 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAY Diffusion: Styled Layout Diffusion Model for Diverse Layout-to-Image Generation
Mar 15, 2025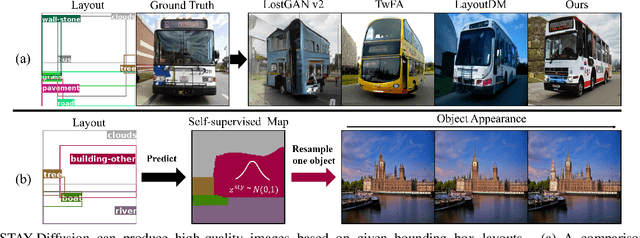
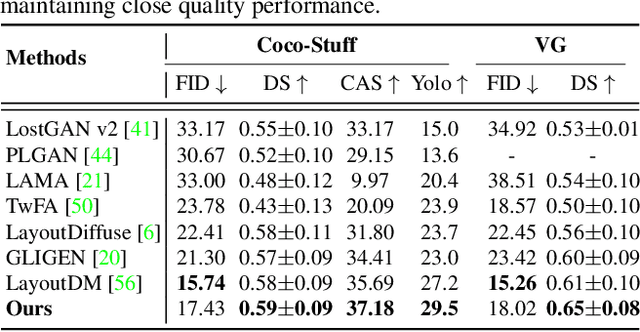
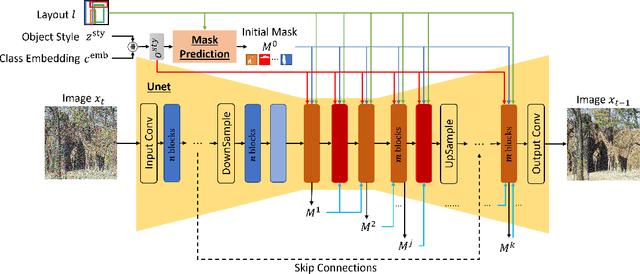
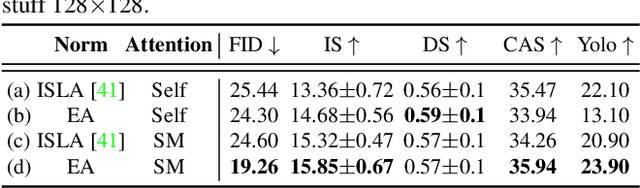
In layout-to-image (L2I) synthesis, controlled complex scenes are generated from coarse information like bounding boxes. Such a task is exciting to many downstream applications because the input layouts offer strong guidance to the generation process while remaining easily reconfigurable by humans. In this paper, we proposed STyled LAYout Diffusion (STAY Diffusion), a diffusion-based model that produces photo-realistic images and provides fine-grained control of stylized objects in scenes. Our approach learns a global condition for each layout, and a self-supervised semantic map for weight modulation using a novel Edge-Aware Normalization (EA Norm). A new Styled-Mask Attention (SM Attention) is also introduced to cross-condition the global condition and image feature for capturing the objects' relationships. These measures provide consistent guidance through the model, enabling more accurate and controllable image generation. Extensive benchmarking demonstrates that our STAY Diffusion presents high-quality images while surpassing previous state-of-the-art methods in generation diversity, accuracy, and controllability.
Uncertainty-aware Evaluation of Auxiliary Anomalies with the Expected Anomaly Posterior
May 22, 2024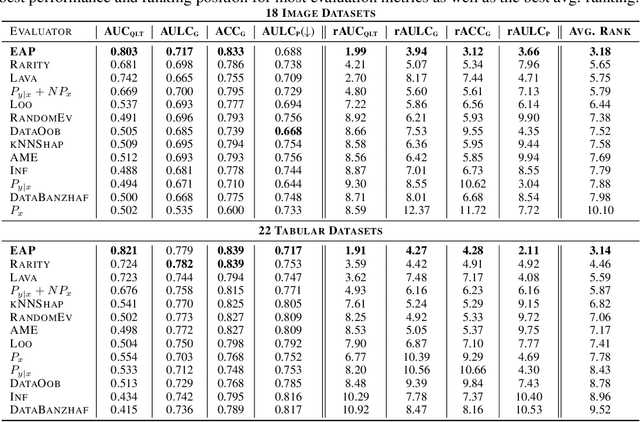
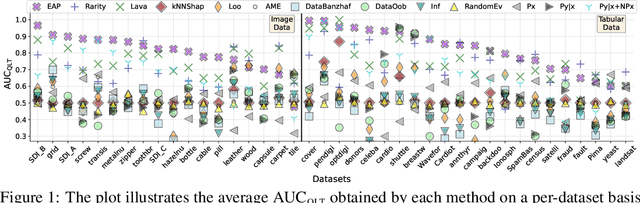
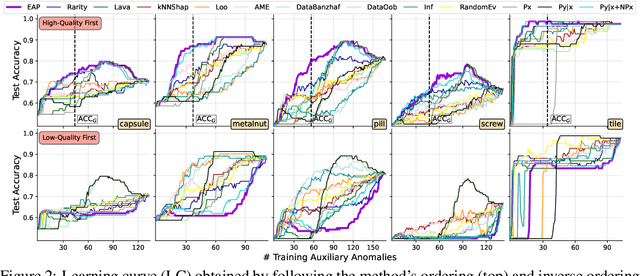
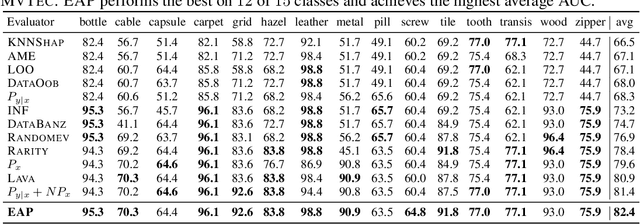
Anomaly detection is the task of identifying examples that do not behave as expected. Because anomalies are rare and unexpected events, collecting real anomalous examples is often challenging in several applications. In addition, learning an anomaly detector with limited (or no) anomalies often yields poor prediction performance. One option is to employ auxiliary synthetic anomalies to improve the model training. However, synthetic anomalies may be of poor quality: anomalies that are unrealistic or indistinguishable from normal samples may deteriorate the detector's performance. Unfortunately, no existing methods quantify the quality of auxiliary anomalies. We fill in this gap and propose the expected anomaly posterior (EAP), an uncertainty-based score function that measures the quality of auxiliary anomalies by quantifying the total uncertainty of an anomaly detector. Experimentally on 40 benchmark datasets of images and tabular data, we show that EAP outperforms 12 adapted data quality estimators in the majority of cases.
Improving the Effectiveness of Deep Generative Data
Nov 08, 2023



Recent deep generative models (DGMs) such as generative adversarial networks (GANs) and diffusion probabilistic models (DPMs) have shown their impressive ability in generating high-fidelity photorealistic images. Although looking appealing to human eyes, training a model on purely synthetic images for downstream image processing tasks like image classification often results in an undesired performance drop compared to training on real data. Previous works have demonstrated that enhancing a real dataset with synthetic images from DGMs can be beneficial. However, the improvements were subjected to certain circumstances and yet were not comparable to adding the same number of real images. In this work, we propose a new taxonomy to describe factors contributing to this commonly observed phenomenon and investigate it on the popular CIFAR-10 dataset. We hypothesize that the Content Gap accounts for a large portion of the performance drop when using synthetic images from DGM and propose strategies to better utilize them in downstream tasks. Extensive experiments on multiple datasets showcase that our method outperforms baselines on downstream classification tasks both in case of training on synthetic only (Synthetic-to-Real) and training on a mix of real and synthetic data (Data Augmentation), particularly in the data-scarce scenario.