 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Convergence of Multicalibration Gradient Boosting
Feb 06, 2026Multicalibration gradient boosting has recently emerged as a scalable method that empirically produces approximately multicalibrated predictors and has been deployed at web scale. Despite this empirical success, its convergence properties are not well understood. In this paper, we bridge the gap by providing convergence guarantees for multicalibration gradient boosting in regression with squared-error loss. We show that the magnitude of successive prediction updates decays at $O(1/\sqrt{T})$, which implies the same convergence rate bound for the multicalibration error over rounds. Under additional smoothness assumptions on the weak learners, this rate improves to linear convergence. We further analyze adaptive variants, showing local quadratic convergence of the training loss, and we study rescaling schemes that preserve convergence. Experiments on real-world datasets support our theory and clarify the regimes in which the method achieves fast convergence and strong multicalibration.
Multicalibration yields better matchings
Nov 14, 2025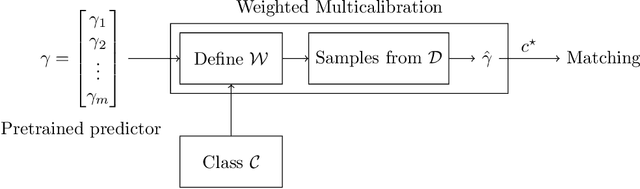
Consider the problem of finding the best matching in a weighted graph where we only have access to predictions of the actual stochastic weights, based on an underlying context. If the predictor is the Bayes optimal one, then computing the best matching based on the predicted weights is optimal. However, in practice, this perfect information scenario is not realistic. Given an imperfect predictor, a suboptimal decision rule may compensate for the induced error and thus outperform the standard optimal rule. In this paper, we propose multicalibration as a way to address this problem. This fairness notion requires a predictor to be unbiased on each element of a family of protected sets of contexts. Given a class of matching algorithms $\mathcal C$ and any predictor $γ$ of the edge-weights, we show how to construct a specific multicalibrated predictor $\hat γ$, with the following property. Picking the best matching based on the output of $\hat γ$ is competitive with the best decision rule in $\mathcal C$ applied onto the original predictor $γ$. We complement this result by providing sample complexity bounds.
Multiclass Local Calibration With the Jensen-Shannon Distance
Oct 30, 2025Developing trustworthy Machine Learning (ML) models requires their predicted probabilities to be well-calibrated, meaning they should reflect true-class frequencies. Among calibration notions in multiclass classification, strong calibration is the most stringent, as it requires all predicted probabilities to be simultaneously calibrated across all classes. However, existing approaches to multiclass calibration lack a notion of distance among inputs, which makes them vulnerable to proximity bias: predictions in sparse regions of the feature space are systematically miscalibrated. This is especially relevant in high-stakes settings, such as healthcare, where the sparse instances are exactly those most at risk of biased treatment. In this work, we address this main shortcoming by introducing a local perspective on multiclass calibration. First, we formally define multiclass local calibration and establish its relationship with strong calibration. Second, we theoretically analyze the pitfalls of existing evaluation metrics when applied to multiclass local calibration. Third, we propose a practical method for enhancing local calibration in Neural Networks, which enforces alignment between predicted probabilities and local estimates of class frequencies using the Jensen-Shannon distance. Finally, we empirically validate our approach against existing multiclass calibration techniques.
Measuring multi-calibration
Jun 12, 2025A suitable scalar metric can help measure multi-calibration, defined as follows. When the expected values of observed responses are equal to corresponding predicted probabilities, the probabilistic predictions are known as "perfectly calibrated." When the predicted probabilities are perfectly calibrated simultaneously across several subpopulations, the probabilistic predictions are known as "perfectly multi-calibrated." In practice, predicted probabilities are seldom perfectly multi-calibrated, so a statistic measuring the distance from perfect multi-calibration is informative. A recently proposed metric for calibration, based on the classical Kuiper statistic, is a natural basis for a new metric of multi-calibration and avoids well-known problems of metrics based on binning or kernel density estimation. The newly proposed metric weights the contributions of different subpopulations in proportion to their signal-to-noise ratios; data analyses' ablations demonstrate that the metric becomes noisy when omitting the signal-to-noise ratios from the metric. Numerical examples on benchmark data sets illustrate the new metric.
Uncertainty-aware Evaluation of Auxiliary Anomalies with the Expected Anomaly Posterior
May 22, 2024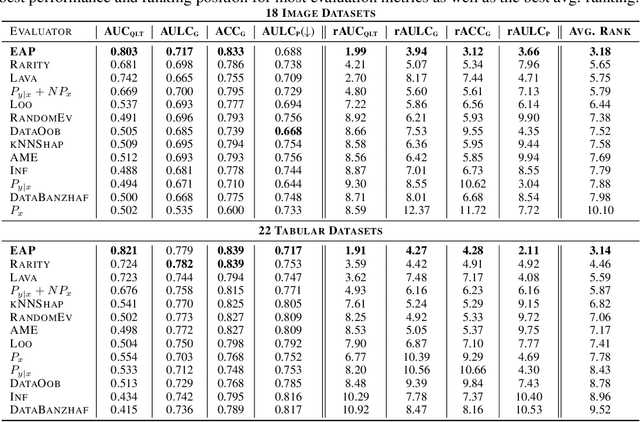
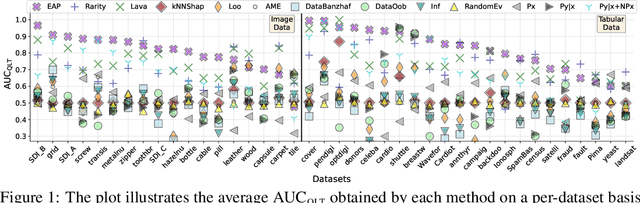
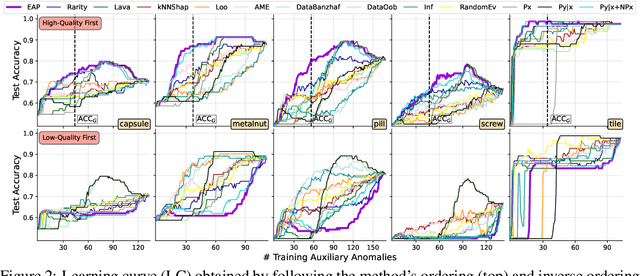
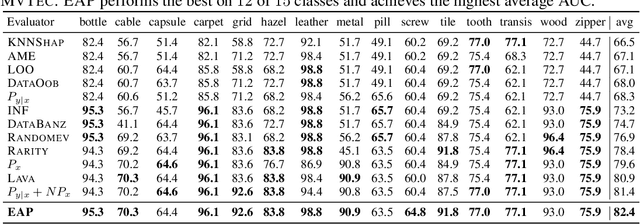
Anomaly detection is the task of identifying examples that do not behave as expected. Because anomalies are rare and unexpected events, collecting real anomalous examples is often challenging in several applications. In addition, learning an anomaly detector with limited (or no) anomalies often yields poor prediction performance. One option is to employ auxiliary synthetic anomalies to improve the model training. However, synthetic anomalies may be of poor quality: anomalies that are unrealistic or indistinguishable from normal samples may deteriorate the detector's performance. Unfortunately, no existing methods quantify the quality of auxiliary anomalies. We fill in this gap and propose the expected anomaly posterior (EAP), an uncertainty-based score function that measures the quality of auxiliary anomalies by quantifying the total uncertainty of an anomaly detector. Experimentally on 40 benchmark datasets of images and tabular data, we show that EAP outperforms 12 adapted data quality estimators in the majority of cases.
Deep Neural Network Benchmarks for Selective Classification
Jan 23, 2024With the increasing deployment of machine learning models in many socially-sensitive tasks, there is a growing demand for reliable and trustworthy predictions. One way to accomplish these requirements is to allow a model to abstain from making a prediction when there is a high risk of making an error. This requires adding a selection mechanism to the model, which selects those examples for which the model will provide a prediction. The selective classification framework aims to design a mechanism that balances the fraction of rejected predictions (i.e., the proportion of examples for which the model does not make a prediction) versus the improvement in predictive performance on the selected predictions. Multiple selective classification frameworks exist, most of which rely on deep neural network architectures. However, the empirical evaluation of the existing approaches is still limited to partial comparisons among methods and settings, providing practitioners with little insight into their relative merits. We fill this gap by benchmarking 18 baselines on a diverse set of 44 datasets that includes both image and tabular data. Moreover, there is a mix of binary and multiclass tasks. We evaluate these approaches using several criteria, including selective error rate, empirical coverage, distribution of rejected instance's classes, and performance on out-of-distribution instances. The results indicate that there is not a single clear winner among the surveyed baselines, and the best method depends on the users' objectives.
Unsupervised Anomaly Detection with Rejection
May 22, 2023


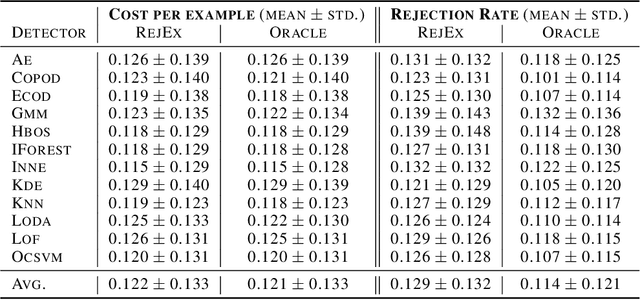
Anomaly detection aims at detecting unexpected behaviours in the data. Because anomaly detection is usually an unsupervised task, traditional anomaly detectors learn a decision boundary by employing heuristics based on intuitions, which are hard to verify in practice. This introduces some uncertainty, especially close to the decision boundary, that may reduce the user trust in the detector's predictions. A way to combat this is by allowing the detector to reject examples with high uncertainty (Learning to Reject). This requires employing a confidence metric that captures the distance to the decision boundary and setting a rejection threshold to reject low-confidence predictions. However, selecting a proper metric and setting the rejection threshold without labels are challenging tasks. In this paper, we solve these challenges by setting a constant rejection threshold on the stability metric computed by ExCeeD. Our insight relies on a theoretical analysis of such a metric. Moreover, setting a constant threshold results in strong guarantees: we estimate the test rejection rate, and derive a theoretical upper bound for both the rejection rate and the expected prediction cost. Experimentally, we show that our method outperforms some metric-based methods.
How to Allocate your Label Budget? Choosing between Active Learning and Learning to Reject in Anomaly Detection
Jan 07, 2023



Anomaly detection attempts at finding examples that deviate from the expected behaviour. Usually, anomaly detection is tackled from an unsupervised perspective because anomalous labels are rare and difficult to acquire. However, the lack of labels makes the anomaly detector have high uncertainty in some regions, which usually results in poor predictive performance or low user trust in the predictions. One can reduce such uncertainty by collecting specific labels using Active Learning (AL), which targets examples close to the detector's decision boundary. Alternatively, one can increase the user trust by allowing the detector to abstain from making highly uncertain predictions, which is called Learning to Reject (LR). One way to do this is by thresholding the detector's uncertainty based on where its performance is low, which requires labels to be evaluated. Although both AL and LR need labels, they work with different types of labels: AL seeks strategic labels, which are evidently biased, while LR requires i.i.d. labels to evaluate the detector's performance and set the rejection threshold. Because one usually has a unique label budget, deciding how to optimally allocate it is challenging. In this paper, we propose a mixed strategy that, given a budget of labels, decides in multiple rounds whether to use the budget to collect AL labels or LR labels. The strategy is based on a reward function that measures the expected gain when allocating the budget to either side. We evaluate our strategy on 18 benchmark datasets and compare it to some baselines.
Estimating the Contamination Factor's Distribution in Unsupervised Anomaly Detection
Oct 19, 2022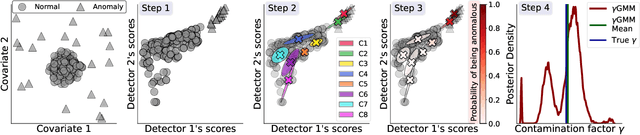
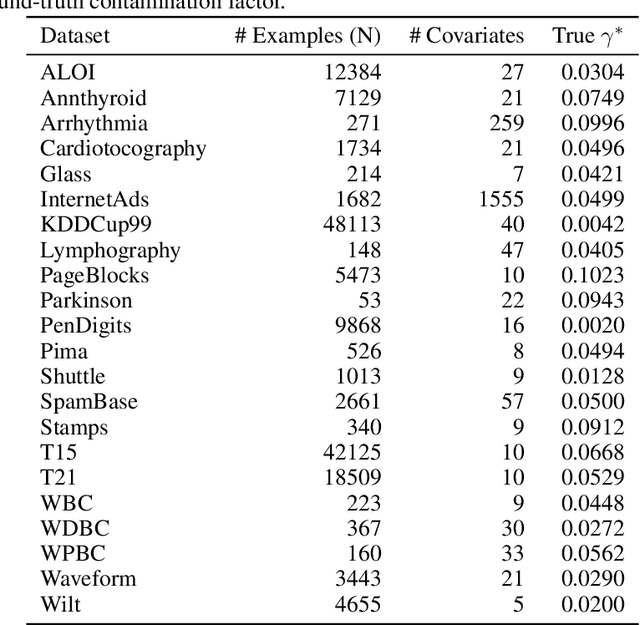
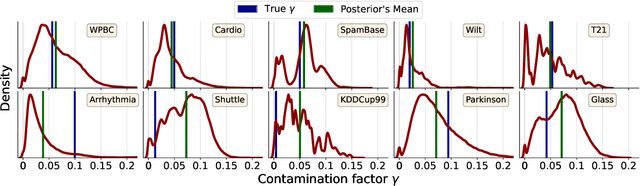
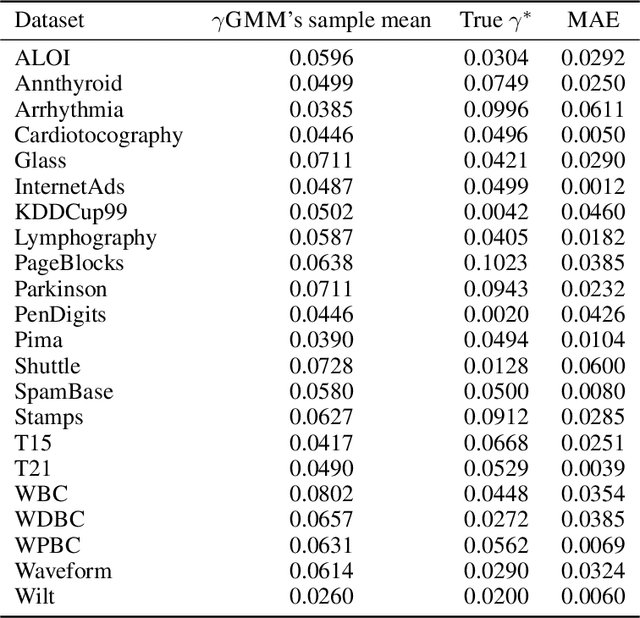
Anomaly detection methods identify examples that do not follow the expected behaviour, typically in an unsupervised fashion, by assigning real-valued anomaly scores to the examples based on various heuristics. These scores need to be transformed into actual predictions by thresholding, so that the proportion of examples marked as anomalies equals the expected proportion of anomalies, called contamination factor. Unfortunately, there are no good methods for estimating the contamination factor itself. We address this need from a Bayesian perspective, introducing a method for estimating the posterior distribution of the contamination factor of a given unlabeled dataset. We leverage on outputs of several anomaly detectors as a representation that already captures the basic notion of anomalousness and estimate the contamination using a specific mixture formulation. Empirically on 22 datasets, we show that the estimated distribution is well-calibrated and that setting the threshold using the posterior mean improves the anomaly detectors' performance over several alternative methods. All code is publicly available for full reproducibility.
Machine Learning with a Reject Option: A survey
Jul 23, 2021
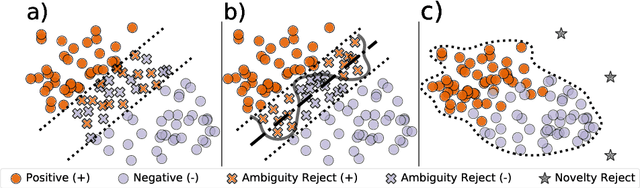
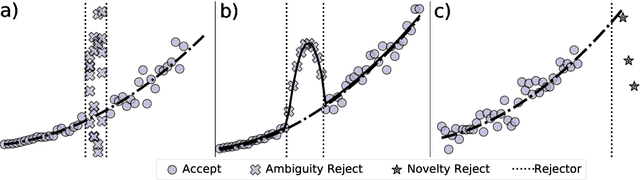

Machine learning models always make a prediction, even when it is likely to be inaccurate. This behavior should be avoided in many decision support applications, where mistakes can have severe consequences. Albeit already studied in 1970, machine learning with a reject option recently gained interest. This machine learning subfield enables machine learning models to abstain from making a prediction when likely to make a mistake. This survey aims to provide an overview on machine learning with a reject option. We introduce the conditions leading to two types of rejection, ambiguity and novelty rejection. Moreover, we define the existing architectures for models with a reject option, describe the standard learning strategies to train such models and relate traditional machine learning techniques to rejection. Additionally, we review strategies to evaluate a model's predictive and rejective quality. Finally, we provide examples of relevant application domains and show how machine learning with rejection relates to other machine learning research areas.