 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVQ-VAE Based Digital Semantic Communication with Importance-Aware OFDM Transmission
Aug 12, 2025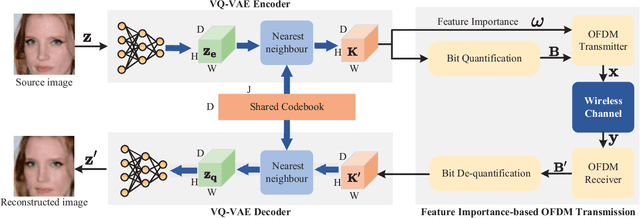
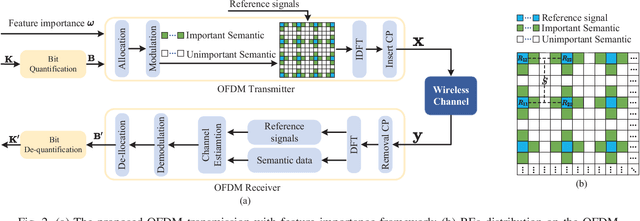
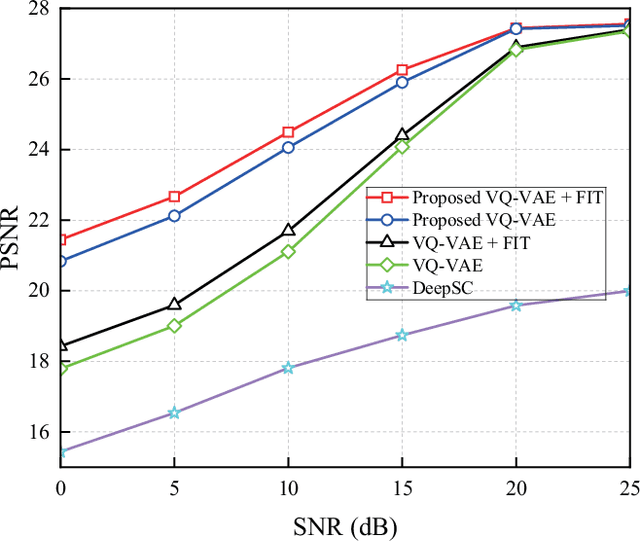
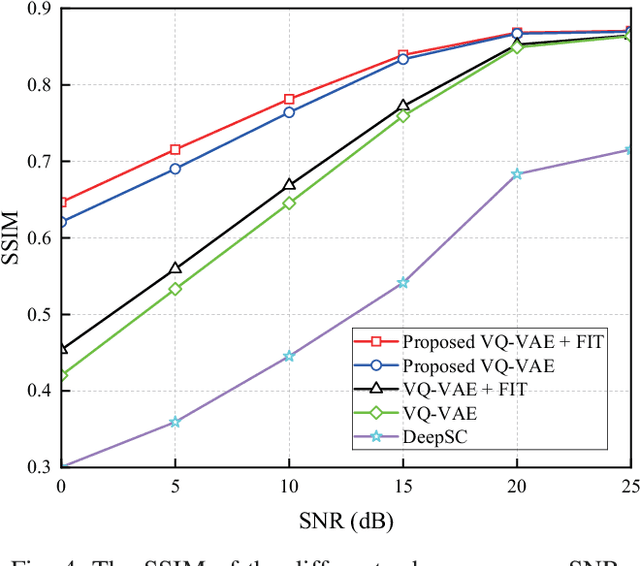
Semantic communication (SemCom) significantly reduces redundant data and improves transmission efficiency by extracting the latent features of information. However, most of the conventional deep learning-based SemCom systems focus on analog transmission and lack in compatibility with practical digital communications. This paper proposes a vector quantized-variational autoencoder (VQ-VAE) based digital SemCom system that directly transmits the semantic features and incorporates the importance-aware orthogonal frequency division multiplexing (OFDM) transmission to enhance the SemCom performance, where the VQ-VAE generates a discrete codebook shared between the transmitter and receiver. At transmitter, the latent semantic features are firstly extracted by VQ-VAE, and then the shared codebook is adopted to match these features, which are subsequently transformed into a discrete version to adapt the digital transmission. To protect the semantic information, an importance-aware OFDM transmission strategy is proposed to allocate the key features near the OFDM reference signals, where the feature importance is derived from the gradient-based method. At the receiver, the features are rematched with the shared codebook to further correct errors. Finally, experimental results demonstrate that our proposed scheme outperforms the conventional DeepSC and achieves better reconstruction performance under low SNR region.
Reference Signal-Based Waveform Design for Integrated Sensing and Communications System
Nov 12, 2024Integrated sensing and communications (ISAC) as one of the key technologies is capable of supporting high-speed communication and high-precision sensing for the upcoming 6G. This paper studies a waveform strategy by designing the orthogonal frequency division multiplexing (OFDM)-based reference signal (RS) for sensing and communication in ISAC system. We derive the closed-form expressions of Cram\'er-Rao Bound (CRB) for the distance and velocity estimations, and obtain the communication rate under the mean square error of channel estimation. Then, a weighted sum CRB minimization problem on the distance and velocity estimations is formulated by considering communication rate requirement and RS intervals constraints, which is a mixed-integer problem due to the discrete RS interval values. To solve this problem, some numerical methods are typically adopted to obtain the optimal solutions, whose computational complexity grow exponentially with the number of symbols and subcarriers of OFDM. Therefore, we propose a relaxation and approximation method to transform the original discrete problem into a continuous convex one and obtain the sub-optimal solutions. Finally, our proposed scheme is compared with the exhaustive search method in numerical simulations, which show slight gap between the obtained sub-optimal and optimal solutions, and this gap further decreases with large weight factor.
Anomaly Detection of Tabular Data Using LLMs
Jun 24, 2024Large language models (LLMs) have shown their potential in long-context understanding and mathematical reasoning. In this paper, we study the problem of using LLMs to detect tabular anomalies and show that pre-trained LLMs are zero-shot batch-level anomaly detectors. That is, without extra distribution-specific model fitting, they can discover hidden outliers in a batch of data, demonstrating their ability to identify low-density data regions. For LLMs that are not well aligned with anomaly detection and frequently output factual errors, we apply simple yet effective data-generating processes to simulate synthetic batch-level anomaly detection datasets and propose an end-to-end fine-tuning strategy to bring out the potential of LLMs in detecting real anomalies. Experiments on a large anomaly detection benchmark (ODDS) showcase i) GPT-4 has on-par performance with the state-of-the-art transductive learning-based anomaly detection methods and ii) the efficacy of our synthetic dataset and fine-tuning strategy in aligning LLMs to this task.
Uncertainty-aware Evaluation of Auxiliary Anomalies with the Expected Anomaly Posterior
May 22, 2024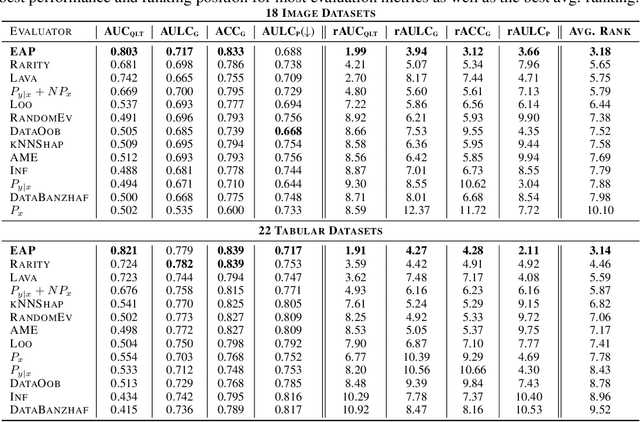
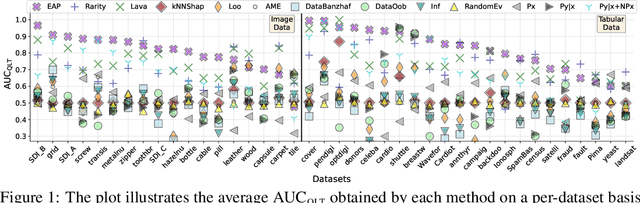
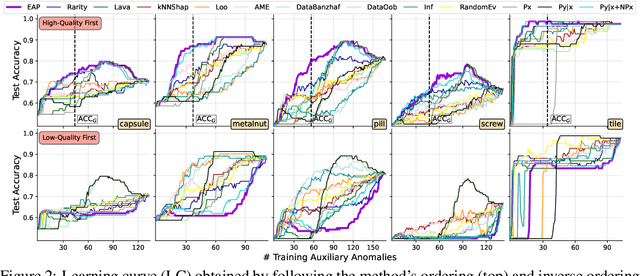
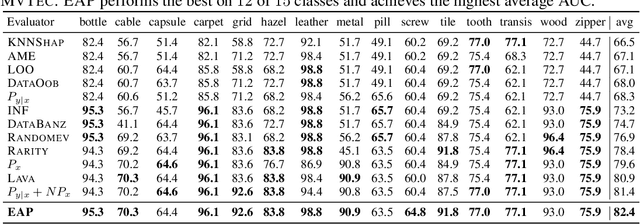
Anomaly detection is the task of identifying examples that do not behave as expected. Because anomalies are rare and unexpected events, collecting real anomalous examples is often challenging in several applications. In addition, learning an anomaly detector with limited (or no) anomalies often yields poor prediction performance. One option is to employ auxiliary synthetic anomalies to improve the model training. However, synthetic anomalies may be of poor quality: anomalies that are unrealistic or indistinguishable from normal samples may deteriorate the detector's performance. Unfortunately, no existing methods quantify the quality of auxiliary anomalies. We fill in this gap and propose the expected anomaly posterior (EAP), an uncertainty-based score function that measures the quality of auxiliary anomalies by quantifying the total uncertainty of an anomaly detector. Experimentally on 40 benchmark datasets of images and tabular data, we show that EAP outperforms 12 adapted data quality estimators in the majority of cases.
Model Selection of Anomaly Detectors in the Absence of Labeled Validation Data
Oct 16, 2023



Anomaly detection requires detecting abnormal samples in large unlabeled datasets. While progress in deep learning and the advent of foundation models has produced powerful unsupervised anomaly detection methods, their deployment in practice is often hindered by the lack of labeled data -- without it, the detection accuracy of an anomaly detector cannot be evaluated reliably. In this work, we propose a general-purpose framework for evaluating image-based anomaly detectors with synthetically generated validation data. Our method assumes access to a small support set of normal images which are processed with a pre-trained diffusion model (our proposed method requires no training or fine-tuning) to produce synthetic anomalies. When mixed with normal samples from the support set, the synthetic anomalies create detection tasks that compose a validation framework for anomaly detection evaluation and model selection. In an extensive empirical study, ranging from natural images to industrial applications, we find that our synthetic validation framework selects the same models and hyper-parameters as selection with a ground-truth validation set. In addition, we find that prompts selected by our method for CLIP-based anomaly detection outperforms all other prompt selection strategies, and leads to the overall best detection accuracy, even on the challenging MVTec-AD dataset.
Text-driven Prompt Generation for Vision-Language Models in Federated Learning
Oct 09, 2023



Prompt learning for vision-language models, e.g., CoOp, has shown great success in adapting CLIP to different downstream tasks, making it a promising solution for federated learning due to computational reasons. Existing prompt learning techniques replace hand-crafted text prompts with learned vectors that offer improvements on seen classes, but struggle to generalize to unseen classes. Our work addresses this challenge by proposing Federated Text-driven Prompt Generation (FedTPG), which learns a unified prompt generation network across multiple remote clients in a scalable manner. The prompt generation network is conditioned on task-related text input, thus is context-aware, making it suitable to generalize for both seen and unseen classes. Our comprehensive empirical evaluations on nine diverse image classification datasets show that our method is superior to existing federated prompt learning methods, that achieve overall better generalization on both seen and unseen classes and is also generalizable to unseen datasets.
Data Curation for Image Captioning with Text-to-Image Generative Models
May 05, 2023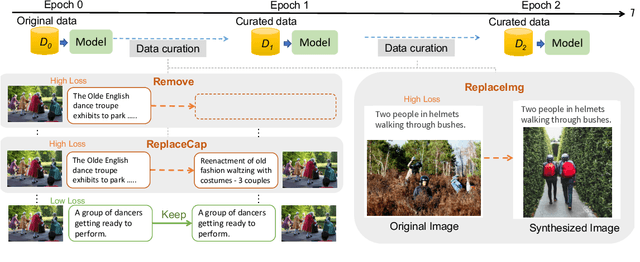
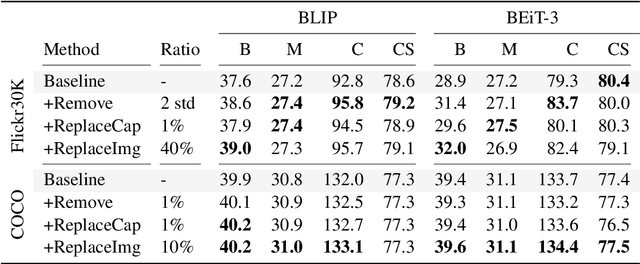

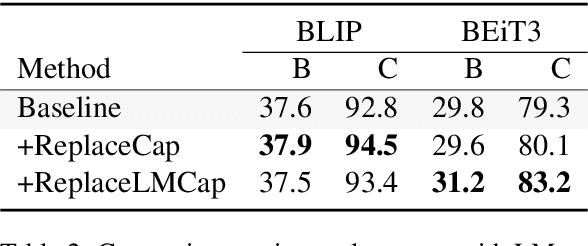
Recent advances in image captioning are mainly driven by large-scale vision-language pretraining, relying heavily on computational resources and increasingly large multimodal datasets. Instead of scaling up pretraining data, we ask whether it is possible to improve performance by improving the quality of the samples in existing datasets. We pursue this question through two approaches to data curation: one that assumes that some examples should be avoided due to mismatches between the image and caption, and one that assumes that the mismatch can be addressed by replacing the image, for which we use the state-of-the-art Stable Diffusion model. These approaches are evaluated using the BLIP model on MS COCO and Flickr30K in both finetuning and few-shot learning settings. Our simple yet effective approaches consistently outperform baselines, indicating that better image captioning models can be trained by curating existing resources. Finally, we conduct a human study to understand the errors made by the Stable Diffusion model and highlight directions for future work in text-to-image generation.
Theoretical Model Construction of Deformation-Force for Soft Grippers Part I: Co-rotational Modeling and Force Control for Design Optimization
Mar 23, 2023



Compliant grippers, owing to adaptivity and safety, have attracted considerable attention for unstructured grasping in real applications, such as industrial or logistic scenarios. However, accurate construction of the mathematical model depicting the bidirectional relationship between shape deformation and contact force for such grippers, such as the Fin-Ray grippers, remains stagnant to date. To address this research gap, this article devises, presents, and experimentally validates a universal bidirectional force-displacement mathematical model for compliant grippers based on the co-rotational concept, which endows such grippers with an intrinsic force sensing capability and offers a better insight into the design optimization. In Part 1 of the article, we introduce the fundamental theory of the co-rotational approach, where arbitrary large deformation of beam elements can be modeled. Its intrinsic principle enables the theoretical modeling to consider various types of configurations and key design parameters with very few assumptions made. Further, a force control algorithm is proposed, providing accurate displacement estimations of the gripper under external forces with minor computational loads. The performance of the proposed method is experimentally verified through comparison with Finite Element Analysis, where the influence of four key design parameters on the gripper s performance is investigated, facilitating systematical design optimization. Part 2 of this article demonstrating the force sensing capabilities and the effects of representative co-rotational modeling parameters on model accuracy is released in Google Drive.
Theoretical Model Construction of Deformation-Force for Soft Grippers Part II: Displacement Control Based Intrinsic Force Sensing
Mar 22, 2023



Compliant grasping is an essential capability for most robots in practical applications. For compliant robotic end-effectors that commonly appear in industrial or logistic scenarios, such as Fin-Ray gripper, it still remains challenging to build a bidirectional mathematical model that mutually maps the shape deformation and contact force. Part I of this article has constructed the force-displacement relationship for design optimization through the co-rotational theory with very few assumptions. In Part II, we further devise a detailed displacement-force mathematical model, enabling the compliant gripper to precisely estimate contact force sensor-free. Specifically, the proposed approach based on the co-rotational theory can calculate contact forces from deformations. The presented displacement-control algorithm elaborately investigates contact forces and provides force feedback for a force control system of a gripper, where deformation appears as displacements in contact points. Afterward, simulation experiments are conducted to evaluate the performance of the proposed model through comparisons with the finite-element analysis (FEA). Simulation results reveal that the proposed model accurately estimates contact force, with an average error of around 5% throughout all single/multiple node cases, regardless of various design parameters (Part I of this article is released in Google Drive).
Deep Anomaly Detection under Labeling Budget Constraints
Feb 15, 2023



Selecting informative data points for expert feedback can significantly improve the performance of anomaly detection (AD) in various contexts, such as medical diagnostics or fraud detection. In this paper, we determine a set of theoretical conditions under which anomaly scores generalize from labeled queries to unlabeled data. Motivated by these results, we propose a data labeling strategy with optimal data coverage under labeling budget constraints. In addition, we propose a new learning framework for semi-supervised AD. Extensive experiments on image, tabular, and video data sets show that our approach results in state-of-the-art semi-supervised AD performance under labeling budget constraints.