 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBounded-Abstention Multi-horizon Time-series Forecasting
Feb 04, 2026Multi-horizon time-series forecasting involves simultaneously making predictions for a consecutive sequence of subsequent time steps. This task arises in many application domains, such as healthcare and finance, where mispredictions can have a high cost and reduce trust. The learning with abstention framework tackles these problems by allowing a model to abstain from offering a prediction when it is at an elevated risk of making a misprediction. Unfortunately, existing abstention strategies are ill-suited for the multi-horizon setting: they target problems where a model offers a single prediction for each instance. Hence, they ignore the structured and correlated nature of the predictions offered by a multi-horizon forecaster. We formalize the problem of learning with abstention for multi-horizon forecasting setting and show that its structured nature admits a richer set of abstention problems. Concretely, we propose three natural notions of how a model could abstain for multi-horizon forecasting. We theoretically analyze each problem to derive the optimal abstention strategy and propose an algorithm that implements it. Extensive evaluation on 24 datasets shows that our proposed algorithms significantly outperforms existing baselines.
Mitigating Negative Interference in Multilingual Sequential Knowledge Editing through Null-Space Constraints
Jun 12, 2025Efficiently updating multilingual knowledge in large language models (LLMs), while preserving consistent factual representations across languages, remains a long-standing and unresolved challenge. While deploying separate editing systems for each language might seem viable, this approach incurs substantial costs due to the need to manage multiple models. A more efficient solution involves integrating knowledge updates across all languages into a unified model. However, performing sequential edits across languages often leads to destructive parameter interference, significantly degrading multilingual generalization and the accuracy of injected knowledge. To address this challenge, we propose LangEdit, a novel null-space constrained framework designed to precisely isolate language-specific knowledge updates. The core innovation of LangEdit lies in its ability to project parameter updates for each language onto the orthogonal complement of previous updated subspaces. This approach mathematically guarantees update independence while preserving multilingual generalization capabilities. We conduct a comprehensive evaluation across three model architectures, six languages, and four downstream tasks, demonstrating that LangEdit effectively mitigates parameter interference and outperforms existing state-of-the-art editing methods. Our results highlight its potential for enabling efficient and accurate multilingual knowledge updates in LLMs. The code is available at https://github.com/VRCMF/LangEdit.git.
Stop Guessing: Optimizing Goalkeeper Policies for Soccer Penalty Kicks
May 30, 2025



Penalties are fraught and game-changing moments in soccer games that teams explicitly prepare for. Consequently, there has been substantial interest in analyzing them in order to provide advice to practitioners. From a data science perspective, such analyses suffer from a significant limitation: they make the unrealistic simplifying assumption that goalkeepers and takers select their action -- where to dive and where to the place the kick -- independently of each other. In reality, the choices that some goalkeepers make depend on the taker's movements and vice-versa. This adds substantial complexity to the problem because not all players have the same action capacities, that is, only some players are capable of basing their decisions on their opponent's movements. However, the small sample sizes on the player level mean that one may have limited insights into a specific opponent's capacities. We address these challenges by developing a player-agnostic simulation framework that can evaluate the efficacy of different goalkeeper strategies. It considers a rich set of choices and incorporates information about a goalkeeper's skills. Our work is grounded in a large dataset of penalties that were annotated by penalty experts and include aspects of both kicker and goalkeeper strategies. We show how our framework can be used to optimize goalkeeper policies in real-world situations.
The When and How of Target Variable Transformations
Apr 29, 2025The machine learning pipeline typically involves the iterative process of (1) collecting the data, (2) preparing the data, (3) learning a model, and (4) evaluating a model. Practitioners recognize the importance of the data preparation phase in terms of its impact on the ability to learn accurate models. In this regard, significant attention is often paid to manipulating the feature set (e.g., selection, transformations, dimensionality reduction). A point that is less well appreciated is that transformations on the target variable can also have a large impact on whether it is possible to learn a suitable model. These transformations may include accounting for subject-specific biases (e.g., in how someone uses a rating scale), contexts (e.g., population size effects), and general trends (e.g., inflation). However, this point has received a much more cursory treatment in the existing literature. The goal of this paper is three-fold. First, we aim to highlight the importance of this problem by showing when transforming the target variable has been useful in practice. Second, we will provide a set of generic ``rules of thumb'' that indicate situations when transforming the target variable may be needed. Third, we will discuss which transformations should be considered in a given situation.
Electron Microscopy-based Automatic Defect Inspection for Semiconductor Manufacturing: A Systematic Review
Sep 10, 2024In this review, automatic defect inspection algorithms that analyze Electron Microscope (EM) images of Semiconductor Manufacturing (SM) products are identified, categorized, and discussed. This is a topic of critical importance for the SM industry as the continuous shrinking of device patterns has led to increasing defectivity and a greater prevalence of higher-resolution imaging tools such as EM. These aspects among others threaten to increase costs as a result of increased inspection time-to-solution and decreased yield, respectively. Relevant research papers were systematically identified in four popular publication databases in January 2024. A total of 103 papers were selected after screening for novel contributions relating to automatic EM image analysis algorithms for semiconductor defect inspection. These papers were then categorized based on the inspection tasks they addressed, their evaluation metrics, and the type of algorithms used. A notable finding from this categorization is that reference-based defect detection algorithms were the most popular algorithm type until 2020 when deep learning-based inspection algorithms became more popular, especially for defect classification. Furthermore, four broader research questions were discussed to come to the following conclusions: (i) the key components of inspection algorithms are set up, pre-processing, feature extraction, and final prediction; (ii) the maturity of the manufacturing process affects the data availability and required sensitivity of inspection algorithms; (iii) key challenges for these algorithms relate to the desiderata of minimizing time-to-solution which pushes for high imaging throughput, reducing manual input during algorithm setup, and higher processing throughput; and (iv) three promising directions for future work are suggested based on gaps in the reviewed literature that address key remaining limitations.
DMON: A Simple yet Effective Approach for Argument Structure Learning
May 02, 2024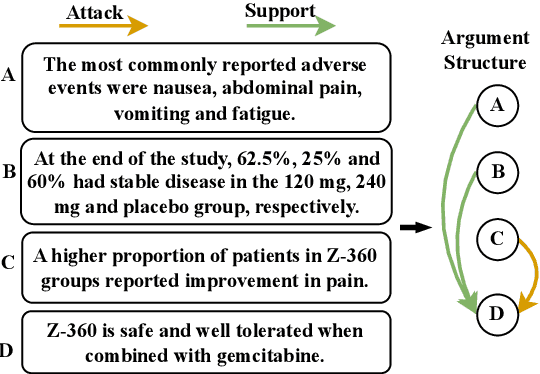
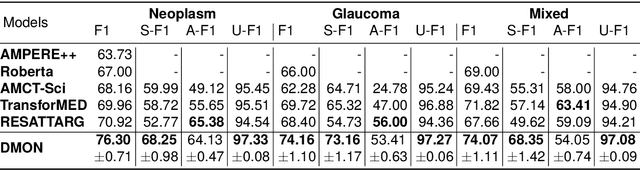
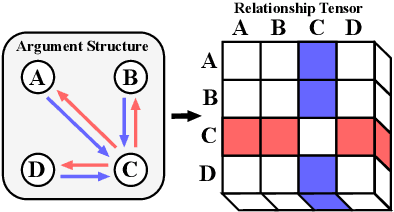
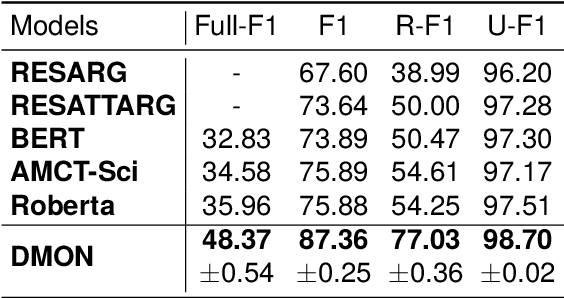
Argument structure learning~(ASL) entails predicting relations between arguments. Because it can structure a document to facilitate its understanding, it has been widely applied in many fields~(medical, commercial, and scientific domains). Despite its broad utilization, ASL remains a challenging task because it involves examining the complex relationships between the sentences in a potentially unstructured discourse. To resolve this problem, we have developed a simple yet effective approach called Dual-tower Multi-scale cOnvolution neural Network~(DMON) for the ASL task. Specifically, we organize arguments into a relationship matrix that together with the argument embeddings forms a relationship tensor and design a mechanism to capture relations with contextual arguments. Experimental results on three different-domain argument mining datasets demonstrate that our framework outperforms state-of-the-art models. The code is available at https://github.com/VRCMF/DMON.git .
Faster Repeated Evasion Attacks in Tree Ensembles
Feb 13, 2024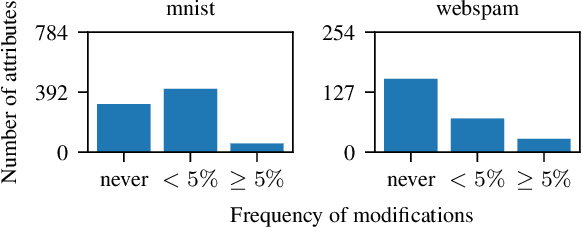
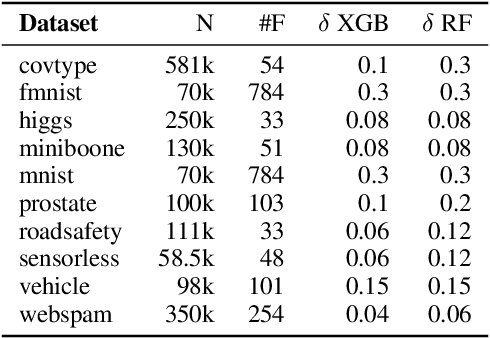
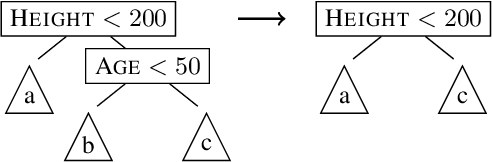
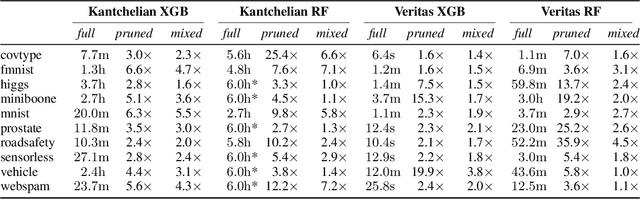
Tree ensembles are one of the most widely used model classes. However, these models are susceptible to adversarial examples, i.e., slightly perturbed examples that elicit a misprediction. There has been significant research on designing approaches to construct such examples for tree ensembles. But this is a computationally challenging problem that often must be solved a large number of times (e.g., for all examples in a training set). This is compounded by the fact that current approaches attempt to find such examples from scratch. In contrast, we exploit the fact that multiple similar problems are being solved. Specifically, our approach exploits the insight that adversarial examples for tree ensembles tend to perturb a consistent but relatively small set of features. We show that we can quickly identify this set of features and use this knowledge to speedup constructing adversarial examples.
Deep Neural Network Benchmarks for Selective Classification
Jan 23, 2024With the increasing deployment of machine learning models in many socially-sensitive tasks, there is a growing demand for reliable and trustworthy predictions. One way to accomplish these requirements is to allow a model to abstain from making a prediction when there is a high risk of making an error. This requires adding a selection mechanism to the model, which selects those examples for which the model will provide a prediction. The selective classification framework aims to design a mechanism that balances the fraction of rejected predictions (i.e., the proportion of examples for which the model does not make a prediction) versus the improvement in predictive performance on the selected predictions. Multiple selective classification frameworks exist, most of which rely on deep neural network architectures. However, the empirical evaluation of the existing approaches is still limited to partial comparisons among methods and settings, providing practitioners with little insight into their relative merits. We fill this gap by benchmarking 18 baselines on a diverse set of 44 datasets that includes both image and tabular data. Moreover, there is a mix of binary and multiclass tasks. We evaluate these approaches using several criteria, including selective error rate, empirical coverage, distribution of rejected instance's classes, and performance on out-of-distribution instances. The results indicate that there is not a single clear winner among the surveyed baselines, and the best method depends on the users' objectives.
Biases in Expected Goals Models Confound Finishing Ability
Jan 18, 2024Expected Goals (xG) has emerged as a popular tool for evaluating finishing skill in soccer analytics. It involves comparing a player's cumulative xG with their actual goal output, where consistent overperformance indicates strong finishing ability. However, the assessment of finishing skill in soccer using xG remains contentious due to players' difficulty in consistently outperforming their cumulative xG. In this paper, we aim to address the limitations and nuances surrounding the evaluation of finishing skill using xG statistics. Specifically, we explore three hypotheses: (1) the deviation between actual and expected goals is an inadequate metric due to the high variance of shot outcomes and limited sample sizes, (2) the inclusion of all shots in cumulative xG calculation may be inappropriate, and (3) xG models contain biases arising from interdependencies in the data that affect skill measurement. We found that sustained overperformance of cumulative xG requires both high shot volumes and exceptional finishing, including all shot types can obscure the finishing ability of proficient strikers, and that there is a persistent bias that makes the actual and expected goals closer for excellent finishers than it really is. Overall, our analysis indicates that we need more nuanced quantitative approaches for investigating a player's finishing ability, which we achieved using a technique from AI fairness to learn an xG model that is calibrated for multiple subgroups of players. As a concrete use case, we show that (1) the standard biased xG model underestimates Messi's GAX by 17% and (2) Messi's GAX is 27% higher than the typical elite high-shot-volume attacker, indicating that Messi is even a more exceptional finisher than people commonly believed.
Generating Explanations in Medical Question-Answering by Expectation Maximization Inference over Evidence
Oct 02, 2023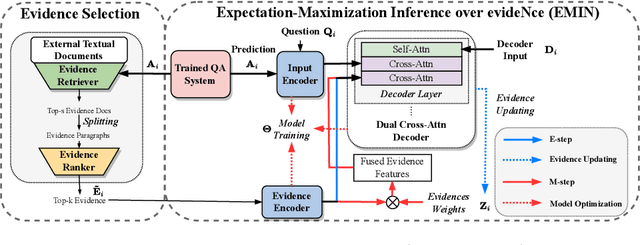
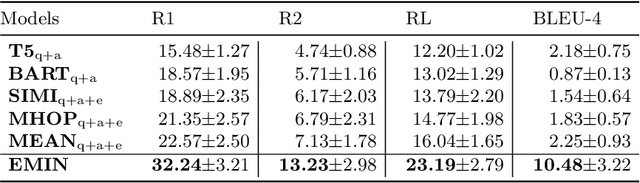
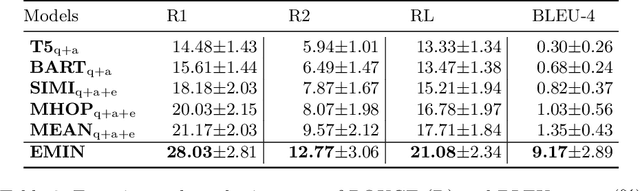
Medical Question Answering~(medical QA) systems play an essential role in assisting healthcare workers in finding answers to their questions. However, it is not sufficient to merely provide answers by medical QA systems because users might want explanations, that is, more analytic statements in natural language that describe the elements and context that support the answer. To do so, we propose a novel approach for generating natural language explanations for answers predicted by medical QA systems. As high-quality medical explanations require additional medical knowledge, so that our system extract knowledge from medical textbooks to enhance the quality of explanations during the explanation generation process. Concretely, we designed an expectation-maximization approach that makes inferences about the evidence found in these texts, offering an efficient way to focus attention on lengthy evidence passages. Experimental results, conducted on two datasets MQAE-diag and MQAE, demonstrate the effectiveness of our framework for reasoning with textual evidence. Our approach outperforms state-of-the-art models, achieving a significant improvement of \textbf{6.86} and \textbf{9.43} percentage points on the Rouge-1 score; \textbf{8.23} and \textbf{7.82} percentage points on the Bleu-4 score on the respective datasets.