 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASASVIcomtech: The Vicomtech-UGR Speech Deepfake Detection and SASV Systems for the ASVspoof5 Challenge
Aug 19, 2024



This paper presents the work carried out by the ASASVIcomtech team, made up of researchers from Vicomtech and University of Granada, for the ASVspoof5 Challenge. The team has participated in both Track 1 (speech deepfake detection) and Track 2 (spoofing-aware speaker verification). This work started with an analysis of the challenge available data, which was regarded as an essential step to avoid later potential biases of the trained models, and whose main conclusions are presented here. With respect to the proposed approaches, a closed-condition system employing a deep complex convolutional recurrent architecture was developed for Track 1, although, unfortunately, no noteworthy results were achieved. On the other hand, different possibilities of open-condition systems, based on leveraging self-supervised models, augmented training data from previous challenges, and novel vocoders, were explored for both tracks, finally achieving very competitive results with an ensemble system.
The Vicomtech Spoofing-Aware Biometric System for the SASV Challenge
Apr 04, 2022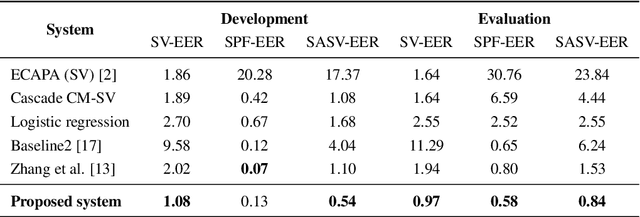

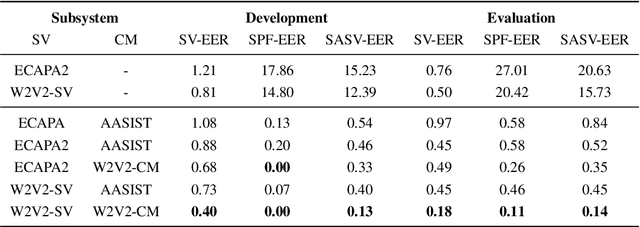

This paper describes our proposed integration system for the spoofing-aware speaker verification challenge. It consists of a robust spoofing-aware verification system that use the speaker verification and antispoofing embeddings extracted from specialized neural networks. First, an integration network, fed with the test utterance's speaker verification and spoofing embeddings, is used to compute a spoof-based score. This score is then linearly combined with the cosine similarity between the speaker verification embeddings from the enrollment and test utterances, thus obtaining the final scoring decision. Moreover, the integration network is trained using a one-class loss function to discriminate between target trials and unauthorized accesses. Our proposed system is evaluated in the ASVspoof19 database, exhibiting competitive performance compared to other integration approaches. In addition, we test, along with our integration approach, state of the art speaker verification and antispoofing systems based on self-supervised learning, yielding high-performance speech biometric systems.
The Vicomtech Audio Deepfake Detection System based on Wav2Vec2 for the 2022 ADD Challenge
Mar 03, 2022
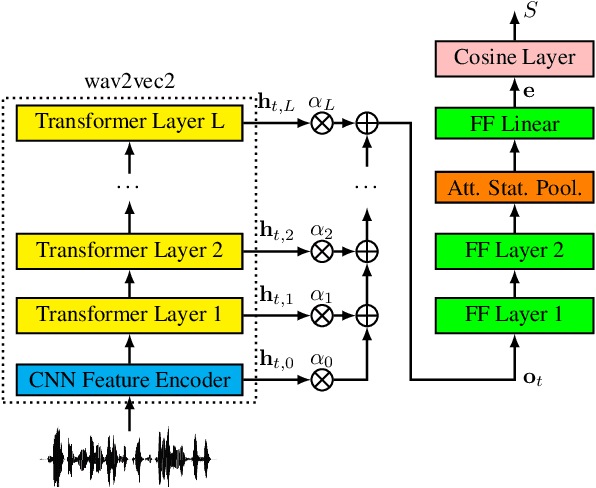
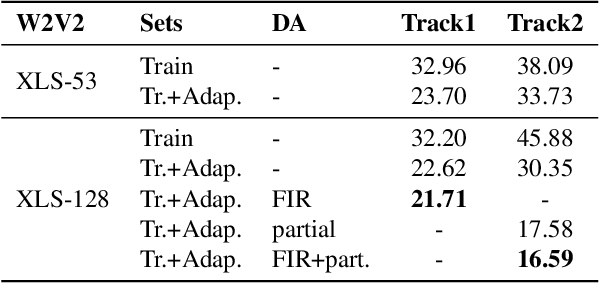
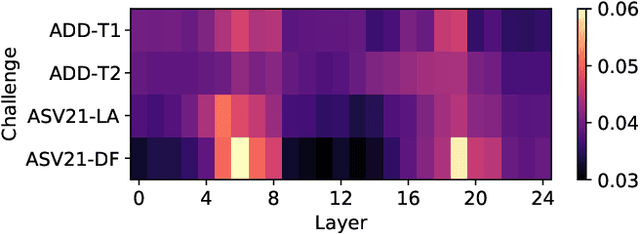
This paper describes our submitted systems to the 2022 ADD challenge withing the tracks 1 and 2. Our approach is based on the combination of a pre-trained wav2vec2 feature extractor and a downstream classifier to detect spoofed audio. This method exploits the contextualized speech representations at the different transformer layers to fully capture discriminative information. Furthermore, the classification model is adapted to the application scenario using different data augmentation techniques. We evaluate our system for audio synthesis detection in both the ASVspoof 2021 and the 2022 ADD challenges, showing its robustness and good performance in realistic challenging environments such as telephonic and audio codec systems, noisy audio, and partial deepfakes.