 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Road Sign Ground Truth Construction with Knowledge Graph and Machine Learning
Dec 04, 2020
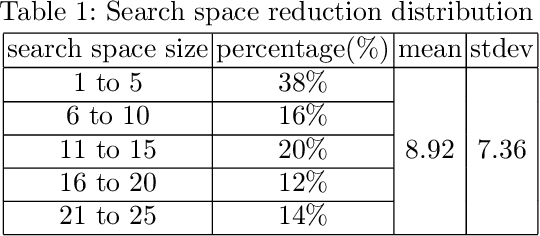


Having a comprehensive, high-quality dataset of road sign annotation is critical to the success of AI-based Road Sign Recognition (RSR) systems. In practice, annotators often face difficulties in learning road sign systems of different countries; hence, the tasks are often time-consuming and produce poor results. We propose a novel approach using knowledge graphs and a machine learning algorithm - variational prototyping-encoder (VPE) - to assist human annotators in classifying road signs effectively. Annotators can query the Road Sign Knowledge Graph using visual attributes and receive closest matching candidates suggested by the VPE model. The VPE model uses the candidates from the knowledge graph and a real sign image patch as inputs. We show that our knowledge graph approach can reduce sign search space by 98.9%. Furthermore, with VPE, our system can propose the correct single candidate for 75% of signs in the tested datasets, eliminating the human search effort entirely in those cases.
* 12 pages, 5 figures
DeepBbox: Accelerating Precise Ground Truth Generation for Autonomous Driving Datasets
Aug 29, 2019
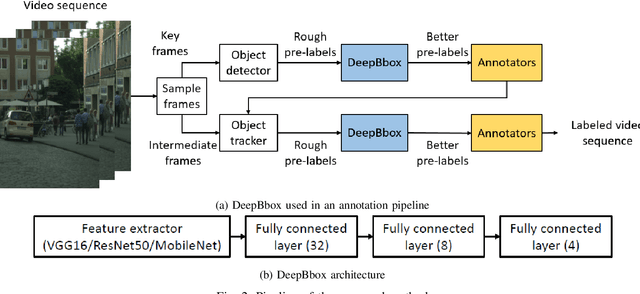
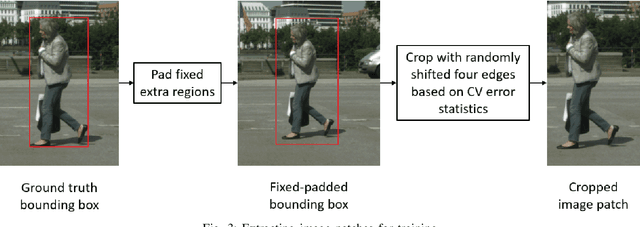

Autonomous driving requires various computer vision algorithms, such as object detection and tracking.Precisely-labeled datasets (i.e., objects are fully contained in bounding boxes with only a few extra pixels) are preferred for training such algorithms, so that the algorithms can detect exact locations of the objects. However, it is very time-consuming and hence expensive to generate precise labels for image sequences at scale. In this paper, we propose DeepBbox, an algorithm that corrects loose object labels into right bounding boxes to reduce human annotation efforts. We use Cityscapes dataset to show annotation efficiency and accuracy improvement using DeepBbox. Experimental results show that, with DeepBbox,we can increase the number of object edges that are labeled automatically (within 1\% error) by 50% to reduce manual annotation time.