 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Foundation Models to Improve Lightweight Clients in Federated Learning
Nov 14, 2023Federated Learning (FL) is a distributed training paradigm that enables clients scattered across the world to cooperatively learn a global model without divulging confidential data. However, FL faces a significant challenge in the form of heterogeneous data distributions among clients, which leads to a reduction in performance and robustness. A recent approach to mitigating the impact of heterogeneous data distributions is through the use of foundation models, which offer better performance at the cost of larger computational overheads and slower inference speeds. We introduce foundation model distillation to assist in the federated training of lightweight client models and increase their performance under heterogeneous data settings while keeping inference costs low. Our results show improvement in the global model performance on a balanced testing set, which contains rarely observed samples, even under extreme non-IID client data distributions. We conduct a thorough evaluation of our framework with different foundation model backbones on CIFAR10, with varying degrees of heterogeneous data distributions ranging from class-specific data partitions across clients to dirichlet data sampling, parameterized by values between 0.01 and 1.0.
Text-driven Prompt Generation for Vision-Language Models in Federated Learning
Oct 09, 2023



Prompt learning for vision-language models, e.g., CoOp, has shown great success in adapting CLIP to different downstream tasks, making it a promising solution for federated learning due to computational reasons. Existing prompt learning techniques replace hand-crafted text prompts with learned vectors that offer improvements on seen classes, but struggle to generalize to unseen classes. Our work addresses this challenge by proposing Federated Text-driven Prompt Generation (FedTPG), which learns a unified prompt generation network across multiple remote clients in a scalable manner. The prompt generation network is conditioned on task-related text input, thus is context-aware, making it suitable to generalize for both seen and unseen classes. Our comprehensive empirical evaluations on nine diverse image classification datasets show that our method is superior to existing federated prompt learning methods, that achieve overall better generalization on both seen and unseen classes and is also generalizable to unseen datasets.
Revisiting Image Classifier Training for Improved Certified Robust Defense against Adversarial Patches
Jun 22, 2023Certifiably robust defenses against adversarial patches for image classifiers ensure correct prediction against any changes to a constrained neighborhood of pixels. PatchCleanser arXiv:2108.09135 [cs.CV], the state-of-the-art certified defense, uses a double-masking strategy for robust classification. The success of this strategy relies heavily on the model's invariance to image pixel masking. In this paper, we take a closer look at model training schemes to improve this invariance. Instead of using Random Cutout arXiv:1708.04552v2 [cs.CV] augmentations like PatchCleanser, we introduce the notion of worst-case masking, i.e., selecting masked images which maximize classification loss. However, finding worst-case masks requires an exhaustive search, which might be prohibitively expensive to do on-the-fly during training. To solve this problem, we propose a two-round greedy masking strategy (Greedy Cutout) which finds an approximate worst-case mask location with much less compute. We show that the models trained with our Greedy Cutout improves certified robust accuracy over Random Cutout in PatchCleanser across a range of datasets and architectures. Certified robust accuracy on ImageNet with a ViT-B16-224 model increases from 58.1\% to 62.3\% against a 3\% square patch applied anywhere on the image.
Defending Multimodal Fusion Models against Single-Source Adversaries
Jun 25, 2022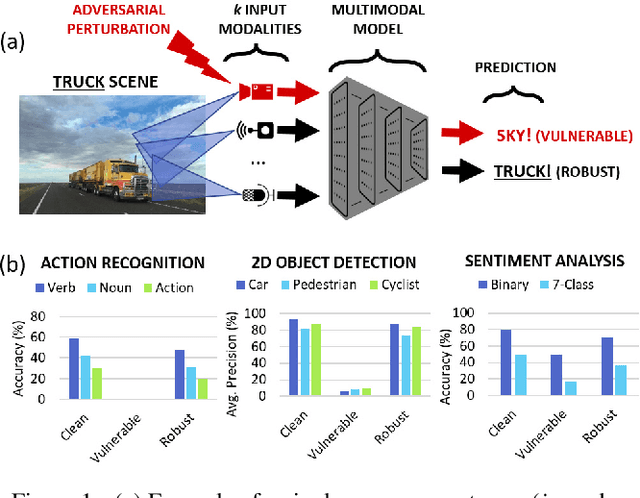

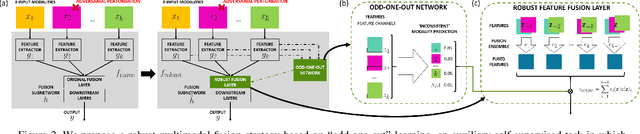
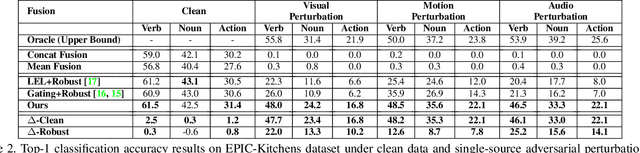
Beyond achieving high performance across many vision tasks, multimodal models are expected to be robust to single-source faults due to the availability of redundant information between modalities. In this paper, we investigate the robustness of multimodal neural networks against worst-case (i.e., adversarial) perturbations on a single modality. We first show that standard multimodal fusion models are vulnerable to single-source adversaries: an attack on any single modality can overcome the correct information from multiple unperturbed modalities and cause the model to fail. This surprising vulnerability holds across diverse multimodal tasks and necessitates a solution. Motivated by this finding, we propose an adversarially robust fusion strategy that trains the model to compare information coming from all the input sources, detect inconsistencies in the perturbed modality compared to the other modalities, and only allow information from the unperturbed modalities to pass through. Our approach significantly improves on state-of-the-art methods in single-source robustness, achieving gains of 7.8-25.2% on action recognition, 19.7-48.2% on object detection, and 1.6-6.7% on sentiment analysis, without degrading performance on unperturbed (i.e., clean) data.
Accelerating Road Sign Ground Truth Construction with Knowledge Graph and Machine Learning
Dec 04, 2020
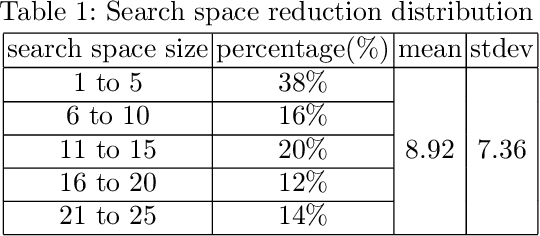


Having a comprehensive, high-quality dataset of road sign annotation is critical to the success of AI-based Road Sign Recognition (RSR) systems. In practice, annotators often face difficulties in learning road sign systems of different countries; hence, the tasks are often time-consuming and produce poor results. We propose a novel approach using knowledge graphs and a machine learning algorithm - variational prototyping-encoder (VPE) - to assist human annotators in classifying road signs effectively. Annotators can query the Road Sign Knowledge Graph using visual attributes and receive closest matching candidates suggested by the VPE model. The VPE model uses the candidates from the knowledge graph and a real sign image patch as inputs. We show that our knowledge graph approach can reduce sign search space by 98.9%. Furthermore, with VPE, our system can propose the correct single candidate for 75% of signs in the tested datasets, eliminating the human search effort entirely in those cases.
* 12 pages, 5 figures
Crossing You in Style: Cross-modal Style Transfer from Music to Visual Arts
Sep 17, 2020


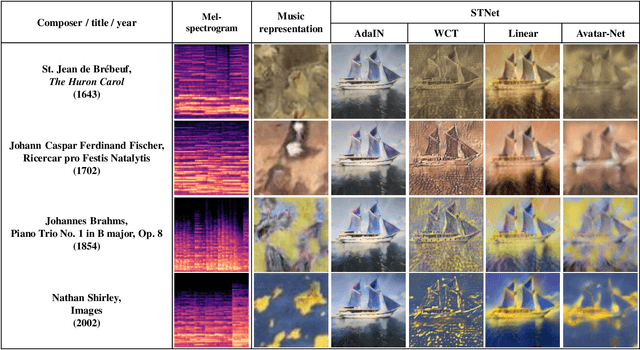
Music-to-visual style transfer is a challenging yet important cross-modal learning problem in the practice of creativity. Its major difference from the traditional image style transfer problem is that the style information is provided by music rather than images. Assuming that musical features can be properly mapped to visual contents through semantic links between the two domains, we solve the music-to-visual style transfer problem in two steps: music visualization and style transfer. The music visualization network utilizes an encoder-generator architecture with a conditional generative adversarial network to generate image-based music representations from music data. This network is integrated with an image style transfer method to accomplish the style transfer process. Experiments are conducted on WikiArt-IMSLP, a newly compiled dataset including Western music recordings and paintings listed by decades. By utilizing such a label to learn the semantic connection between paintings and music, we demonstrate that the proposed framework can generate diverse image style representations from a music piece, and these representations can unveil certain art forms of the same era. Subjective testing results also emphasize the role of the era label in improving the perceptual quality on the compatibility between music and visual content.
Learning in Confusion: Batch Active Learning with Noisy Oracle
Sep 27, 2019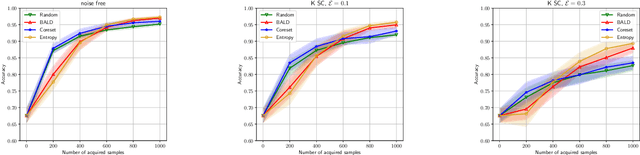
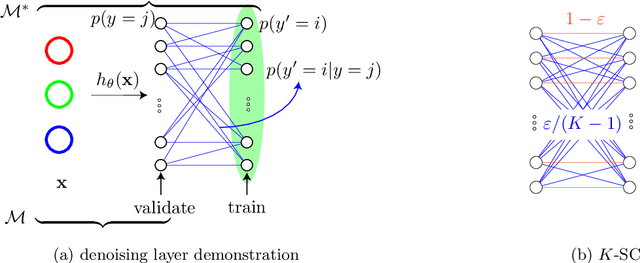


We study the problem of training machine learning models incrementally using active learning with access to imperfect or noisy oracles. We specifically consider the setting of batch active learning, in which multiple samples are selected as opposed to a single sample as in classical settings so as to reduce the training overhead. Our approach bridges between uniform randomness and score based importance sampling of clusters when selecting a batch of new samples. Experiments on benchmark image classification datasets (MNIST, SVHN, and CIFAR10) shows improvement over existing active learning strategies. We introduce an extra denoising layer to deep networks to make active learning robust to label noises and show significant improvements.
DeepBbox: Accelerating Precise Ground Truth Generation for Autonomous Driving Datasets
Aug 29, 2019
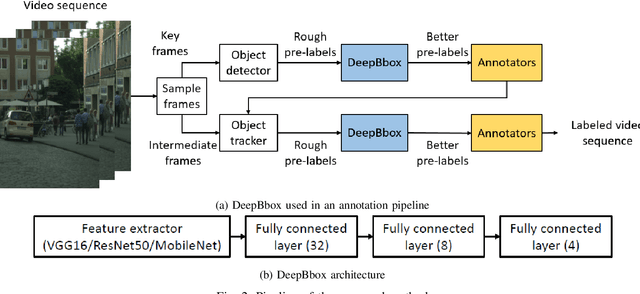
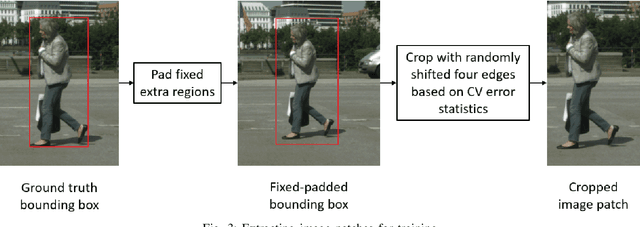

Autonomous driving requires various computer vision algorithms, such as object detection and tracking.Precisely-labeled datasets (i.e., objects are fully contained in bounding boxes with only a few extra pixels) are preferred for training such algorithms, so that the algorithms can detect exact locations of the objects. However, it is very time-consuming and hence expensive to generate precise labels for image sequences at scale. In this paper, we propose DeepBbox, an algorithm that corrects loose object labels into right bounding boxes to reduce human annotation efforts. We use Cityscapes dataset to show annotation efficiency and accuracy improvement using DeepBbox. Experimental results show that, with DeepBbox,we can increase the number of object edges that are labeled automatically (within 1\% error) by 50% to reduce manual annotation time.