 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Speech Enhancement for Reverberated and Noisy Signals using Wide Residual Networks
Jan 03, 2019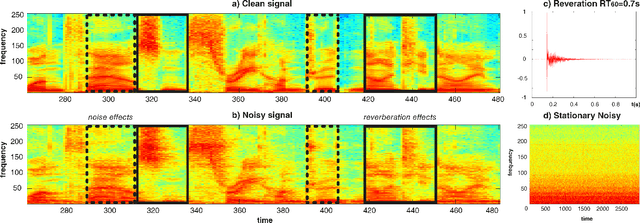
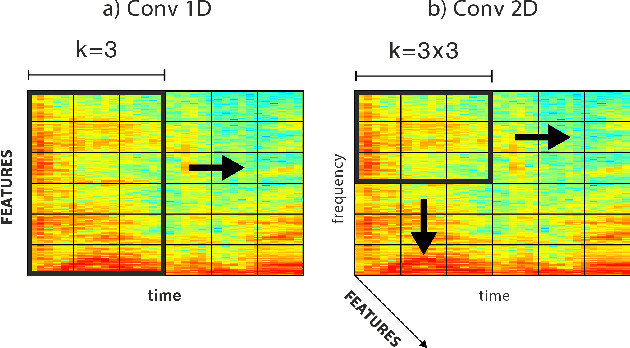
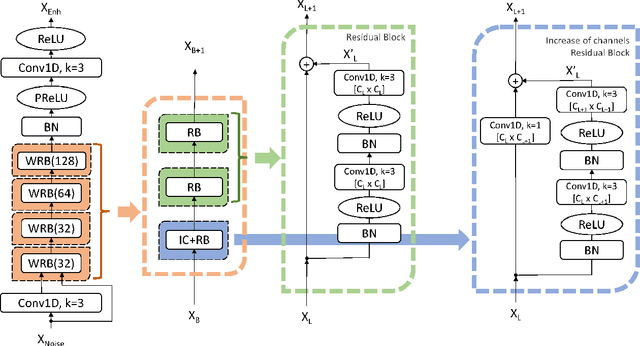
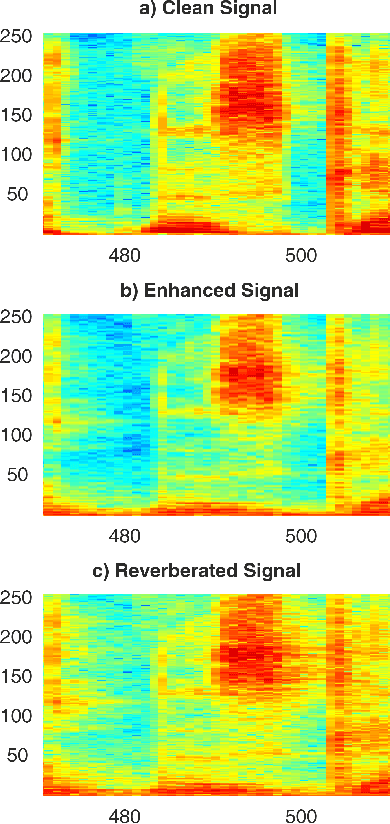
This paper proposes a deep speech enhancement method which exploits the high potential of residual connections in a wide neural network architecture, a topology known as Wide Residual Network. This is supported on single dimensional convolutions computed alongside the time domain, which is a powerful approach to process contextually correlated representations through the temporal domain, such as speech feature sequences. We find the residual mechanism extremely useful for the enhancement task since the signal always has a linear shortcut and the non-linear path enhances it in several steps by adding or subtracting corrections. The enhancement capacity of the proposal is assessed by objective quality metrics and the performance of a speech recognition system. This was evaluated in the framework of the REVERB Challenge dataset, including simulated and real samples of reverberated and noisy speech signals. Results showed that enhanced speech from the proposed method succeeded for both, the enhancement task with intelligibility purposes and the speech recognition system. The DNN model, trained with artificial synthesized reverberation data, was able to deal with far-field reverberated speech from real scenarios. Furthermore, the method was able to take advantage of the residual connection achieving to enhance signals with low noise level, which is usually a strong handicap of traditional enhancement methods.
Tied Hidden Factors in Neural Networks for End-to-End Speaker Recognition
Dec 27, 2018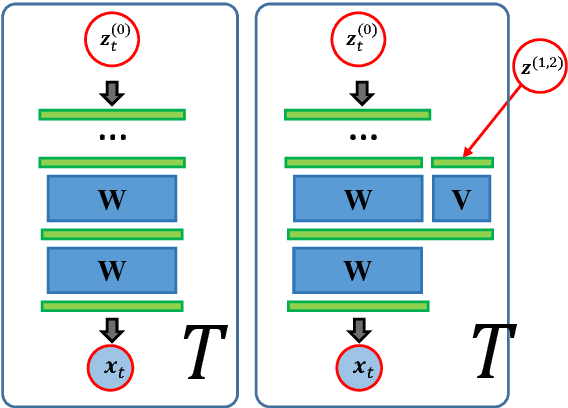
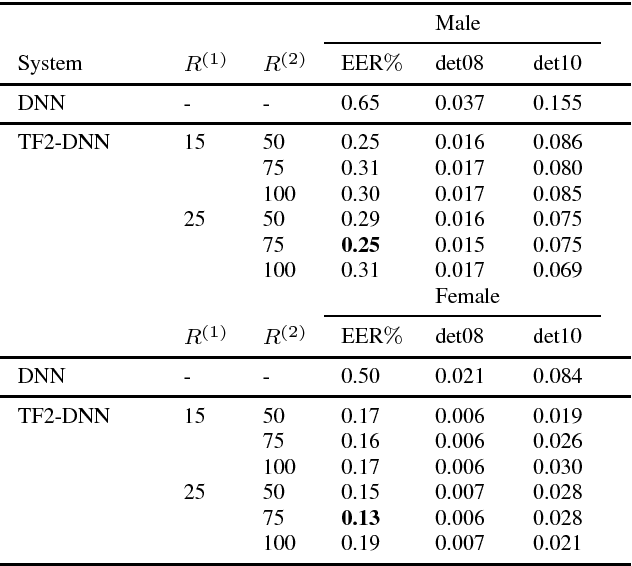
In this paper we propose a method to model speaker and session variability and able to generate likelihood ratios using neural networks in an end-to-end phrase dependent speaker verification system. As in Joint Factor Analysis, the model uses tied hidden variables to model speaker and session variability and a MAP adaptation of some of the parameters of the model. In the training procedure our method jointly estimates the network parameters and the values of the speaker and channel hidden variables. This is done in a two-step backpropagation algorithm, first the network weights and factor loading matrices are updated and then the hidden variables, whose gradients are calculated by aggregating the corresponding speaker or session frames, since these hidden variables are tied. The last layer of the network is defined as a linear regression probabilistic model whose inputs are the previous layer outputs. This choice has the advantage that it produces likelihoods and additionally it can be adapted during the enrolment using MAP without the need of a gradient optimization. The decisions are made based on the ratio of the output likelihoods of two neural network models, speaker adapted and universal background model. The method was evaluated on the RSR2015 database.