 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Generalisation Between Humans and Machines
Nov 23, 2024



Recent advances in AI -- including generative approaches -- have resulted in technology that can support humans in scientific discovery and decision support but may also disrupt democracies and target individuals. The responsible use of AI increasingly shows the need for human-AI teaming, necessitating effective interaction between humans and machines. A crucial yet often overlooked aspect of these interactions is the different ways in which humans and machines generalise. In cognitive science, human generalisation commonly involves abstraction and concept learning. In contrast, AI generalisation encompasses out-of-domain generalisation in machine learning, rule-based reasoning in symbolic AI, and abstraction in neuro-symbolic AI. In this perspective paper, we combine insights from AI and cognitive science to identify key commonalities and differences across three dimensions: notions of generalisation, methods for generalisation, and evaluation of generalisation. We map the different conceptualisations of generalisation in AI and cognitive science along these three dimensions and consider their role in human-AI teaming. This results in interdisciplinary challenges across AI and cognitive science that must be tackled to provide a foundation for effective and cognitively supported alignment in human-AI teaming scenarios.
Cognitive LLMs: Towards Integrating Cognitive Architectures and Large Language Models for Manufacturing Decision-making
Aug 17, 2024



Resolving the dichotomy between the human-like yet constrained reasoning processes of Cognitive Architectures and the broad but often noisy inference behavior of Large Language Models (LLMs) remains a challenging but exciting pursuit, for enabling reliable machine reasoning capabilities in production systems. Because Cognitive Architectures are famously developed for the purpose of modeling the internal mechanisms of human cognitive decision-making at a computational level, new investigations consider the goal of informing LLMs with the knowledge necessary for replicating such processes, e.g., guided perception, memory, goal-setting, and action. Previous approaches that use LLMs for grounded decision-making struggle with complex reasoning tasks that require slower, deliberate cognition over fast and intuitive inference -- reporting issues related to the lack of sufficient grounding, as in hallucination. To resolve these challenges, we introduce LLM-ACTR, a novel neuro-symbolic architecture that provides human-aligned and versatile decision-making by integrating the ACT-R Cognitive Architecture with LLMs. Our framework extracts and embeds knowledge of ACT-R's internal decision-making process as latent neural representations, injects this information into trainable LLM adapter layers, and fine-tunes the LLMs for downstream prediction. Our experiments on novel Design for Manufacturing tasks show both improved task performance as well as improved grounded decision-making capability of our approach, compared to LLM-only baselines that leverage chain-of-thought reasoning strategies.
Enhancing Vision-Language Models with Scene Graphs for Traffic Accident Understanding
Jul 08, 2024



Recognizing a traffic accident is an essential part of any autonomous driving or road monitoring system. An accident can appear in a wide variety of forms, and understanding what type of accident is taking place may be useful to prevent it from reoccurring. The task of being able to classify a traffic scene as a specific type of accident is the focus of this work. We approach the problem by likening a traffic scene to a graph, where objects such as cars can be represented as nodes, and relative distances and directions between them as edges. This representation of an accident can be referred to as a scene graph, and is used as input for an accident classifier. Better results can be obtained with a classifier that fuses the scene graph input with representations from vision and language. This work introduces a multi-stage, multimodal pipeline to pre-process videos of traffic accidents, encode them as scene graphs, and align this representation with vision and language modalities for accident classification. When trained on 4 classes, our method achieves a balanced accuracy score of 57.77% on an (unbalanced) subset of the popular Detection of Traffic Anomaly (DoTA) benchmark, representing an increase of close to 5 percentage points from the case where scene graph information is not taken into account.
Enabling High-Level Machine Reasoning with Cognitive Neuro-Symbolic Systems
Nov 13, 2023High-level reasoning can be defined as the capability to generalize over knowledge acquired via experience, and to exhibit robust behavior in novel situations. Such form of reasoning is a basic skill in humans, who seamlessly use it in a broad spectrum of tasks, from language communication to decision making in complex situations. When it manifests itself in understanding and manipulating the everyday world of objects and their interactions, we talk about common sense or commonsense reasoning. State-of-the-art AI systems don't possess such capability: for instance, Large Language Models have recently become popular by demonstrating remarkable fluency in conversing with humans, but they still make trivial mistakes when probed for commonsense competence; on a different level, performance degradation outside training data prevents self-driving vehicles to safely adapt to unseen scenarios, a serious and unsolved problem that limits the adoption of such technology. In this paper we propose to enable high-level reasoning in AI systems by integrating cognitive architectures with external neuro-symbolic components. We illustrate a hybrid framework centered on ACT-R and we discuss the role of generative models in recent and future applications.
Traffic-Domain Video Question Answering with Automatic Captioning
Jul 18, 2023


Video Question Answering (VidQA) exhibits remarkable potential in facilitating advanced machine reasoning capabilities within the domains of Intelligent Traffic Monitoring and Intelligent Transportation Systems. Nevertheless, the integration of urban traffic scene knowledge into VidQA systems has received limited attention in previous research endeavors. In this work, we present a novel approach termed Traffic-domain Video Question Answering with Automatic Captioning (TRIVIA), which serves as a weak-supervision technique for infusing traffic-domain knowledge into large video-language models. Empirical findings obtained from the SUTD-TrafficQA task highlight the substantial enhancements achieved by TRIVIA, elevating the accuracy of representative video-language models by a remarkable 6.5 points (19.88%) compared to baseline settings. This pioneering methodology holds great promise for driving advancements in the field, inspiring researchers and practitioners alike to unlock the full potential of emerging video-language models in traffic-related applications.
A Study of Situational Reasoning for Traffic Understanding
Jun 05, 2023
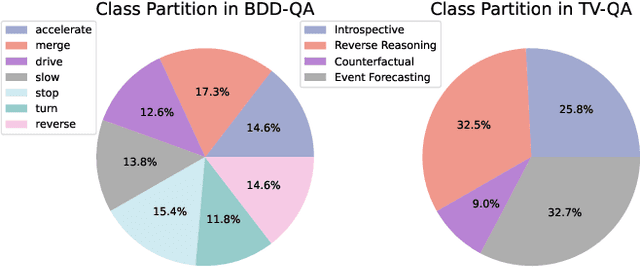

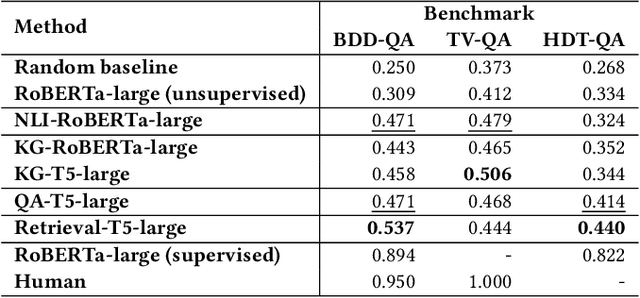
Intelligent Traffic Monitoring (ITMo) technologies hold the potential for improving road safety/security and for enabling smart city infrastructure. Understanding traffic situations requires a complex fusion of perceptual information with domain-specific and causal commonsense knowledge. Whereas prior work has provided benchmarks and methods for traffic monitoring, it remains unclear whether models can effectively align these information sources and reason in novel scenarios. To address this assessment gap, we devise three novel text-based tasks for situational reasoning in the traffic domain: i) BDD-QA, which evaluates the ability of Language Models (LMs) to perform situational decision-making, ii) TV-QA, which assesses LMs' abilities to reason about complex event causality, and iii) HDT-QA, which evaluates the ability of models to solve human driving exams. We adopt four knowledge-enhanced methods that have shown generalization capability across language reasoning tasks in prior work, based on natural language inference, commonsense knowledge-graph self-supervision, multi-QA joint training, and dense retrieval of domain information. We associate each method with a relevant knowledge source, including knowledge graphs, relevant benchmarks, and driving manuals. In extensive experiments, we benchmark various knowledge-aware methods against the three datasets, under zero-shot evaluation; we provide in-depth analyses of model performance on data partitions and examine model predictions categorically, to yield useful insights on traffic understanding, given different background knowledge and reasoning strategies.
Utilizing Background Knowledge for Robust Reasoning over Traffic Situations
Dec 04, 2022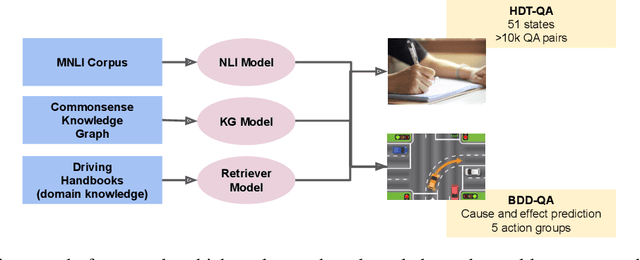

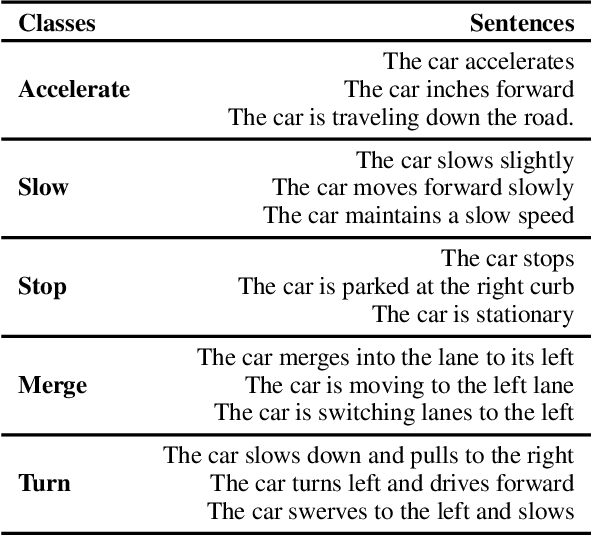
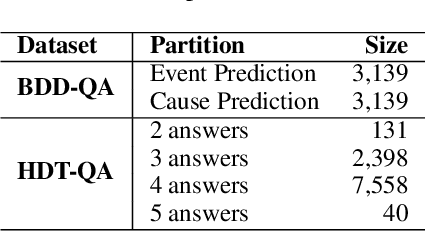
Understanding novel situations in the traffic domain requires an intricate combination of domain-specific and causal commonsense knowledge. Prior work has provided sufficient perception-based modalities for traffic monitoring, in this paper, we focus on a complementary research aspect of Intelligent Transportation: traffic understanding. We scope our study to text-based methods and datasets given the abundant commonsense knowledge that can be extracted using language models from large corpus and knowledge graphs. We adopt three knowledge-driven approaches for zero-shot QA over traffic situations, based on prior natural language inference methods, commonsense models with knowledge graph self-supervision, and dense retriever-based models. We constructed two text-based multiple-choice question answering sets: BDD-QA for evaluating causal reasoning in the traffic domain and HDT-QA for measuring the possession of domain knowledge akin to human driving license tests. Among the methods, Unified-QA reaches the best performance on the BDD-QA dataset with the adaptation of multiple formats of question answers. Language models trained with inference information and commonsense knowledge are also good at predicting the cause and effect in the traffic domain but perform badly at answering human-driving QA sets. For such sets, DPR+Unified-QA performs the best due to its efficient knowledge extraction.
Coalescing Global and Local Information for Procedural Text Understanding
Aug 26, 2022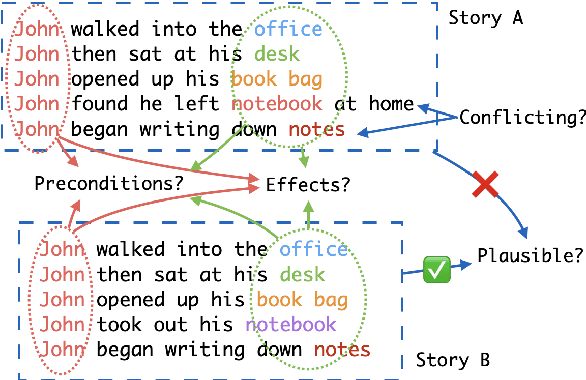
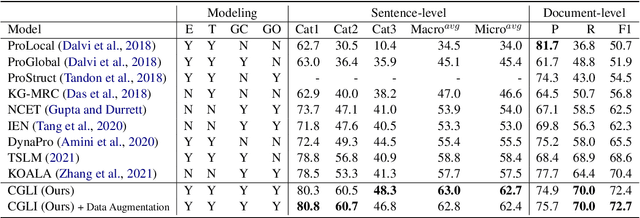
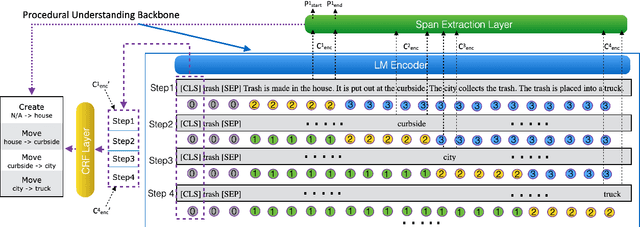
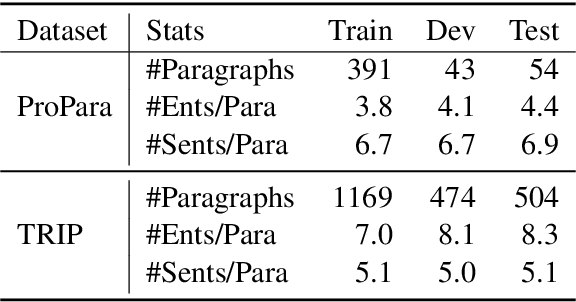
Procedural text understanding is a challenging language reasoning task that requires models to track entity states across the development of a narrative. A complete procedural understanding solution should combine three core aspects: local and global views of the inputs, and global view of outputs. Prior methods considered a subset of these aspects, resulting in either low precision or low recall. In this paper, we propose Coalescing Global and Local Information (CGLI), a new model that builds entity- and timestep-aware input representations (local input) considering the whole context (global input), and we jointly model the entity states with a structured prediction objective (global output). Thus, CGLI simultaneously optimizes for both precision and recall. We extend CGLI with additional output layers and integrate it into a story reasoning framework. Extensive experiments on a popular procedural text understanding dataset show that our model achieves state-of-the-art results; experiments on a story reasoning benchmark show the positive impact of our model on downstream reasoning.
An Empirical Investigation of Commonsense Self-Supervision with Knowledge Graphs
May 21, 2022

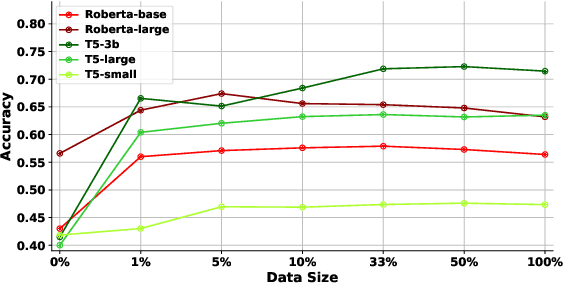

Self-supervision based on the information extracted from large knowledge graphs has been shown to improve the generalization of language models, in zero-shot evaluation on various downstream language reasoning tasks. Since these improvements are reported in aggregate, however, little is known about (i) how to select the appropriate knowledge for solid performance across tasks, (ii) how to combine this knowledge with neural language models, and (iii) how these pairings affect granular task performance. In this paper, we study the effect of knowledge sampling strategies and sizes that can be used to generate synthetic data for adapting language models. We study the effect of different synthetic datasets on language models with various architectures and sizes. The resulting models are evaluated against four task properties: domain overlap, answer similarity, vocabulary overlap, and answer length. Our experiments show that encoder-decoder models benefit from more data to learn from, whereas sampling strategies that balance across different aspects yield best performance. Most of the improvement occurs on questions with short answers and dissimilar answer candidates, which corresponds to the characteristics of the data used for pre-training.
Generalizable Neuro-symbolic Systems for Commonsense Question Answering
Jan 17, 2022



This chapter illustrates how suitable neuro-symbolic models for language understanding can enable domain generalizability and robustness in downstream tasks. Different methods for integrating neural language models and knowledge graphs are discussed. The situations in which this combination is most appropriate are characterized, including quantitative evaluation and qualitative error analysis on a variety of commonsense question answering benchmark datasets.