 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASR advancements for indigenous languages: Quechua, Guarani, Bribri, Kotiria, and Wa'ikhana
Apr 12, 2024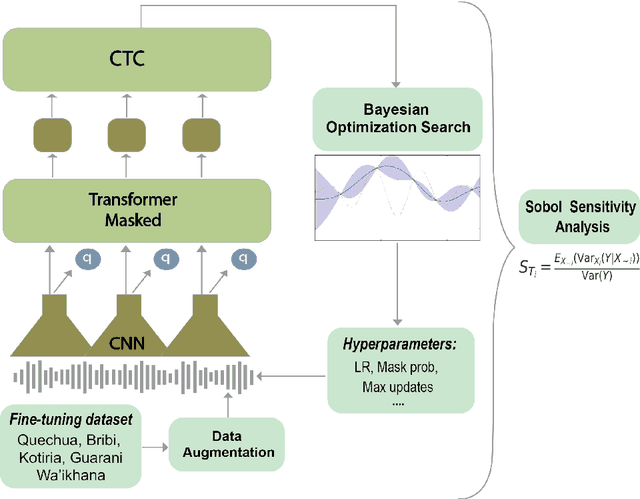
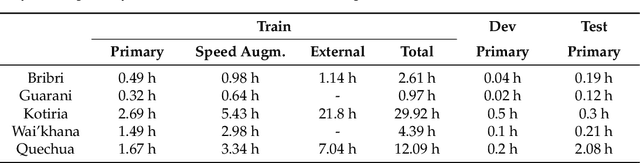
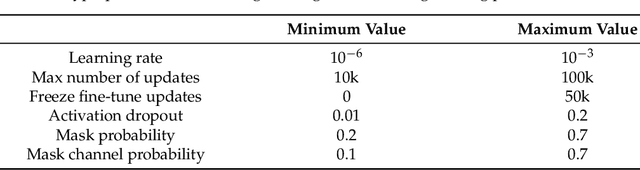
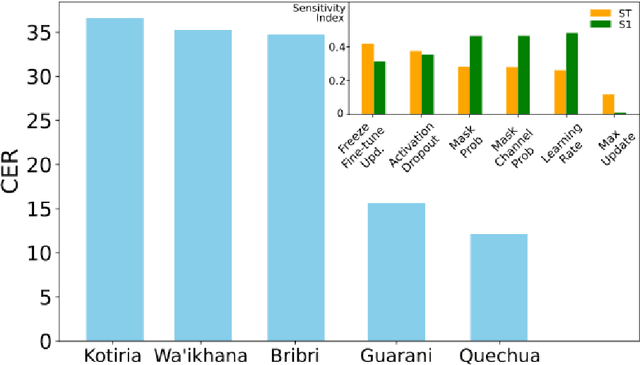
Indigenous languages are a fundamental legacy in the development of human communication, embodying the unique identity and culture of local communities of America. The Second AmericasNLP Competition Track 1 of NeurIPS 2022 proposed developing automatic speech recognition (ASR) systems for five indigenous languages: Quechua, Guarani, Bribri, Kotiria, and Wa'ikhana. In this paper, we propose a reliable ASR model for each target language by crawling speech corpora spanning diverse sources and applying data augmentation methods that resulted in the winning approach in this competition. To achieve this, we systematically investigated the impact of different hyperparameters by a Bayesian search on the performance of the language models, specifically focusing on the variants of the Wav2vec2.0 XLS-R model: 300M and 1B parameters. Moreover, we performed a global sensitivity analysis to assess the contribution of various hyperparametric configurations to the performances of our best models. Importantly, our results show that freeze fine-tuning updates and dropout rate are more vital parameters than the total number of epochs of lr. Additionally, we liberate our best models -- with no other ASR model reported until now for two Wa'ikhana and Kotiria -- and the many experiments performed to pave the way to other researchers to continue improving ASR in minority languages. This insight opens up interesting avenues for future work, allowing for the advancement of ASR techniques in the preservation of minority indigenous and acknowledging the complexities involved in this important endeavour.
The Vicomtech Spoofing-Aware Biometric System for the SASV Challenge
Apr 04, 2022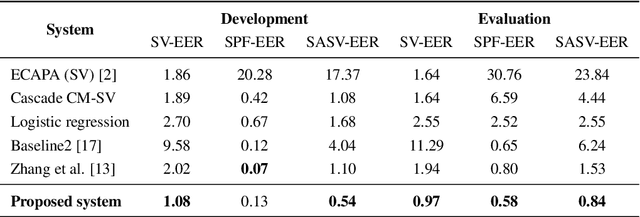

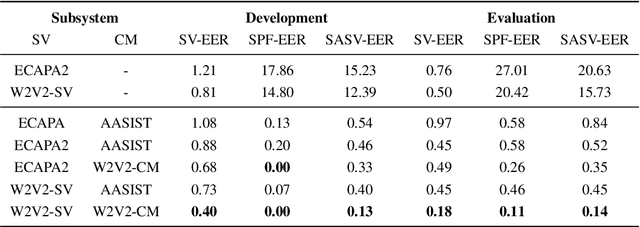

This paper describes our proposed integration system for the spoofing-aware speaker verification challenge. It consists of a robust spoofing-aware verification system that use the speaker verification and antispoofing embeddings extracted from specialized neural networks. First, an integration network, fed with the test utterance's speaker verification and spoofing embeddings, is used to compute a spoof-based score. This score is then linearly combined with the cosine similarity between the speaker verification embeddings from the enrollment and test utterances, thus obtaining the final scoring decision. Moreover, the integration network is trained using a one-class loss function to discriminate between target trials and unauthorized accesses. Our proposed system is evaluated in the ASVspoof19 database, exhibiting competitive performance compared to other integration approaches. In addition, we test, along with our integration approach, state of the art speaker verification and antispoofing systems based on self-supervised learning, yielding high-performance speech biometric systems.