 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLIWhiz: A Non-Intrusive Lyric Intelligibility Prediction System for the Cadenza Challenge
Dec 11, 2025We present LIWhiz, a non-intrusive lyric intelligibility prediction system submitted to the ICASSP 2026 Cadenza Challenge. LIWhiz leverages Whisper for robust feature extraction and a trainable back-end for score prediction. Tested on the Cadenza Lyric Intelligibility Prediction (CLIP) evaluation set, LIWhiz achieves a 22.4% relative root mean squared error reduction over the STOI-based baseline, yielding a substantial improvement in normalized cross-correlation.
Noise-Robust Hearing Aid Voice Control
Nov 05, 2024



Advancing the design of robust hearing aid (HA) voice control is crucial to increase the HA use rate among hard of hearing people as well as to improve HA users' experience. In this work, we contribute towards this goal by, first, presenting a novel HA speech dataset consisting of noisy own voice captured by 2 behind-the-ear (BTE) and 1 in-ear-canal (IEC) microphones. Second, we provide baseline HA voice control results from the evaluation of light, state-of-the-art keyword spotting models utilizing different combinations of HA microphone signals. Experimental results show the benefits of exploiting bandwidth-limited bone-conducted speech (BCS) from the IEC microphone to achieve noise-robust HA voice control. Furthermore, results also demonstrate that voice control performance can be boosted by assisting BCS by the broader-bandwidth BTE microphone signals. Aiming at setting a baseline upon which the scientific community can continue to progress, the HA noisy speech dataset has been made publicly available.
ASASVIcomtech: The Vicomtech-UGR Speech Deepfake Detection and SASV Systems for the ASVspoof5 Challenge
Aug 19, 2024



This paper presents the work carried out by the ASASVIcomtech team, made up of researchers from Vicomtech and University of Granada, for the ASVspoof5 Challenge. The team has participated in both Track 1 (speech deepfake detection) and Track 2 (spoofing-aware speaker verification). This work started with an analysis of the challenge available data, which was regarded as an essential step to avoid later potential biases of the trained models, and whose main conclusions are presented here. With respect to the proposed approaches, a closed-condition system employing a deep complex convolutional recurrent architecture was developed for Track 1, although, unfortunately, no noteworthy results were achieved. On the other hand, different possibilities of open-condition systems, based on leveraging self-supervised models, augmented training data from previous challenges, and novel vocoders, were explored for both tracks, finally achieving very competitive results with an ensemble system.
PolySinger: Singing-Voice to Singing-Voice Translation from English to Japanese
Jul 19, 2024



The speech domain prevails in the spotlight for several natural language processing (NLP) tasks while the singing domain remains less explored. The culmination of NLP is the speech-to-speech translation (S2ST) task, referring to translation and synthesis of human speech. A disparity between S2ST and the possible adaptation to the singing domain, which we describe as singing-voice to singing-voice translation (SV2SVT), is becoming prominent as the former is progressing ever faster, while the latter is at a standstill. Singing-voice synthesis systems are overcoming the barrier of multi-lingual synthesis, despite limited attention has been paid to multi-lingual songwriting and song translation. This paper endeavors to determine what is required for successful SV2SVT and proposes PolySinger (Polyglot Singer): the first system for SV2SVT, performing lyrics translation from English to Japanese. A cascaded approach is proposed to establish a framework with a high degree of control which can potentially diminish the disparity between SV2SVT and S2ST. The performance of PolySinger is evaluated by a mean opinion score test with native Japanese speakers. Results and in-depth discussions with test subjects suggest a solid foundation for SV2SVT, but several shortcomings must be overcome, which are discussed for the future of SV2SVT.
Evaluating Speech Enhancement Systems Through Listening Effort
May 13, 2024Understanding degraded speech is demanding, requiring increased listening effort (LE). Evaluating processed and unprocessed speech with respect to LE can objectively indicate if speech enhancement systems benefit listeners. However, existing methods for measuring LE are complex and not widely applicable. In this study, we propose a simple method to evaluate speech intelligibility and LE simultaneously without additional strain on subjects or operators. We assess this method using results from two independent studies in Norway and Denmark, testing 76 (50+26) subjects across 9 (6+3) processing conditions. Despite differences in evaluation setups, subject recruitment, and processing systems, trends are strikingly similar, demonstrating the proposed method's robustness and ease of implementation into existing practices.
On Speech Pre-emphasis as a Simple and Inexpensive Method to Boost Speech Enhancement
Jan 17, 2024Pre-emphasis filtering, compensating for the natural energy decay of speech at higher frequencies, has been considered as a common pre-processing step in a number of speech processing tasks over the years. In this work, we demonstrate, for the first time, that pre-emphasis filtering may also be used as a simple and computationally-inexpensive way to leverage deep neural network-based speech enhancement performance. Particularly, we look into pre-emphasizing the estimated and actual clean speech prior to loss calculation so that different speech frequency components better mirror their perceptual importance during the training phase. Experimental results on a noisy version of the TIMIT dataset show that integrating the pre-emphasis-based methodology at hand yields relative estimated speech quality improvements of up to 4.6% and 3.4% for noise types seen and unseen, respectively, during the training phase. Similar to the case of pre-emphasis being considered as a default pre-processing step in classical automatic speech recognition and speech coding systems, the pre-emphasis-based methodology analyzed in this article may potentially become a default add-on for modern speech enhancement.
Improved Vocal Effort Transfer Vector Estimation for Vocal Effort-Robust Speaker Verification
May 03, 2023



Despite the maturity of modern speaker verification technology, its performance still significantly degrades when facing non-neutrally-phonated (e.g., shouted and whispered) speech. To address this issue, in this paper, we propose a new speaker embedding compensation method based on a minimum mean square error (MMSE) estimator. This method models the joint distribution of the vocal effort transfer vector and non-neutrally-phonated embedding spaces and operates in a principal component analysis domain to cope with non-neutrally-phonated speech data scarcity. Experiments are carried out using a cutting-edge speaker verification system integrating a powerful self-supervised pre-trained model for speech representation. In comparison with a state-of-the-art embedding compensation method, the proposed MMSE estimator yields superior and competitive equal error rate results when tackling shouted and whispered speech, respectively.
Filterbank Learning for Small-Footprint Keyword Spotting Robust to Noise
Nov 19, 2022



In the context of keyword spotting (KWS), the replacement of handcrafted speech features by learnable features has not yielded superior KWS performance. In this study, we demonstrate that filterbank learning outperforms handcrafted speech features for KWS whenever the number of filterbank channels is severely decreased. Reducing the number of channels might yield certain KWS performance drop, but also a substantial energy consumption reduction, which is key when deploying common always-on KWS on low-resource devices. Experimental results on a noisy version of the Google Speech Commands Dataset show that filterbank learning adapts to noise characteristics to provide a higher degree of robustness to noise, especially when dropout is integrated. Thus, switching from typically used 40-channel log-Mel features to 8-channel learned features leads to a relative KWS accuracy loss of only 3.5% while simultaneously achieving a 6.3x energy consumption reduction.
Deep Spoken Keyword Spotting: An Overview
Nov 20, 2021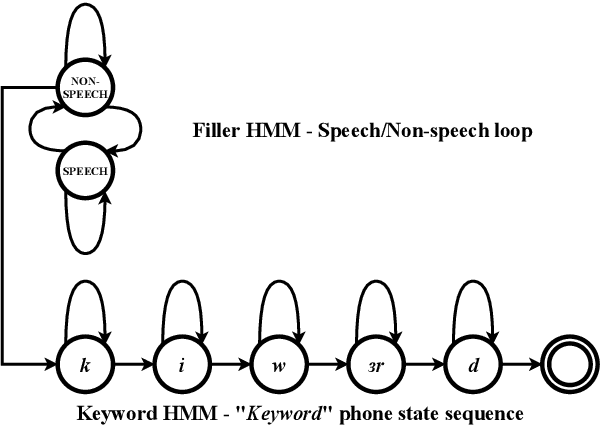
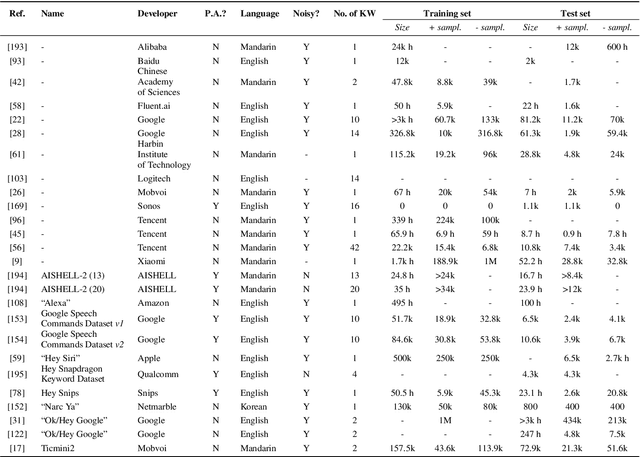
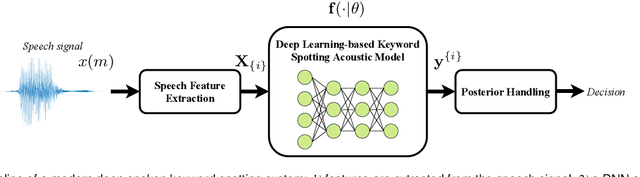

Spoken keyword spotting (KWS) deals with the identification of keywords in audio streams and has become a fast-growing technology thanks to the paradigm shift introduced by deep learning a few years ago. This has allowed the rapid embedding of deep KWS in a myriad of small electronic devices with different purposes like the activation of voice assistants. Prospects suggest a sustained growth in terms of social use of this technology. Thus, it is not surprising that deep KWS has become a hot research topic among speech scientists, who constantly look for KWS performance improvement and computational complexity reduction. This context motivates this paper, in which we conduct a literature review into deep spoken KWS to assist practitioners and researchers who are interested in this technology. Specifically, this overview has a comprehensive nature by covering a thorough analysis of deep KWS systems (which includes speech features, acoustic modeling and posterior handling), robustness methods, applications, datasets, evaluation metrics, performance of deep KWS systems and audio-visual KWS. The analysis performed in this paper allows us to identify a number of directions for future research, including directions adopted from automatic speech recognition research and directions that are unique to the problem of spoken KWS.
Shouted Speech Compensation for Speaker Verification Robust to Vocal Effort Conditions
Aug 06, 2020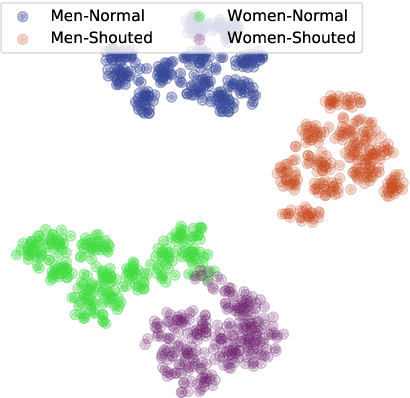
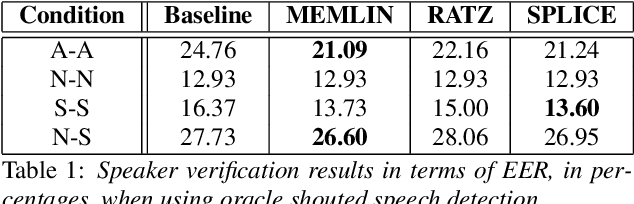
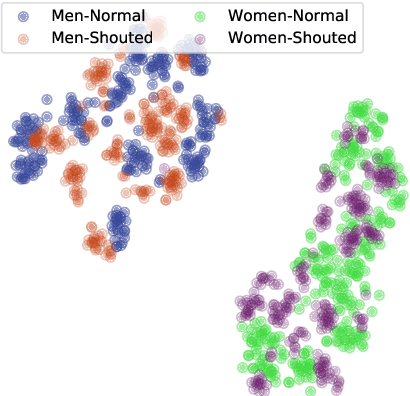
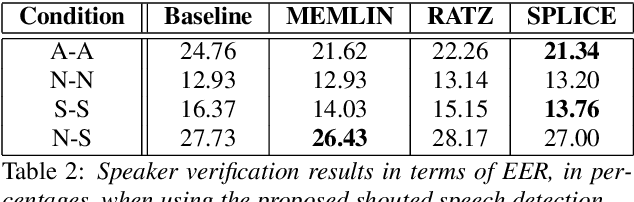
The performance of speaker verification systems degrades when vocal effort conditions between enrollment and test (e.g., shouted vs. normal speech) are different. This is a potential situation in non-cooperative speaker verification tasks. In this paper, we present a study on different methods for linear compensation of embeddings making use of Gaussian mixture models to cluster shouted and normal speech domains. These compensation techniques are borrowed from the area of robustness for automatic speech recognition and, in this work, we apply them to compensate the mismatch between shouted and normal conditions in speaker verification. Before compensation, shouted condition is automatically detected by means of logistic regression. The process is computationally light and it is performed in the back-end of an x-vector system. Experimental results show that applying the proposed approach in the presence of vocal effort mismatch yields up to 13.8% equal error rate relative improvement with respect to a system that applies neither shouted speech detection nor compensation.