 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster Repeated Evasion Attacks in Tree Ensembles
Feb 13, 2024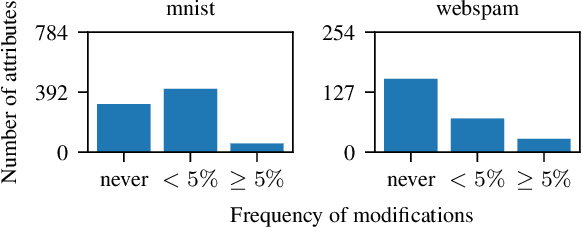
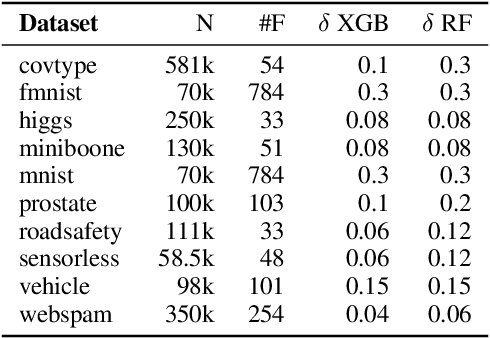
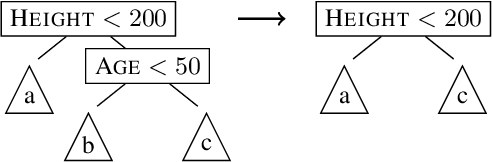
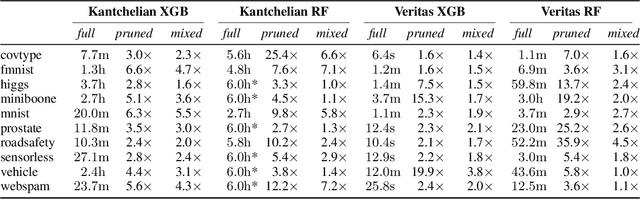
Tree ensembles are one of the most widely used model classes. However, these models are susceptible to adversarial examples, i.e., slightly perturbed examples that elicit a misprediction. There has been significant research on designing approaches to construct such examples for tree ensembles. But this is a computationally challenging problem that often must be solved a large number of times (e.g., for all examples in a training set). This is compounded by the fact that current approaches attempt to find such examples from scratch. In contrast, we exploit the fact that multiple similar problems are being solved. Specifically, our approach exploits the insight that adversarial examples for tree ensembles tend to perturb a consistent but relatively small set of features. We show that we can quickly identify this set of features and use this knowledge to speedup constructing adversarial examples.
PANACEA cough sound-based diagnosis of COVID-19 for the DiCOVA 2021 Challenge
Jun 07, 2021
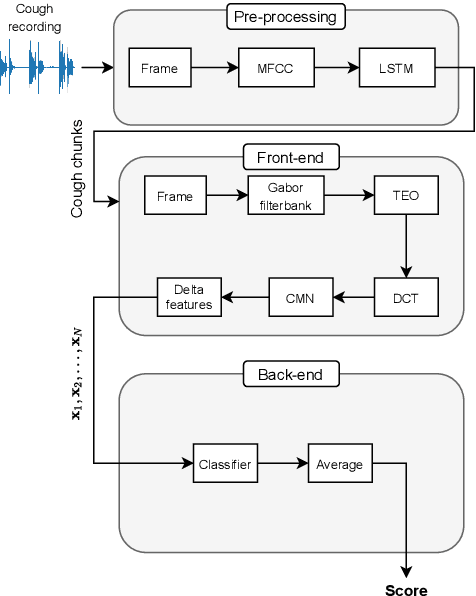
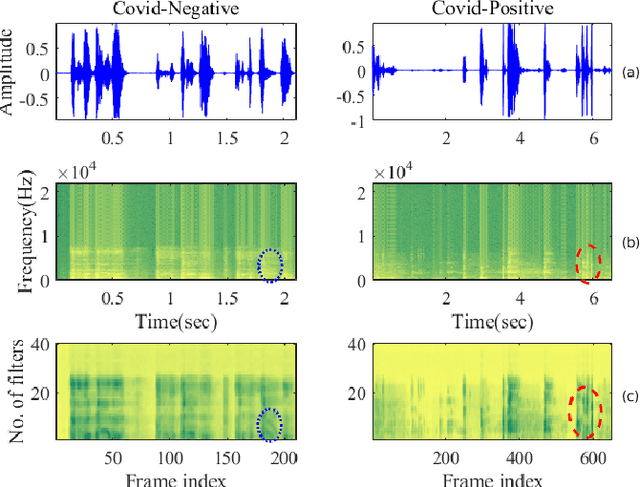
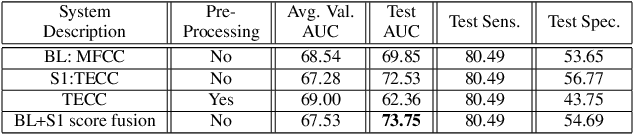
The COVID-19 pandemic has led to the saturation of public health services worldwide. In this scenario, the early diagnosis of SARS-Cov-2 infections can help to stop or slow the spread of the virus and to manage the demand upon health services. This is especially important when resources are also being stretched by heightened demand linked to other seasonal diseases, such as the flu. In this context, the organisers of the DiCOVA 2021 challenge have collected a database with the aim of diagnosing COVID-19 through the use of coughing audio samples. This work presents the details of the automatic system for COVID-19 detection from cough recordings presented by team PANACEA. This team consists of researchers from two European academic institutions and one company: EURECOM (France), University of Granada (Spain), and Biometric Vox S.L. (Spain). We developed several systems based on established signal processing and machine learning methods. Our best system employs a Teager energy operator cepstral coefficients (TECCs) based frontend and Light gradient boosting machine (LightGBM) backend. The AUC obtained by this system on the test set is 76.31% which corresponds to a 10% improvement over the official baseline.