 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Vocal Effort Transfer Vector Estimation for Vocal Effort-Robust Speaker Verification
May 03, 2023Despite the maturity of modern speaker verification technology, its performance still significantly degrades when facing non-neutrally-phonated (e.g., shouted and whispered) speech. To address this issue, in this paper, we propose a new speaker embedding compensation method based on a minimum mean square error (MMSE) estimator. This method models the joint distribution of the vocal effort transfer vector and non-neutrally-phonated embedding spaces and operates in a principal component analysis domain to cope with non-neutrally-phonated speech data scarcity. Experiments are carried out using a cutting-edge speaker verification system integrating a powerful self-supervised pre-trained model for speech representation. In comparison with a state-of-the-art embedding compensation method, the proposed MMSE estimator yields superior and competitive equal error rate results when tackling shouted and whispered speech, respectively.
Shouted Speech Compensation for Speaker Verification Robust to Vocal Effort Conditions
Aug 06, 2020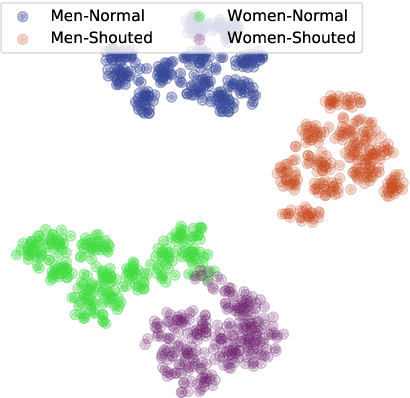
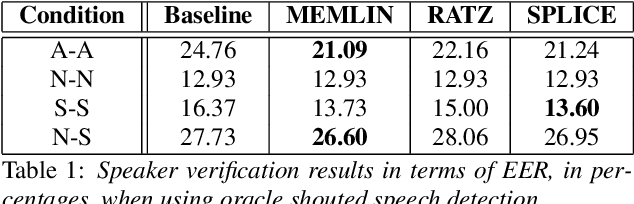
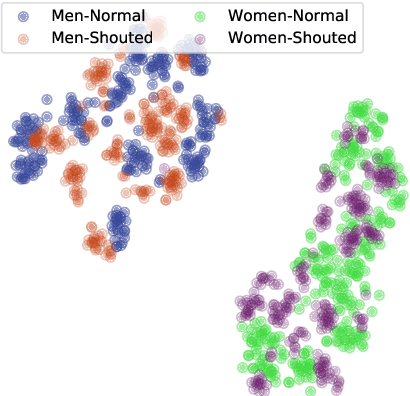
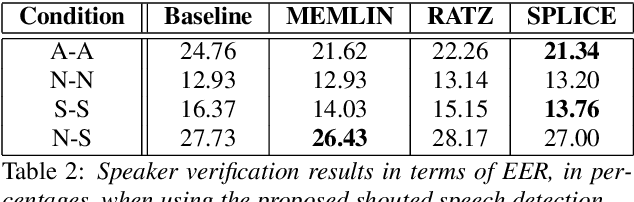
The performance of speaker verification systems degrades when vocal effort conditions between enrollment and test (e.g., shouted vs. normal speech) are different. This is a potential situation in non-cooperative speaker verification tasks. In this paper, we present a study on different methods for linear compensation of embeddings making use of Gaussian mixture models to cluster shouted and normal speech domains. These compensation techniques are borrowed from the area of robustness for automatic speech recognition and, in this work, we apply them to compensate the mismatch between shouted and normal conditions in speaker verification. Before compensation, shouted condition is automatically detected by means of logistic regression. The process is computationally light and it is performed in the back-end of an x-vector system. Experimental results show that applying the proposed approach in the presence of vocal effort mismatch yields up to 13.8% equal error rate relative improvement with respect to a system that applies neither shouted speech detection nor compensation.