 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefining and Measuring Disentanglement for non-Independent Factors of Variation
Aug 13, 2024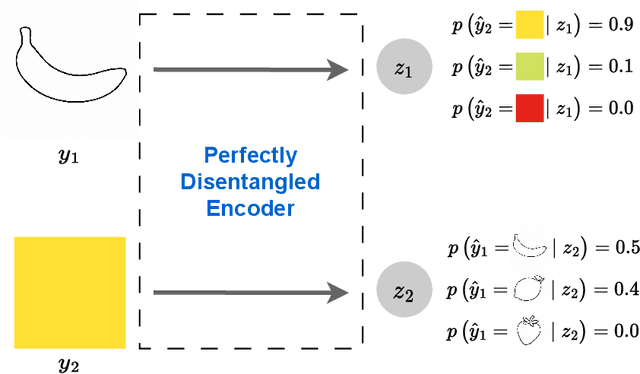
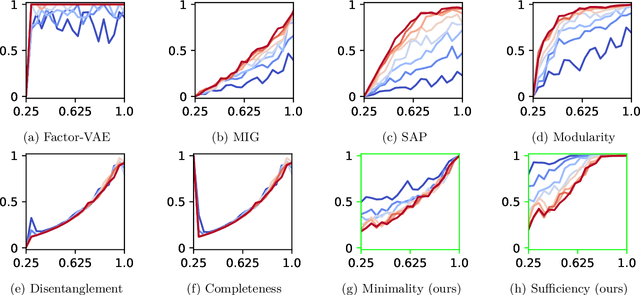

Representation learning is an approach that allows to discover and extract the factors of variation from the data. Intuitively, a representation is said to be disentangled if it separates the different factors of variation in a way that is understandable to humans. Definitions of disentanglement and metrics to measure it usually assume that the factors of variation are independent of each other. However, this is generally false in the real world, which limits the use of these definitions and metrics to very specific and unrealistic scenarios. In this paper we give a definition of disentanglement based on information theory that is also valid when the factors of variation are not independent. Furthermore, we relate this definition to the Information Bottleneck Method. Finally, we propose a method to measure the degree of disentanglement from the given definition that works when the factors of variation are not independent. We show through different experiments that the method proposed in this paper correctly measures disentanglement with non-independent factors of variation, while other methods fail in this scenario.
Predefined Prototypes for Intra-Class Separation and Disentanglement
Jun 23, 2024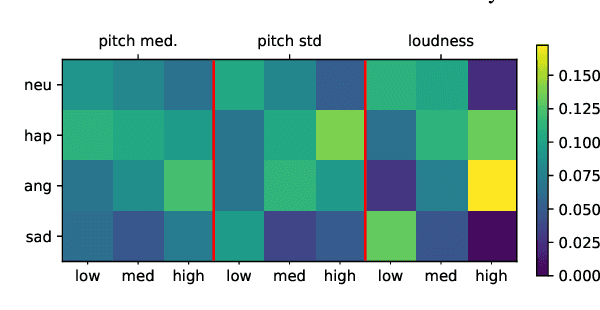
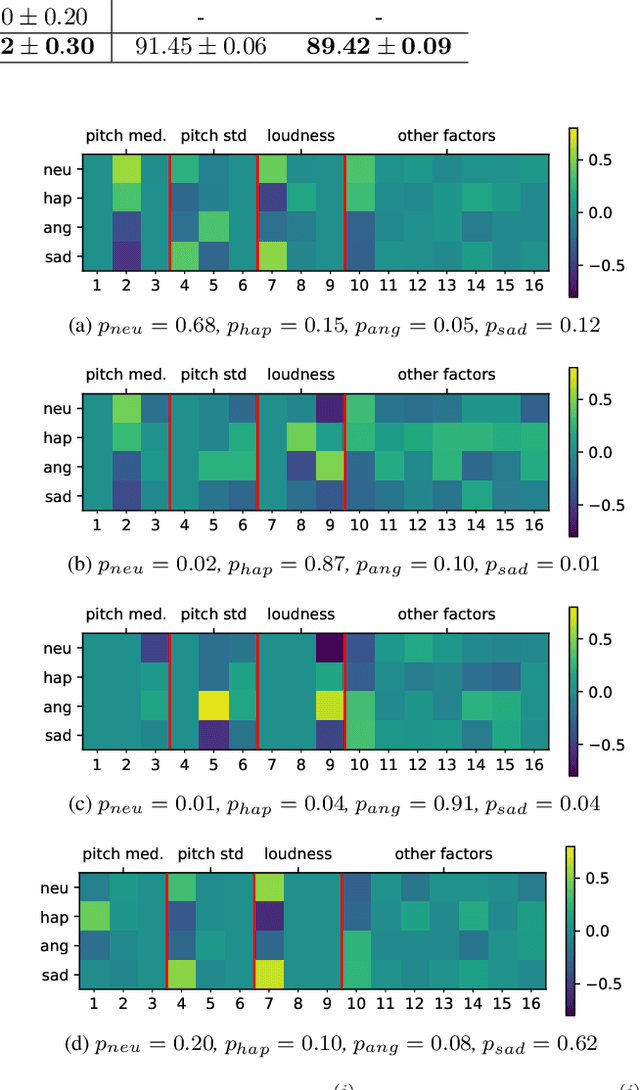
Prototypical Learning is based on the idea that there is a point (which we call prototype) around which the embeddings of a class are clustered. It has shown promising results in scenarios with little labeled data or to design explainable models. Typically, prototypes are either defined as the average of the embeddings of a class or are designed to be trainable. In this work, we propose to predefine prototypes following human-specified criteria, which simplify the training pipeline and brings different advantages. Specifically, in this work we explore two of these advantages: increasing the inter-class separability of embeddings and disentangling embeddings with respect to different variance factors, which can translate into the possibility of having explainable predictions. Finally, we propose different experiments that help to understand our proposal and demonstrate empirically the mentioned advantages.
Direct Text to Speech Translation System using Acoustic Units
Sep 14, 2023This paper proposes a direct text to speech translation system using discrete acoustic units. This framework employs text in different source languages as input to generate speech in the target language without the need for text transcriptions in this language. Motivated by the success of acoustic units in previous works for direct speech to speech translation systems, we use the same pipeline to extract the acoustic units using a speech encoder combined with a clustering algorithm. Once units are obtained, an encoder-decoder architecture is trained to predict them. Then a vocoder generates speech from units. Our approach for direct text to speech translation was tested on the new CVSS corpus with two different text mBART models employed as initialisation. The systems presented report competitive performance for most of the language pairs evaluated. Besides, results show a remarkable improvement when initialising our proposed architecture with a model pre-trained with more languages.
Improved Cross-Lingual Transfer Learning For Automatic Speech Translation
Jun 01, 2023



Research in multilingual speech-to-text translation is topical. Having a single model that supports multiple translation tasks is desirable. The goal of this work it to improve cross-lingual transfer learning in multilingual speech-to-text translation via semantic knowledge distillation. We show that by initializing the encoder of the encoder-decoder sequence-to-sequence translation model with SAMU-XLS-R, a multilingual speech transformer encoder trained using multi-modal (speech-text) semantic knowledge distillation, we achieve significantly better cross-lingual task knowledge transfer than the baseline XLS-R, a multilingual speech transformer encoder trained via self-supervised learning. We demonstrate the effectiveness of our approach on two popular datasets, namely, CoVoST-2 and Europarl. On the 21 translation tasks of the CoVoST-2 benchmark, we achieve an average improvement of 12.8 BLEU points over the baselines. In the zero-shot translation scenario, we achieve an average gain of 18.8 and 11.9 average BLEU points on unseen medium and low-resource languages. We make similar observations on Europarl speech translation benchmark.
Deep Speech Enhancement for Reverberated and Noisy Signals using Wide Residual Networks
Jan 03, 2019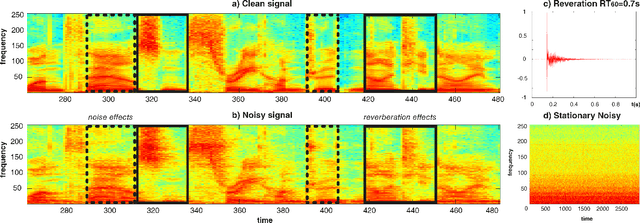
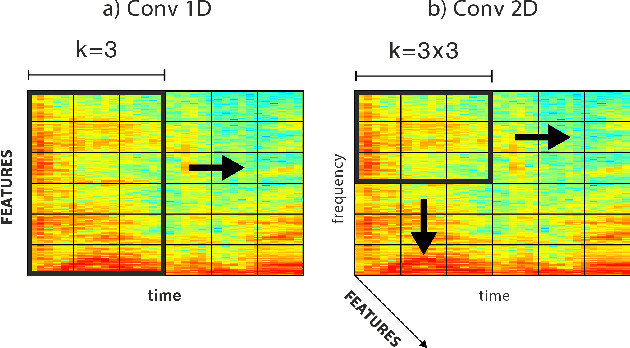
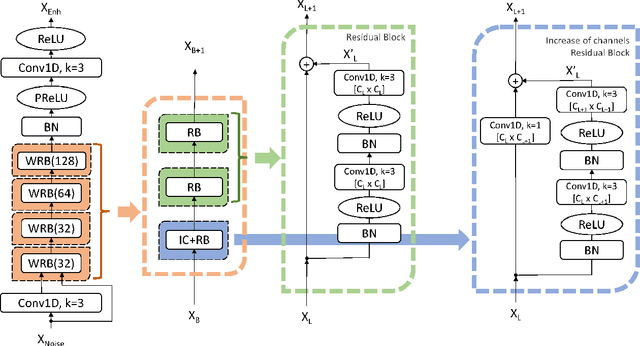
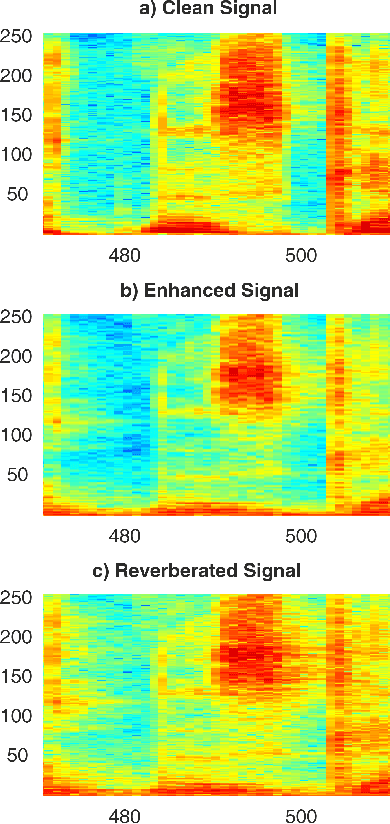
This paper proposes a deep speech enhancement method which exploits the high potential of residual connections in a wide neural network architecture, a topology known as Wide Residual Network. This is supported on single dimensional convolutions computed alongside the time domain, which is a powerful approach to process contextually correlated representations through the temporal domain, such as speech feature sequences. We find the residual mechanism extremely useful for the enhancement task since the signal always has a linear shortcut and the non-linear path enhances it in several steps by adding or subtracting corrections. The enhancement capacity of the proposal is assessed by objective quality metrics and the performance of a speech recognition system. This was evaluated in the framework of the REVERB Challenge dataset, including simulated and real samples of reverberated and noisy speech signals. Results showed that enhanced speech from the proposed method succeeded for both, the enhancement task with intelligibility purposes and the speech recognition system. The DNN model, trained with artificial synthesized reverberation data, was able to deal with far-field reverberated speech from real scenarios. Furthermore, the method was able to take advantage of the residual connection achieving to enhance signals with low noise level, which is usually a strong handicap of traditional enhancement methods.