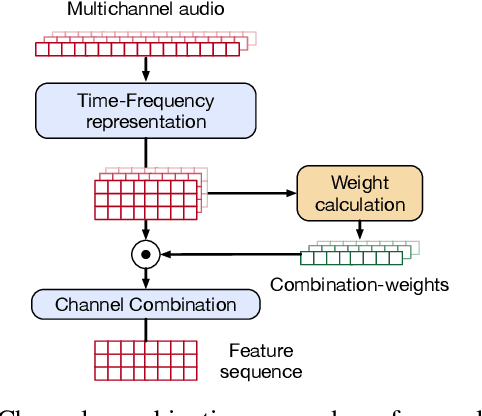
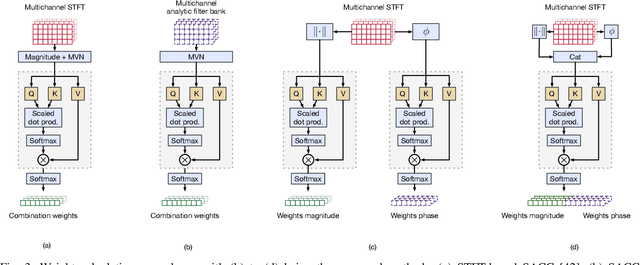

Voice Activity Detection (VAD) and Overlapped Speech Detection (OSD) are key pre-processing tasks for speaker diarization. In the meeting context, it is often easier to capture speech with a distant device. This consideration however leads to severe performance degradation. We study a unified supervised learning framework to solve distant multi-microphone joint VAD and OSD (VAD+OSD). This paper investigates various multi-channel VAD+OSD front-ends that weight and combine incoming channels. We propose three algorithms based on the Self-Attention Channel Combinator (SACC), previously proposed in the literature. Experiments conducted on the AMI meeting corpus exhibit that channel combination approaches bring significant VAD+OSD improvements in the distant speech scenario. Specifically, we explore the use of learned complex combination weights and demonstrate the benefits of such an approach in terms of explainability. Channel combination-based VAD+OSD systems are evaluated on the final back-end task, i.e. speaker diarization, and show significant improvements. Finally, since multi-channel systems are trained given a fixed array configuration, they may fail in generalizing to other array set-ups, e.g. mismatched number of microphones. A channel-number invariant loss is proposed to learn a unique feature representation regardless of the number of available microphones. The evaluation conducted on mismatched array configurations highlights the robustness of this training strategy.
Unsupervised Multiple Domain Translation through Controlled Disentanglement in Variational Autoencoder
Jan 18, 2024



Unsupervised Multiple Domain Translation is the task of transforming data from one domain to other domains without having paired data to train the systems. Typically, methods based on Generative Adversarial Networks (GANs) are used to address this task. However, our proposal exclusively relies on a modified version of a Variational Autoencoder. This modification consists of the use of two latent variables disentangled in a controlled way by design. One of this latent variables is imposed to depend exclusively on the domain, while the other one must depend on the rest of the variability factors of the data. Additionally, the conditions imposed over the domain latent variable allow for better control and understanding of the latent space. We empirically demonstrate that our approach works on different vision datasets improving the performance of other well known methods. Finally, we prove that, indeed, one of the latent variables stores all the information related to the domain and the other one hardly contains any domain information.
An Explainable Proxy Model for Multiabel Audio Segmentation
Jan 17, 2024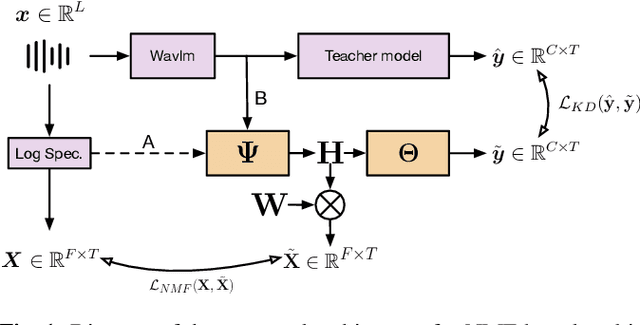
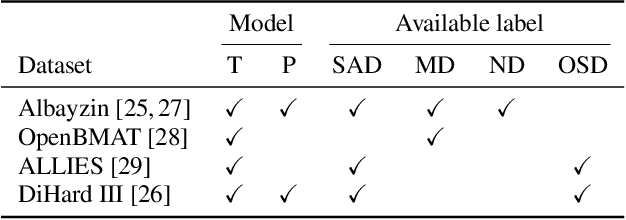
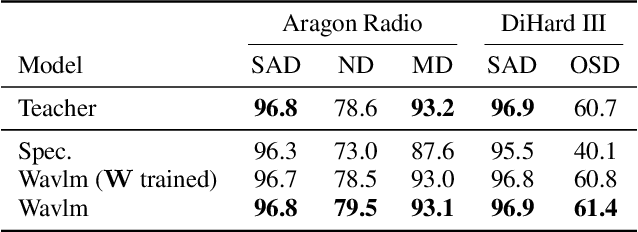
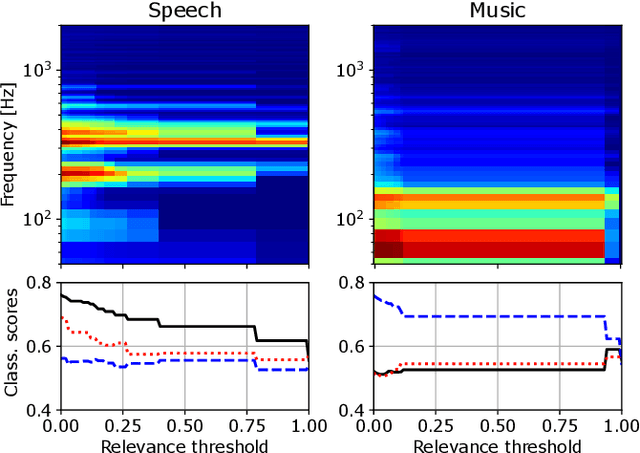
Audio signal segmentation is a key task for automatic audio indexing. It consists of detecting the boundaries of class-homogeneous segments in the signal. In many applications, explainable AI is a vital process for transparency of decision-making with machine learning. In this paper, we propose an explainable multilabel segmentation model that solves speech activity (SAD), music (MD), noise (ND), and overlapped speech detection (OSD) simultaneously. This proxy uses the non-negative matrix factorization (NMF) to map the embedding used for the segmentation to the frequency domain. Experiments conducted on two datasets show similar performances as the pre-trained black box model while showing strong explainability features. Specifically, the frequency bins used for the decision can be easily identified at both the segment level (local explanations) and global level (class prototypes).
Joint speech and overlap detection: a benchmark over multiple audio setup and speech domains
Jul 24, 2023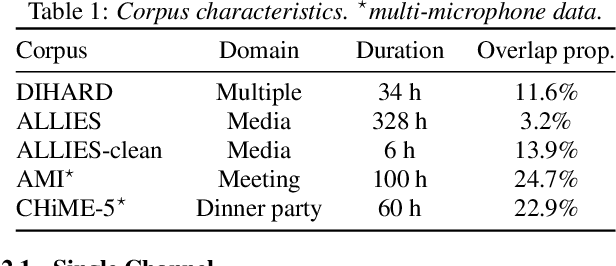
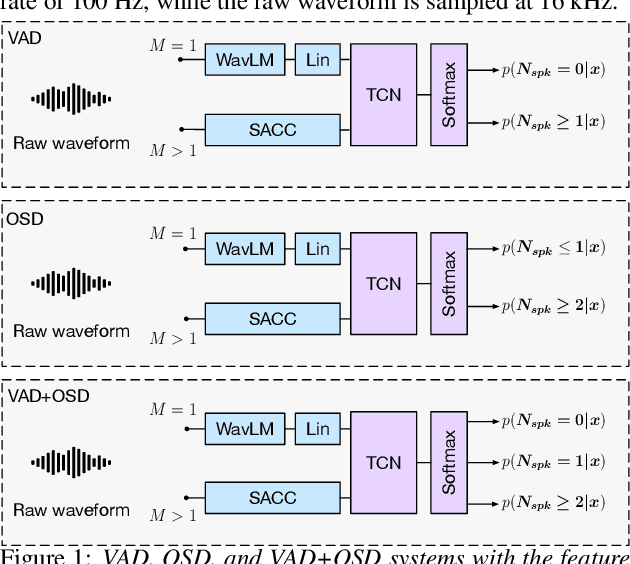

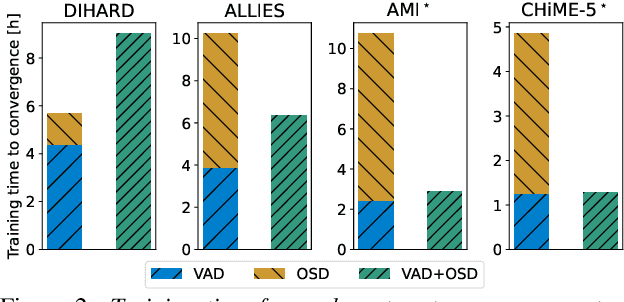
Voice activity and overlapped speech detection (respectively VAD and OSD) are key pre-processing tasks for speaker diarization. The final segmentation performance highly relies on the robustness of these sub-tasks. Recent studies have shown VAD and OSD can be trained jointly using a multi-class classification model. However, these works are often restricted to a specific speech domain, lacking information about the generalization capacities of the systems. This paper proposes a complete and new benchmark of different VAD and OSD models, on multiple audio setups (single/multi-channel) and speech domains (e.g. media, meeting...). Our 2/3-class systems, which combine a Temporal Convolutional Network with speech representations adapted to the setup, outperform state-of-the-art results. We show that the joint training of these two tasks offers similar performances in terms of F1-score to two dedicated VAD and OSD systems while reducing the training cost. This unique architecture can also be used for single and multichannel speech processing.
Multi-microphone Automatic Speech Segmentation in Meetings Based on Circular Harmonics Features
Jun 07, 2023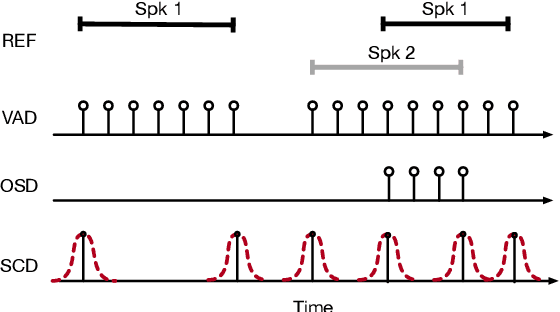
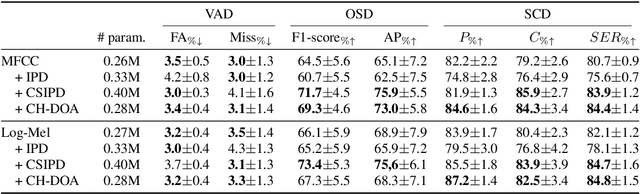
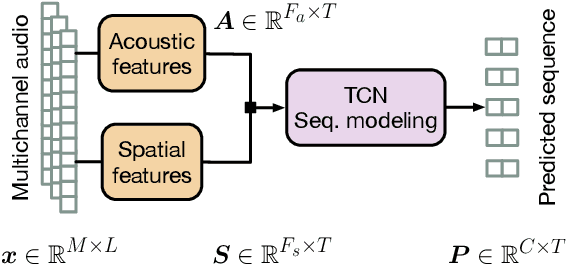
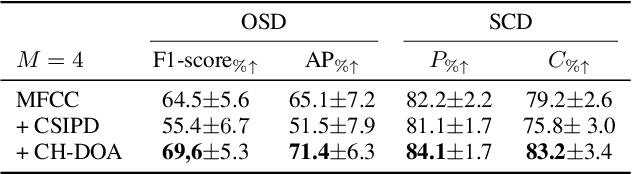
Speaker diarization is the task of answering Who spoke and when? in an audio stream. Pipeline systems rely on speech segmentation to extract speakers' segments and achieve robust speaker diarization. This paper proposes a common framework to solve three segmentation tasks in the distant speech scenario: Voice Activity Detection (VAD), Overlapped Speech Detection (OSD), and Speaker Change Detection (SCD). In the literature, a few studies investigate the multi-microphone distant speech scenario. In this work, we propose a new set of spatial features based on direction-of-arrival estimations in the circular harmonic domain (CH-DOA). These spatial features are extracted from multi-microphone audio data and combined with standard acoustic features. Experiments on the AMI meeting corpus show that CH-DOA can improve the segmentation while being robust in the case of deactivated microphones.