 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASASVIcomtech: The Vicomtech-UGR Speech Deepfake Detection and SASV Systems for the ASVspoof5 Challenge
Aug 19, 2024



This paper presents the work carried out by the ASASVIcomtech team, made up of researchers from Vicomtech and University of Granada, for the ASVspoof5 Challenge. The team has participated in both Track 1 (speech deepfake detection) and Track 2 (spoofing-aware speaker verification). This work started with an analysis of the challenge available data, which was regarded as an essential step to avoid later potential biases of the trained models, and whose main conclusions are presented here. With respect to the proposed approaches, a closed-condition system employing a deep complex convolutional recurrent architecture was developed for Track 1, although, unfortunately, no noteworthy results were achieved. On the other hand, different possibilities of open-condition systems, based on leveraging self-supervised models, augmented training data from previous challenges, and novel vocoders, were explored for both tracks, finally achieving very competitive results with an ensemble system.
On Speech Pre-emphasis as a Simple and Inexpensive Method to Boost Speech Enhancement
Jan 17, 2024Pre-emphasis filtering, compensating for the natural energy decay of speech at higher frequencies, has been considered as a common pre-processing step in a number of speech processing tasks over the years. In this work, we demonstrate, for the first time, that pre-emphasis filtering may also be used as a simple and computationally-inexpensive way to leverage deep neural network-based speech enhancement performance. Particularly, we look into pre-emphasizing the estimated and actual clean speech prior to loss calculation so that different speech frequency components better mirror their perceptual importance during the training phase. Experimental results on a noisy version of the TIMIT dataset show that integrating the pre-emphasis-based methodology at hand yields relative estimated speech quality improvements of up to 4.6% and 3.4% for noise types seen and unseen, respectively, during the training phase. Similar to the case of pre-emphasis being considered as a default pre-processing step in classical automatic speech recognition and speech coding systems, the pre-emphasis-based methodology analyzed in this article may potentially become a default add-on for modern speech enhancement.
Scalable Kernel-Based Minimum Mean Square Error Estimator for Accelerated Image Error Concealment
May 23, 2022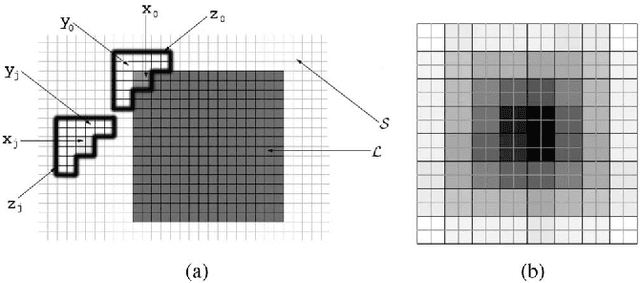

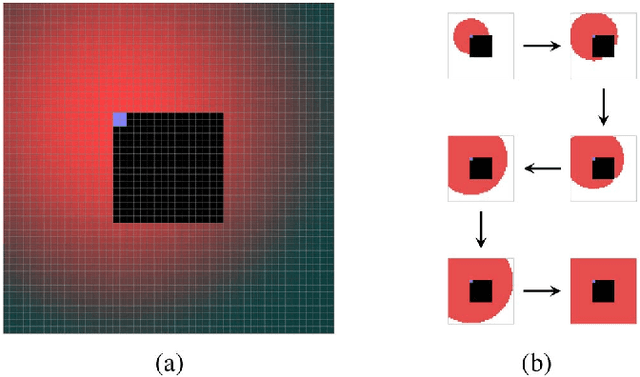
Error concealment is of great importance for block-based video systems, such as DVB or video streaming services. In this paper, we propose a novel scalable spatial error concealment algorithm that aims at obtaining high quality reconstructions with reduced computational burden. The proposed technique exploits the excellent reconstructing abilities of the kernel-based minimum mean square error K-MMSE estimator. We propose to decompose this approach into a set of hierarchically stacked layers. The first layer performs the basic reconstruction that the subsequent layers can eventually refine. In addition, we design a layer management mechanism, based on profiles, that dynamically adapts the use of higher layers to the visual complexity of the area being reconstructed. The proposed technique outperforms other state-of-the-art algorithms and produces high quality reconstructions, equivalent to K-MMSE, while requiring around one tenth of its computational time.
Frequency selective extrapolation with residual filtering for image error concealment
May 16, 2022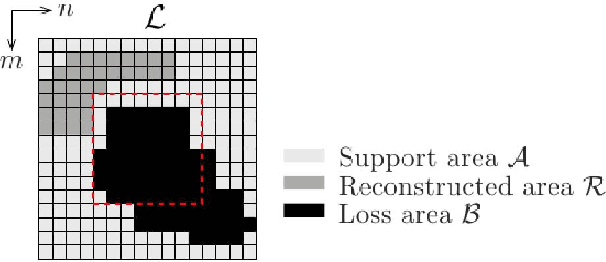
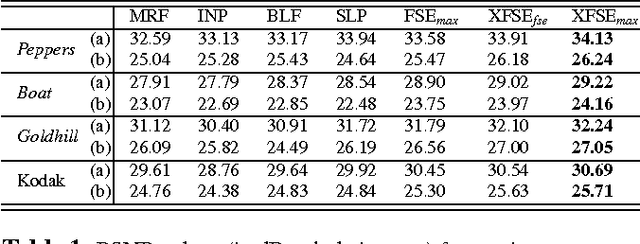
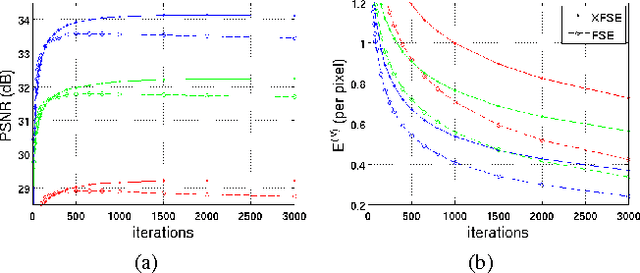
The purpose of signal extrapolation is to estimate unknown signal parts from known samples. This task is especially important for error concealment in image and video communication. For obtaining a high quality reconstruction, assumptions have to be made about the underlying signal in order to solve this underdetermined problem. Among existent reconstruction algorithms, frequency selective extrapolation (FSE) achieves high performance by assuming that image signals can be sparsely represented in the frequency domain. However, FSE does not take into account the low-pass behaviour of natural images. In this paper, we propose a modified FSE that takes this prior knowledge into account for the modelling, yielding significant PSNR gains.
Adversarial Transformation of Spoofing Attacks for Voice Biometrics
Jan 04, 2022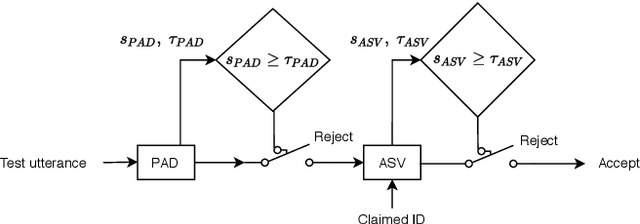
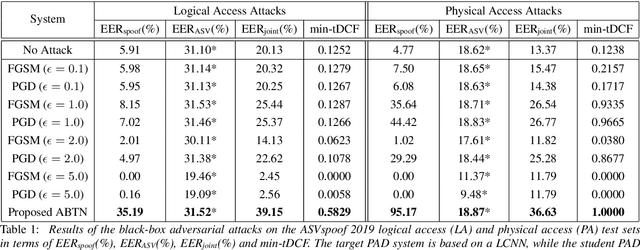
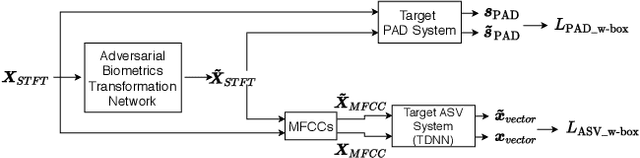
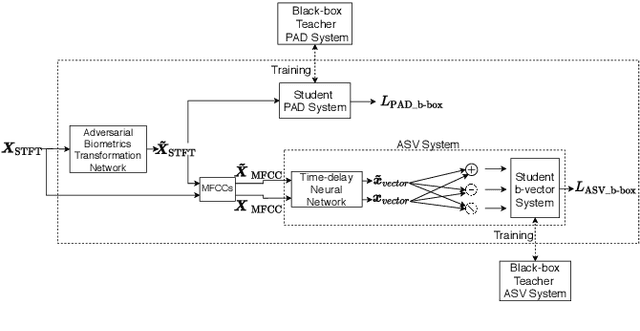
Voice biometric systems based on automatic speaker verification (ASV) are exposed to \textit{spoofing} attacks which may compromise their security. To increase the robustness against such attacks, anti-spoofing or presentation attack detection (PAD) systems have been proposed for the detection of replay, synthesis and voice conversion based attacks. Recently, the scientific community has shown that PAD systems are also vulnerable to adversarial attacks. However, to the best of our knowledge, no previous work have studied the robustness of full voice biometrics systems (ASV + PAD) to these new types of adversarial \textit{spoofing} attacks. In this work, we develop a new adversarial biometrics transformation network (ABTN) which jointly processes the loss of the PAD and ASV systems in order to generate white-box and black-box adversarial \textit{spoofing} attacks. The core idea of this system is to generate adversarial \textit{spoofing} attacks which are able to fool the PAD system without being detected by the ASV system. The experiments were carried out on the ASVspoof 2019 corpus, including both logical access (LA) and physical access (PA) scenarios. The experimental results show that the proposed ABTN clearly outperforms some well-known adversarial techniques in both white-box and black-box attack scenarios.
PANACEA cough sound-based diagnosis of COVID-19 for the DiCOVA 2021 Challenge
Jun 07, 2021
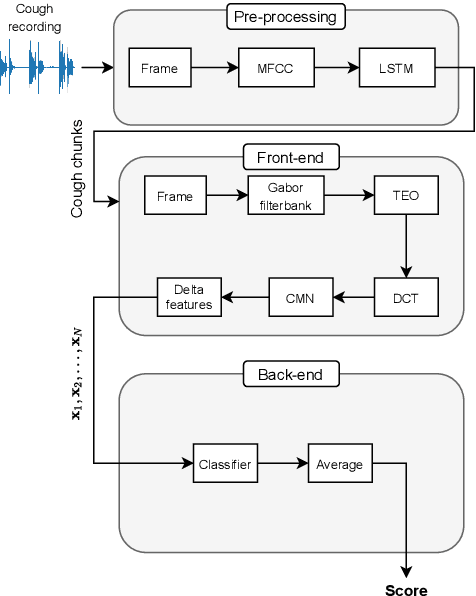
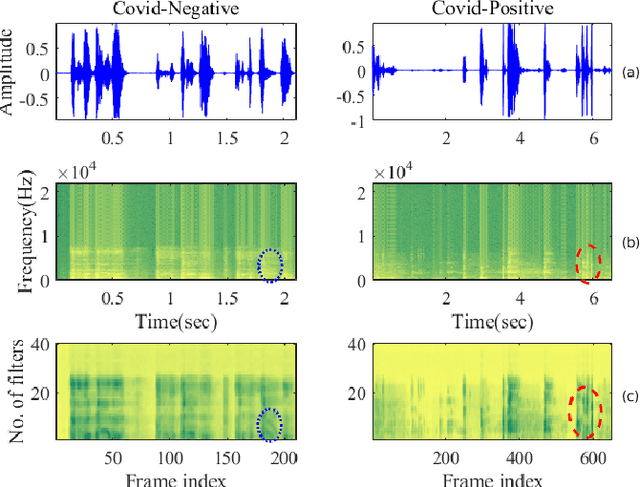
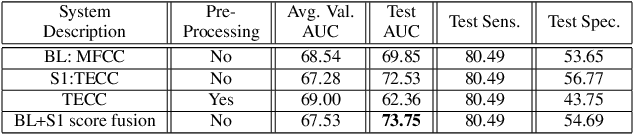
The COVID-19 pandemic has led to the saturation of public health services worldwide. In this scenario, the early diagnosis of SARS-Cov-2 infections can help to stop or slow the spread of the virus and to manage the demand upon health services. This is especially important when resources are also being stretched by heightened demand linked to other seasonal diseases, such as the flu. In this context, the organisers of the DiCOVA 2021 challenge have collected a database with the aim of diagnosing COVID-19 through the use of coughing audio samples. This work presents the details of the automatic system for COVID-19 detection from cough recordings presented by team PANACEA. This team consists of researchers from two European academic institutions and one company: EURECOM (France), University of Granada (Spain), and Biometric Vox S.L. (Spain). We developed several systems based on established signal processing and machine learning methods. Our best system employs a Teager energy operator cepstral coefficients (TECCs) based frontend and Light gradient boosting machine (LightGBM) backend. The AUC obtained by this system on the test set is 76.31% which corresponds to a 10% improvement over the official baseline.