 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepBbox: Accelerating Precise Ground Truth Generation for Autonomous Driving Datasets
Paper and Code
Aug 29, 2019
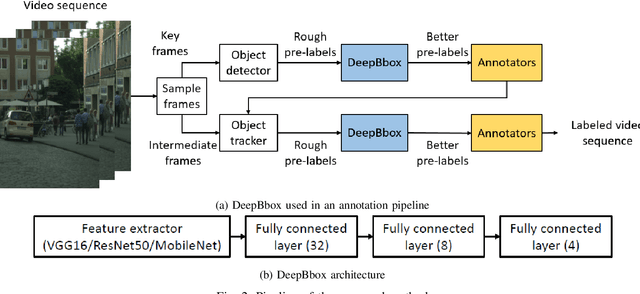
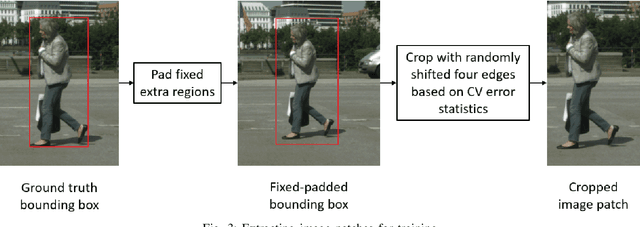

Autonomous driving requires various computer vision algorithms, such as object detection and tracking.Precisely-labeled datasets (i.e., objects are fully contained in bounding boxes with only a few extra pixels) are preferred for training such algorithms, so that the algorithms can detect exact locations of the objects. However, it is very time-consuming and hence expensive to generate precise labels for image sequences at scale. In this paper, we propose DeepBbox, an algorithm that corrects loose object labels into right bounding boxes to reduce human annotation efforts. We use Cityscapes dataset to show annotation efficiency and accuracy improvement using DeepBbox. Experimental results show that, with DeepBbox,we can increase the number of object edges that are labeled automatically (within 1\% error) by 50% to reduce manual annotation time.