 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausalPulse: An Industrial-Grade Neurosymbolic Multi-Agent Copilot for Causal Diagnostics in Smart Manufacturing
Mar 31, 2026Modern manufacturing environments demand real-time, trustworthy, and interpretable root-cause insights to sustain productivity and quality. Traditional analytics pipelines often treat anomaly detection, causal inference, and root-cause analysis as isolated stages, limiting scalability and explainability. In this work, we present CausalPulse, an industry-grade multi-agent copilot that automates causal diagnostics in smart manufacturing. It unifies anomaly detection, causal discovery, and reasoning through a neurosymbolic architecture built on standardized agentic protocols. CausalPulse is being deployed in a Robert Bosch manufacturing plant, integrating seamlessly with existing monitoring workflows and supporting real-time operation at production scale. Evaluations on both public (Future Factories) and proprietary (Planar Sensor Element) datasets show high reliability, achieving overall success rates of 98.0% and 98.73%. Per-criterion success rates reached 98.75% for planning and tool use, 97.3% for self-reflection, and 99.2% for collaboration. Runtime experiments report end-to-end latency of 50-60s per diagnostic workflow with near-linear scalability (R^2=0.97), confirming real-time readiness. Comparison with existing industrial copilots highlights distinct advantages in modularity, extensibility, and deployment maturity. These results demonstrate how CausalPulse's modular, human-in-the-loop design enables reliable, interpretable, and production-ready automation for next-generation manufacturing.
Knowledge Graphs of Driving Scenes to Empower the Emerging Capabilities of Neurosymbolic AI
Nov 05, 2024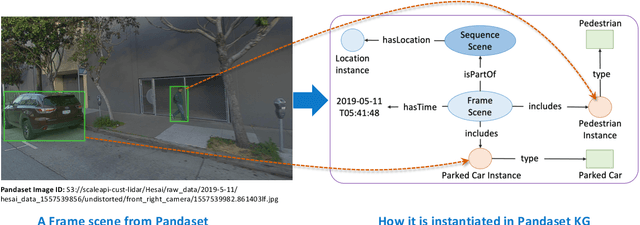
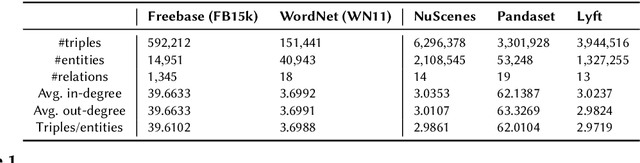
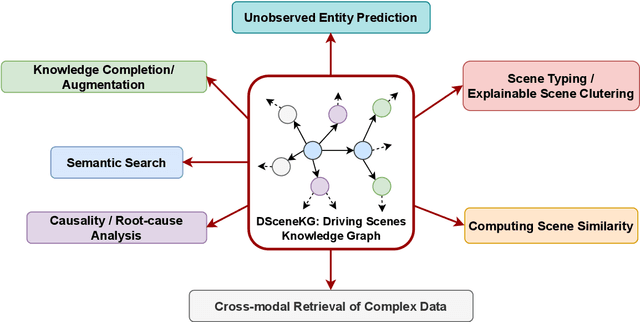
In the era of Generative AI, Neurosymbolic AI is emerging as a powerful approach for tasks spanning from perception to cognition. The use of Neurosymbolic AI has been shown to achieve enhanced capabilities, including improved grounding, alignment, explainability, and reliability. However, due to its nascent stage, there is a lack of widely available real-world benchmark datasets tailored to Neurosymbolic AI tasks. To address this gap and support the evaluation of current and future methods, we introduce DSceneKG -- a suite of knowledge graphs of driving scenes built from real-world, high-quality scenes from multiple open autonomous driving datasets. In this article, we detail the construction process of DSceneKG and highlight its application in seven different tasks. DSceneKG is publicly accessible at: https://github.com/ruwantw/DSceneKG
CausalDisco: Causal discovery using knowledge graph link prediction
Apr 23, 2024
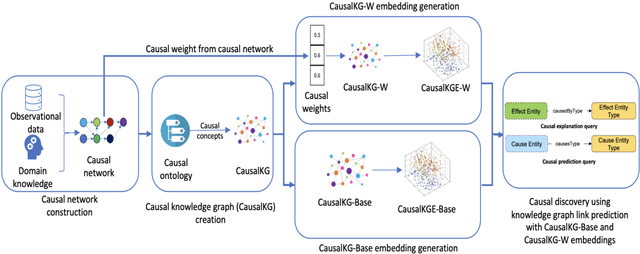

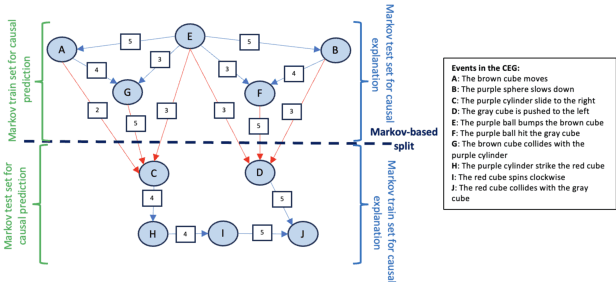
Causal discovery is a process of discovering new causal relations from observational data. Traditional causal discovery methods often suffer from issues related to missing data To address these issues, this paper presents a novel approach called CausalDisco that formulates causal discovery as a knowledge graph completion problem. More specifically, the task of discovering causal relations is mapped to the task of knowledge graph link prediction. CausalDisco supports two types of discovery: causal explanation and causal prediction. The causal relations have weights representing the strength of the causal association between entities in the knowledge graph. An evaluation of this approach uses a benchmark dataset of simulated videos for causal reasoning, CLEVRER-Humans, and compares the performance of multiple knowledge graph embedding algorithms. In addition, two distinct dataset splitting approaches are utilized within the evaluation: (1) random-based split, which is the method typically used to evaluate link prediction algorithms, and (2) Markov-based split, a novel data split technique for evaluating link prediction that utilizes the Markovian property of the causal relation. Results show that using weighted causal relations improves causal discovery over the baseline without weighted relations.
Relation-based Motion Prediction using Traffic Scene Graphs
Nov 24, 2022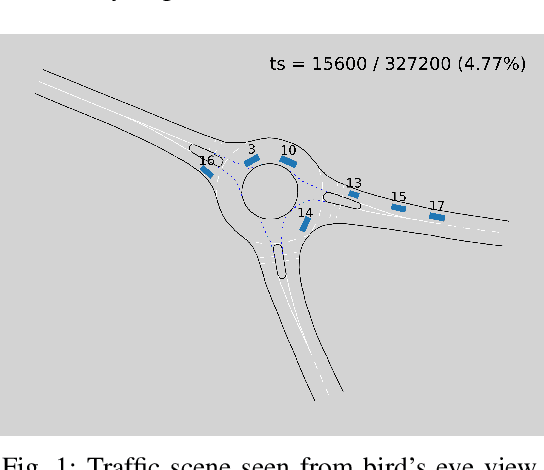
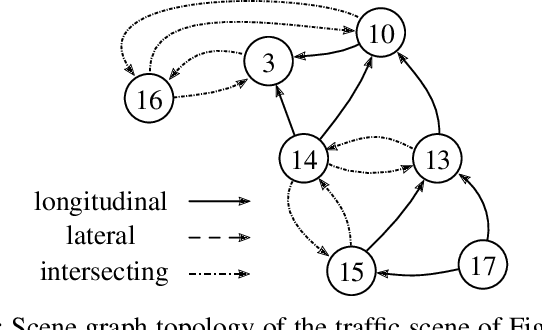
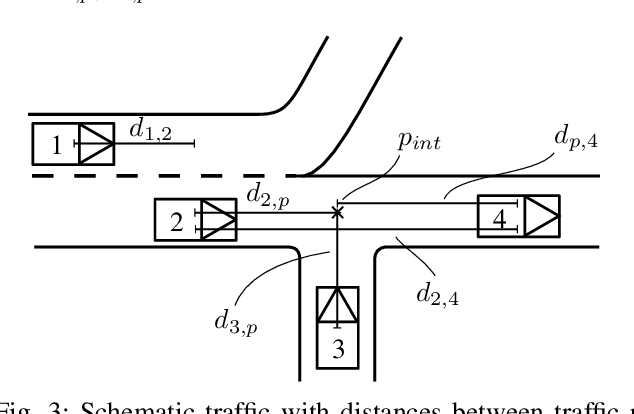
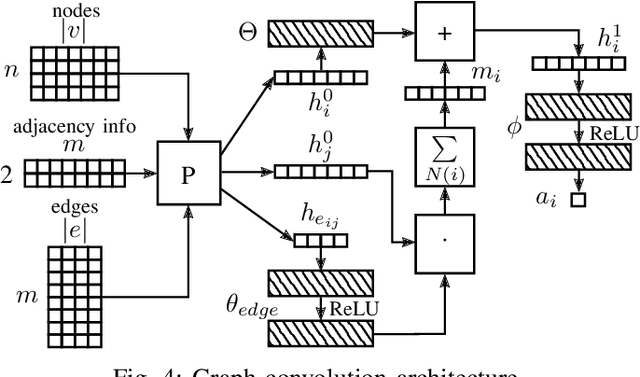
Representing relevant information of a traffic scene and understanding its environment is crucial for the success of autonomous driving. Modeling the surrounding of an autonomous car using semantic relations, i.e., how different traffic participants relate in the context of traffic rule based behaviors, is hardly been considered in previous work. This stems from the fact that these relations are hard to extract from real-world traffic scenes. In this work, we model traffic scenes in a form of spatial semantic scene graphs for various different predictions about the traffic participants, e.g., acceleration and deceleration. Our learning and inference approach uses Graph Neural Networks (GNNs) and shows that incorporating explicit information about the spatial semantic relations between traffic participants improves the predicdtion results. Specifically, the acceleration prediction of traffic participants is improved by up to 12% compared to the baselines, which do not exploit this explicit information. Furthermore, by including additional information about previous scenes, we achieve 73% improvements.
Knowledge-based Entity Prediction for Improved Machine Perception in Autonomous Systems
Mar 30, 2022
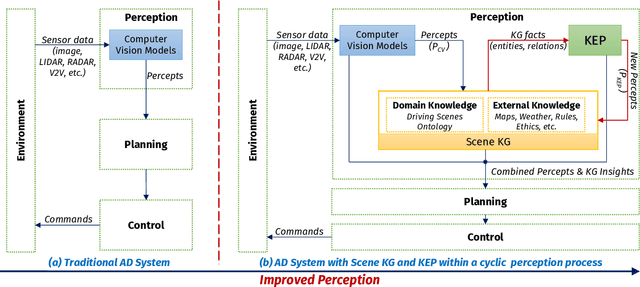
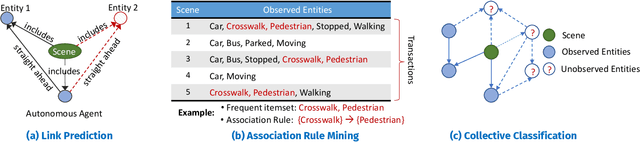
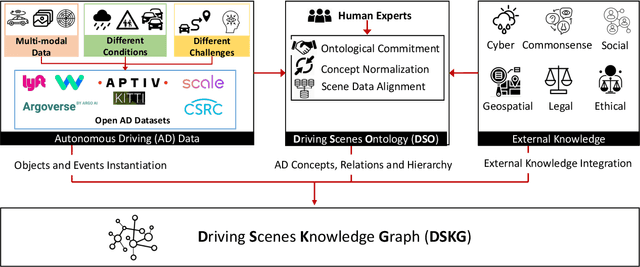
Knowledge-based entity prediction (KEP) is a novel task that aims to improve machine perception in autonomous systems. KEP leverages relational knowledge from heterogeneous sources in predicting potentially unrecognized entities. In this paper, we provide a formal definition of KEP as a knowledge completion task. Three potential solutions are then introduced, which employ several machine learning and data mining techniques. Finally, the applicability of KEP is demonstrated on two autonomous systems from different domains; namely, autonomous driving and smart manufacturing. We argue that in complex real-world systems, the use of KEP would significantly improve machine perception while pushing the current technology one step closer to achieving the full autonomy.
Accelerating Road Sign Ground Truth Construction with Knowledge Graph and Machine Learning
Dec 04, 2020


Having a comprehensive, high-quality dataset of road sign annotation is critical to the success of AI-based Road Sign Recognition (RSR) systems. In practice, annotators often face difficulties in learning road sign systems of different countries; hence, the tasks are often time-consuming and produce poor results. We propose a novel approach using knowledge graphs and a machine learning algorithm - variational prototyping-encoder (VPE) - to assist human annotators in classifying road signs effectively. Annotators can query the Road Sign Knowledge Graph using visual attributes and receive closest matching candidates suggested by the VPE model. The VPE model uses the candidates from the knowledge graph and a real sign image patch as inputs. We show that our knowledge graph approach can reduce sign search space by 98.9%. Furthermore, with VPE, our system can propose the correct single candidate for 75% of signs in the tested datasets, eliminating the human search effort entirely in those cases.
* 12 pages, 5 figures
Neuro-symbolic Architectures for Context Understanding
Mar 09, 2020

Computational context understanding refers to an agent's ability to fuse disparate sources of information for decision-making and is, therefore, generally regarded as a prerequisite for sophisticated machine reasoning capabilities, such as in artificial intelligence (AI). Data-driven and knowledge-driven methods are two classical techniques in the pursuit of such machine sense-making capability. However, while data-driven methods seek to model the statistical regularities of events by making observations in the real-world, they remain difficult to interpret and they lack mechanisms for naturally incorporating external knowledge. Conversely, knowledge-driven methods, combine structured knowledge bases, perform symbolic reasoning based on axiomatic principles, and are more interpretable in their inferential processing; however, they often lack the ability to estimate the statistical salience of an inference. To combat these issues, we propose the use of hybrid AI methodology as a general framework for combining the strengths of both approaches. Specifically, we inherit the concept of neuro-symbolism as a way of using knowledge-bases to guide the learning progress of deep neural networks. We further ground our discussion in two applications of neuro-symbolism and, in both cases, show that our systems maintain interpretability while achieving comparable performance, relative to the state-of-the-art.
An Evaluation of Knowledge Graph Embeddings for Autonomous Driving Data: Experience and Practice
Feb 29, 2020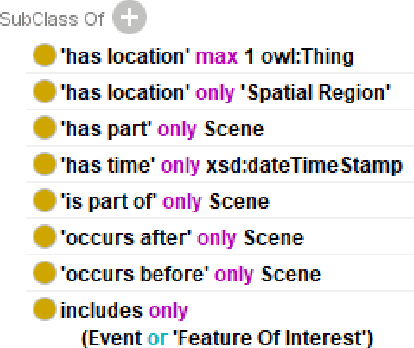
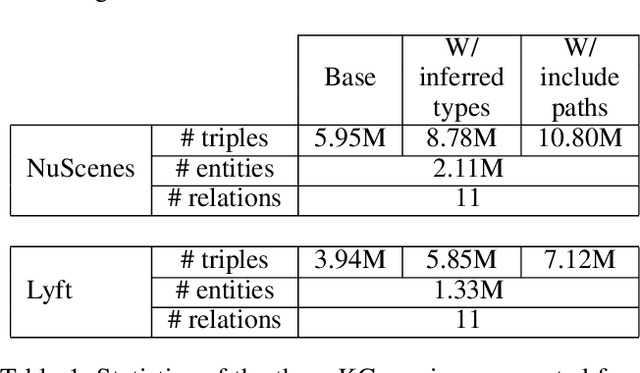
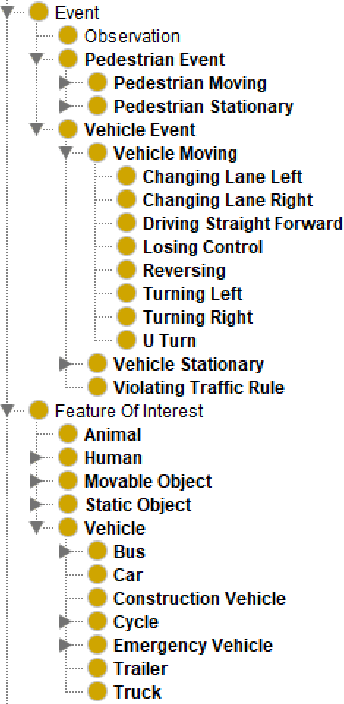
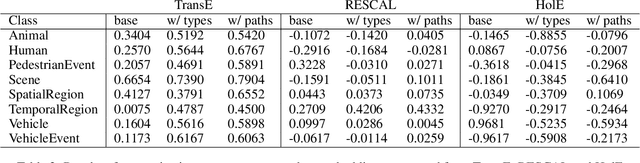
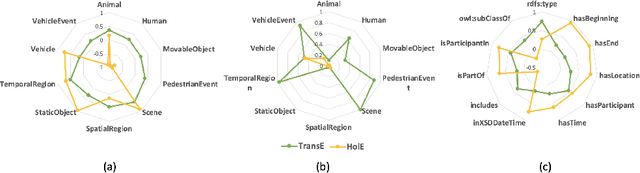
The autonomous driving (AD) industry is exploring the use of knowledge graphs (KGs) to manage the vast amount of heterogeneous data generated from vehicular sensors. The various types of equipped sensors include video, LIDAR and RADAR. Scene understanding is an important topic in AD which requires consideration of various aspects of a scene, such as detected objects, events, time and location. Recent work on knowledge graph embeddings (KGEs) - an approach that facilitates neuro-symbolic fusion - has shown to improve the predictive performance of machine learning models. With the expectation that neuro-symbolic fusion through KGEs will improve scene understanding, this research explores the generation and evaluation of KGEs for autonomous driving data. We also present an investigation of the relationship between the level of informational detail in a KG and the quality of its derivative embeddings. By systematically evaluating KGEs along four dimensions -- i.e. quality metrics, KG informational detail, algorithms, and datasets -- we show that (1) higher levels of informational detail in KGs lead to higher quality embeddings, (2) type and relation semantics are better captured by the semantic transitional distance-based TransE algorithm, and (3) some metrics, such as coherence measure, may not be suitable for intrinsically evaluating KGEs in this domain. Additionally, we also present an (early) investigation of the usefulness of KGEs for two use-cases in the AD domain.
Semantic, Cognitive, and Perceptual Computing: Advances toward Computing for Human Experience
Oct 20, 2015The World Wide Web continues to evolve and serve as the infrastructure for carrying massive amounts of multimodal and multisensory observations. These observations capture various situations pertinent to people's needs and interests along with all their idiosyncrasies. To support human-centered computing that empower people in making better and timely decisions, we look towards computation that is inspired by human perception and cognition. Toward this goal, we discuss computing paradigms of semantic computing, cognitive computing, and an emerging aspect of computing, which we call perceptual computing. In our view, these offer a continuum to make the most out of vast, growing, and diverse data pertinent to human needs and interests. We propose details of perceptual computing characterized by interpretation and exploration operations comparable to the interleaving of bottom and top brain processing. This article consists of two parts. First we describe semantic computing, cognitive computing, and perceptual computing to lay out distinctions while acknowledging their complementary capabilities. We then provide a conceptual overview of the newest of these three paradigms--perceptual computing. For further insights, we focus on an application scenario of asthma management converting massive, heterogeneous and multimodal (big) data into actionable information or smart data.