 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Visual Speaker Diarization: Current Databases, Approaches and Challenges
Sep 09, 2024Nowadays, the large amount of audio-visual content available has fostered the need to develop new robust automatic speaker diarization systems to analyse and characterise it. This kind of system helps to reduce the cost of doing this process manually and allows the use of the speaker information for different applications, as a huge quantity of information is present, for example, images of faces, or audio recordings. Therefore, this paper aims to address a critical area in the field of speaker diarization systems, the integration of audio-visual content of different domains. This paper seeks to push beyond current state-of-the-art practices by developing a robust audio-visual speaker diarization framework adaptable to various data domains, including TV scenarios, meetings, and daily activities. Unlike most of the existing audio-visual speaker diarization systems, this framework will also include the proposal of an approach to lead the precise assignment of specific identities in TV scenarios where celebrities appear. In addition, in this work, we have conducted an extensive compilation of the current state-of-the-art approaches and the existing databases for developing audio-visual speaker diarization.
Defining and Measuring Disentanglement for non-Independent Factors of Variation
Aug 13, 2024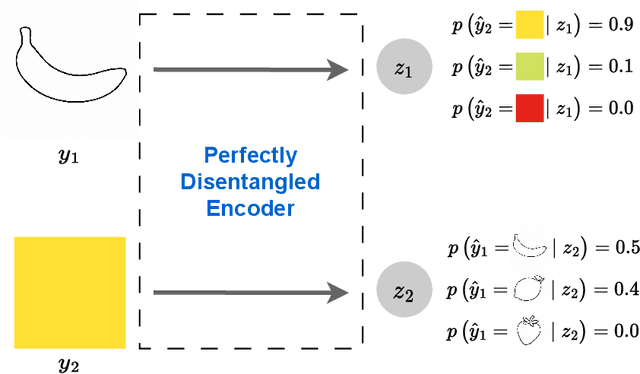
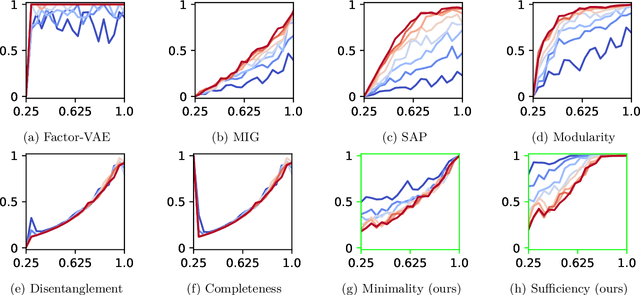

Representation learning is an approach that allows to discover and extract the factors of variation from the data. Intuitively, a representation is said to be disentangled if it separates the different factors of variation in a way that is understandable to humans. Definitions of disentanglement and metrics to measure it usually assume that the factors of variation are independent of each other. However, this is generally false in the real world, which limits the use of these definitions and metrics to very specific and unrealistic scenarios. In this paper we give a definition of disentanglement based on information theory that is also valid when the factors of variation are not independent. Furthermore, we relate this definition to the Information Bottleneck Method. Finally, we propose a method to measure the degree of disentanglement from the given definition that works when the factors of variation are not independent. We show through different experiments that the method proposed in this paper correctly measures disentanglement with non-independent factors of variation, while other methods fail in this scenario.
Predefined Prototypes for Intra-Class Separation and Disentanglement
Jun 23, 2024
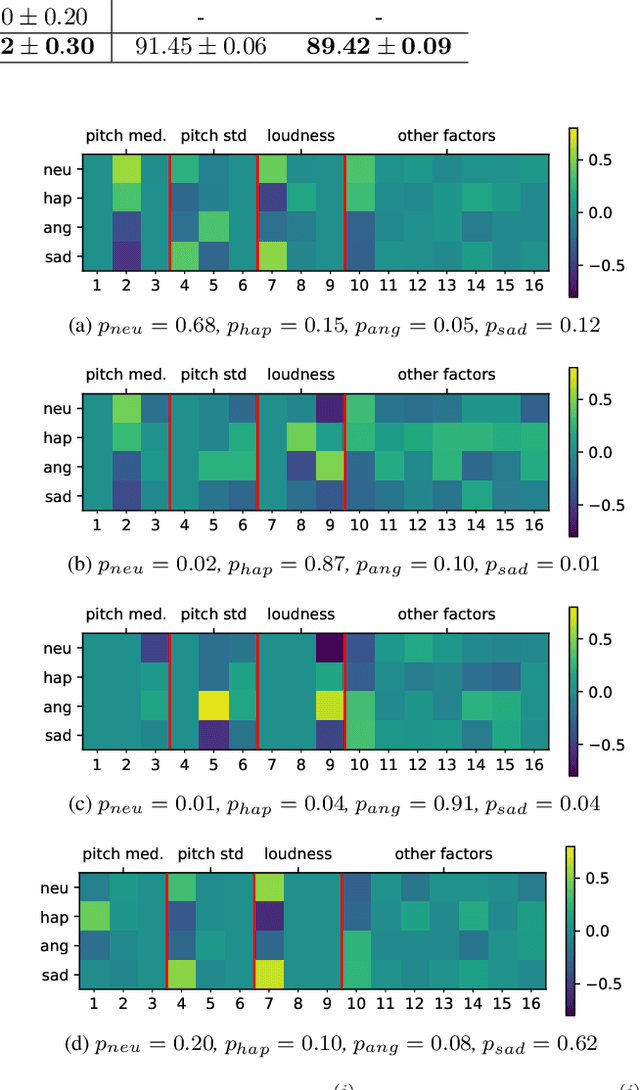
Prototypical Learning is based on the idea that there is a point (which we call prototype) around which the embeddings of a class are clustered. It has shown promising results in scenarios with little labeled data or to design explainable models. Typically, prototypes are either defined as the average of the embeddings of a class or are designed to be trainable. In this work, we propose to predefine prototypes following human-specified criteria, which simplify the training pipeline and brings different advantages. Specifically, in this work we explore two of these advantages: increasing the inter-class separability of embeddings and disentangling embeddings with respect to different variance factors, which can translate into the possibility of having explainable predictions. Finally, we propose different experiments that help to understand our proposal and demonstrate empirically the mentioned advantages.
Improved Vocal Effort Transfer Vector Estimation for Vocal Effort-Robust Speaker Verification
May 03, 2023



Despite the maturity of modern speaker verification technology, its performance still significantly degrades when facing non-neutrally-phonated (e.g., shouted and whispered) speech. To address this issue, in this paper, we propose a new speaker embedding compensation method based on a minimum mean square error (MMSE) estimator. This method models the joint distribution of the vocal effort transfer vector and non-neutrally-phonated embedding spaces and operates in a principal component analysis domain to cope with non-neutrally-phonated speech data scarcity. Experiments are carried out using a cutting-edge speaker verification system integrating a powerful self-supervised pre-trained model for speech representation. In comparison with a state-of-the-art embedding compensation method, the proposed MMSE estimator yields superior and competitive equal error rate results when tackling shouted and whispered speech, respectively.
Class Token and Knowledge Distillation for Multi-head Self-Attention Speaker Verification Systems
Nov 06, 2021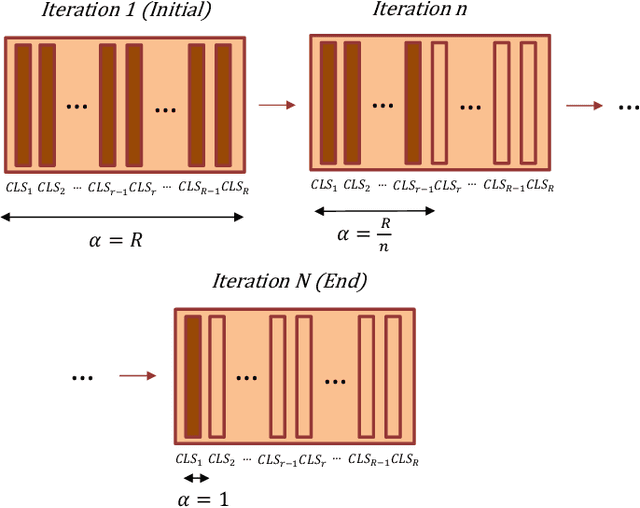
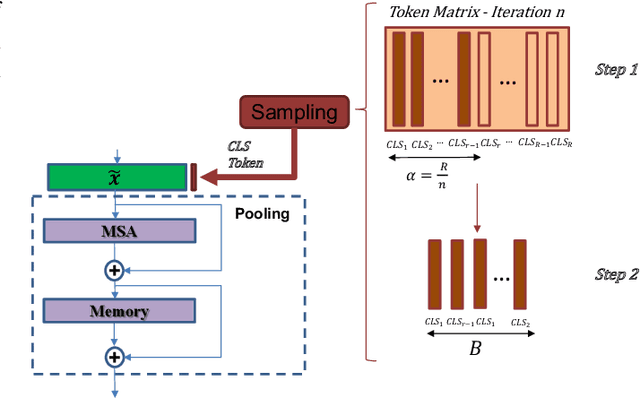
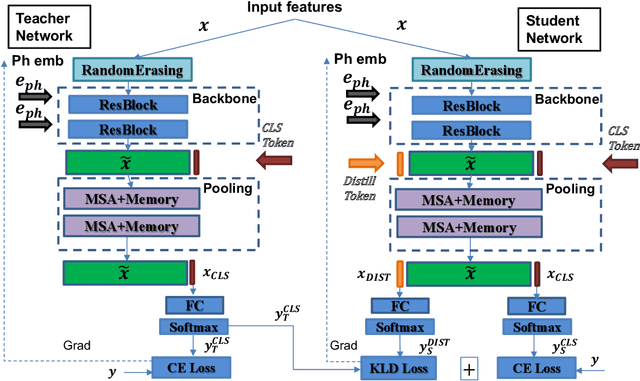
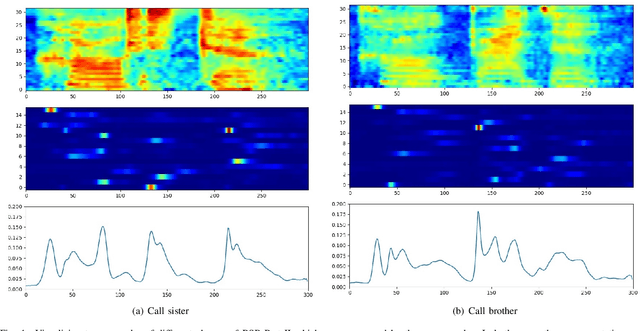
This paper explores three novel approaches to improve the performance of speaker verification (SV) systems based on deep neural networks (DNN) using Multi-head Self-Attention (MSA) mechanisms and memory layers. Firstly, we propose the use of a learnable vector called Class token to replace the average global pooling mechanism to extract the embeddings. Unlike global average pooling, our proposal takes into account the temporal structure of the input what is relevant for the text-dependent SV task. The class token is concatenated to the input before the first MSA layer, and its state at the output is used to predict the classes. To gain additional robustness, we introduce two approaches. First, we have developed a Bayesian estimation of the class token. Second, we have added a distilled representation token for training a teacher-student pair of networks using the Knowledge Distillation (KD) philosophy, which is combined with the class token. This distillation token is trained to mimic the predictions from the teacher network, while the class token replicates the true label. All the strategies have been tested on the RSR2015-Part II and DeepMine-Part 1 databases for text-dependent SV, providing competitive results compared to the same architecture using the average pooling mechanism to extract average embeddings.
Generalizing AUC Optimization to Multiclass Classification for Audio Segmentation With Limited Training Data
Oct 27, 2021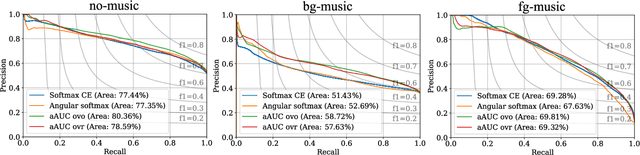
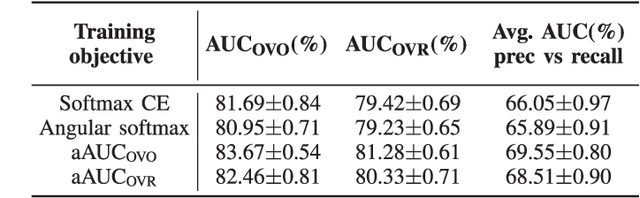

Area under the ROC curve (AUC) optimisation techniques developed for neural networks have recently demonstrated their capabilities in different audio and speech related tasks. However, due to its intrinsic nature, AUC optimisation has focused only on binary tasks so far. In this paper, we introduce an extension to the AUC optimisation framework so that it can be easily applied to an arbitrary number of classes, aiming to overcome the issues derived from training data limitations in deep learning solutions. Building upon the multiclass definitions of the AUC metric found in the literature, we define two new training objectives using a one-versus-one and a one-versus-rest approach. In order to demonstrate its potential, we apply them in an audio segmentation task with limited training data that aims to differentiate 3 classes: foreground music, background music and no music. Experimental results show that our proposal can improve the performance of audio segmentation systems significantly compared to traditional training criteria such as cross entropy.
Shouted Speech Compensation for Speaker Verification Robust to Vocal Effort Conditions
Aug 06, 2020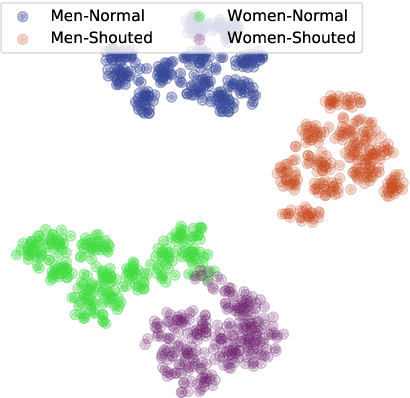
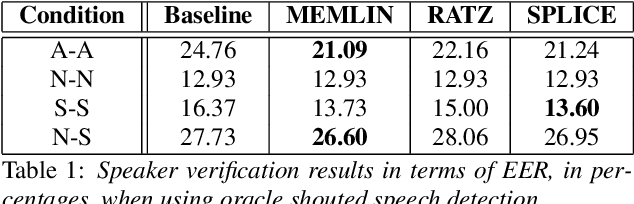
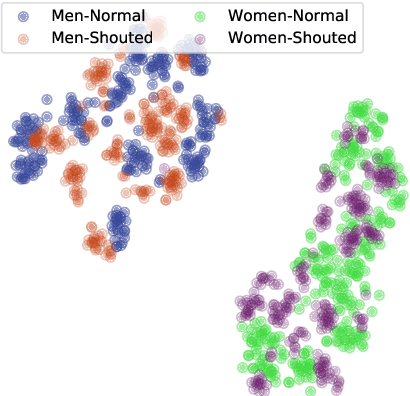
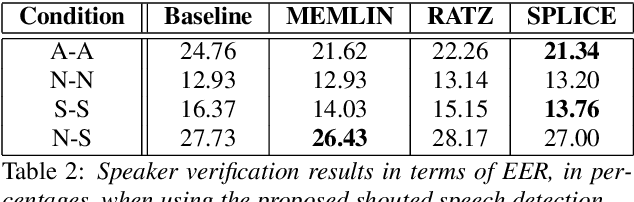
The performance of speaker verification systems degrades when vocal effort conditions between enrollment and test (e.g., shouted vs. normal speech) are different. This is a potential situation in non-cooperative speaker verification tasks. In this paper, we present a study on different methods for linear compensation of embeddings making use of Gaussian mixture models to cluster shouted and normal speech domains. These compensation techniques are borrowed from the area of robustness for automatic speech recognition and, in this work, we apply them to compensate the mismatch between shouted and normal conditions in speaker verification. Before compensation, shouted condition is automatically detected by means of logistic regression. The process is computationally light and it is performed in the back-end of an x-vector system. Experimental results show that applying the proposed approach in the presence of vocal effort mismatch yields up to 13.8% equal error rate relative improvement with respect to a system that applies neither shouted speech detection nor compensation.
Optimization of the Area Under the ROC Curve using Neural Network Supervectors for Text-Dependent Speaker Verification
Jan 31, 2019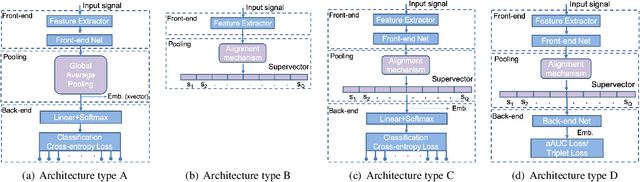
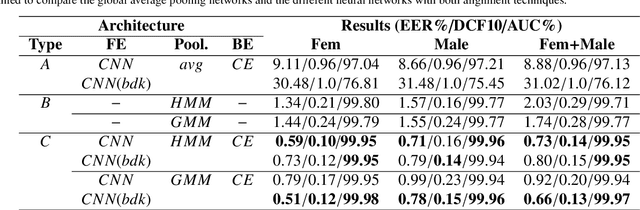

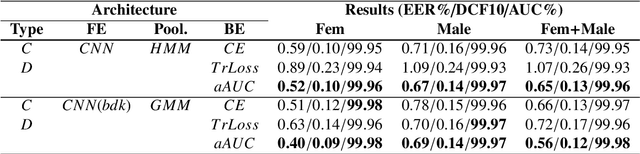
This paper explores two techniques to improve the performance of text-dependent speaker verification systems based on deep neural networks. Firstly, we propose a general alignment mechanism to keep the temporal structure of each phrase and obtain a supervector with the speaker and phrase information, since both are relevant for a text-dependent verification. As we show, it is possible to use different alignment techniques to replace the average pooling providing significant gains in performance. Moreover, we present a novel back-end approach to train a neural network for detection tasks by optimizing the Area Under the Curve (AUC) as an alternative to the usual triplet loss function, so the system is end-to-end, with a cost function closed to our desired measure of performance. As we can see in the experimental section, this approach improves the system performance, since our triplet AUC neural network learns how to discriminate between pairs of examples from the same identity and pairs of different identities. The different alignment techniques to produce supervectors in addition to the new back-end approach were tested on the RSR2015-Part I database for text-dependent speaker verification, providing competitive results compared to similar size networks using the average pooling to extract supervectors and using a simple back-end or triplet loss training.
Tied Hidden Factors in Neural Networks for End-to-End Speaker Recognition
Dec 27, 2018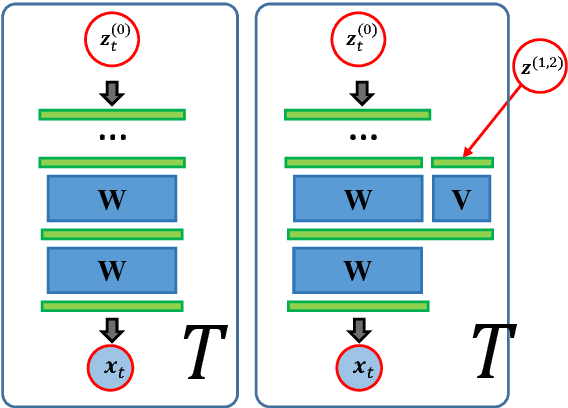
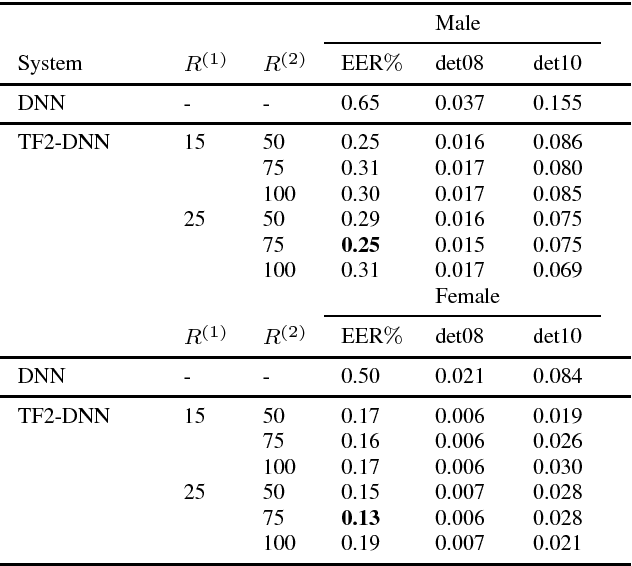
In this paper we propose a method to model speaker and session variability and able to generate likelihood ratios using neural networks in an end-to-end phrase dependent speaker verification system. As in Joint Factor Analysis, the model uses tied hidden variables to model speaker and session variability and a MAP adaptation of some of the parameters of the model. In the training procedure our method jointly estimates the network parameters and the values of the speaker and channel hidden variables. This is done in a two-step backpropagation algorithm, first the network weights and factor loading matrices are updated and then the hidden variables, whose gradients are calculated by aggregating the corresponding speaker or session frames, since these hidden variables are tied. The last layer of the network is defined as a linear regression probabilistic model whose inputs are the previous layer outputs. This choice has the advantage that it produces likelihoods and additionally it can be adapted during the enrolment using MAP without the need of a gradient optimization. The decisions are made based on the ratio of the output likelihoods of two neural network models, speaker adapted and universal background model. The method was evaluated on the RSR2015 database.
Differentiable Supervector Extraction for Encoding Speaker and Phrase Information in Text Dependent Speaker Verification
Dec 22, 2018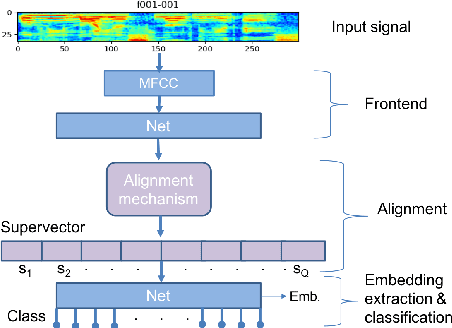
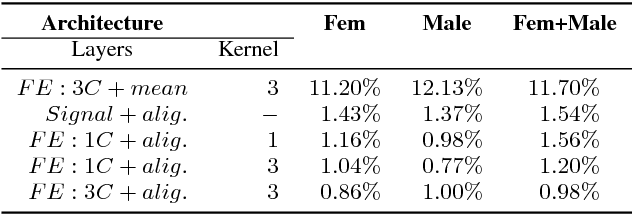
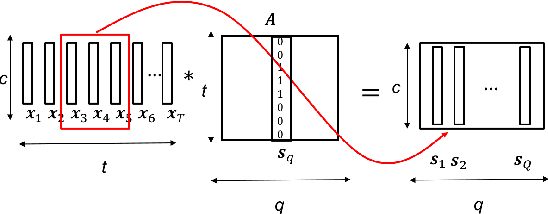
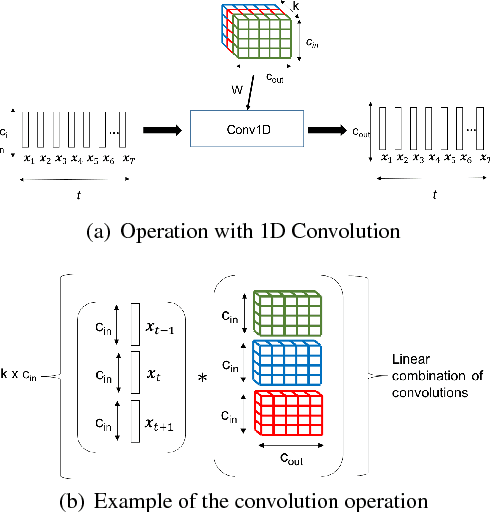
In this paper, we propose a new differentiable neural network alignment mechanism for text-dependent speaker verification which uses alignment models to produce a supervector representation of an utterance. Unlike previous works with similar approaches, we do not extract the embedding of an utterance from the mean reduction of the temporal dimension. Our system replaces the mean by a phrase alignment model to keep the temporal structure of each phrase which is relevant in this application since the phonetic information is part of the identity in the verification task. Moreover, we can apply a convolutional neural network as front-end, and thanks to the alignment process being differentiable, we can train the whole network to produce a supervector for each utterance which will be discriminative with respect to the speaker and the phrase simultaneously. As we show, this choice has the advantage that the supervector encodes the phrase and speaker information providing good performance in text-dependent speaker verification tasks. In this work, the process of verification is performed using a basic similarity metric, due to simplicity, compared to other more elaborate models that are commonly used. The new model using alignment to produce supervectors was tested on the RSR2015-Part I database for text-dependent speaker verification, providing competitive results compared to similar size networks using the mean to extract embeddings.