 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Knowledge Tracing via Probabilistic Embeddings and Pattern-based Reasoning
May 10, 2026Knowledge Tracing (KT) models students' knowledge states based on learning interactions to predict performance. While deep learning-based KT models have boosted predictive accuracy, most models rely on deterministic vector embeddings and opaque latent state transitions, limiting interpretability regarding how specific past behaviors influence predictions. To address this limitation, we propose Probabilistic Logical Knowledge Tracing (PLKT), an interpretable KT framework that formulates prediction as a goal-conditioned evidence reasoning process over historical learning behaviors. Instead of representing knowledge states as deterministic vector embeddings, PLKT employs robust Beta-distributed probabilistic embeddings to represent student knowledge states. This probabilistic foundation allows us to model the uncertainty of historical behaviors and perform explicit logical operations (e.g., conjunction), constructing transparent reasoning paths that reveal how specific past interactions contribute to the prediction. Extensive experiments show that PLKT outperforms state-of-the-art KT methods while achieving superior interpretability. Our code is available at https://anonymous.4open.science/r/PLKT-D3CE/.
Visualization of Machine Learning Models through Their Spatial and Temporal Listeners
Mar 29, 2026Model visualization (ModelVis) has emerged as a major research direction, yet existing taxonomies are largely organized by data or tasks, making it difficult to treat models as first-class analysis objects. We present a model-centric two-stage framework that employs abstract listeners to capture spatial and temporal model behaviors, and then connects the translated model behavior data to the classical InfoVis pipeline. To apply the framework at scale, we build a retrieval-augmented human--large language model (LLM) extraction workflow and curate a corpus of 128 VIS/VAST ModelVis papers with 331 coded figures. Our analysis shows a dominant result-centric priority on visualizing model outcomes, quantitative/nominal data type, statistical charts, and performance evaluation. Citation-weighted trends further indicate that less frequent model-mechanism-oriented studies have disproportionately high impact while are less investigated recently. Overall, the framework is a general approach for comparing existing ModelVis systems and guiding possible future designs.
xGR: Efficient Generative Recommendation Serving at Scale
Dec 19, 2025Recommendation system delivers substantial economic benefits by providing personalized predictions. Generative recommendation (GR) integrates LLMs to enhance the understanding of long user-item sequences. Despite employing attention-based architectures, GR's workload differs markedly from that of LLM serving. GR typically processes long prompt while producing short, fixed-length outputs, yet the computational cost of each decode phase is especially high due to the large beam width. In addition, since the beam search involves a vast item space, the sorting overhead becomes particularly time-consuming. We propose xGR, a GR-oriented serving system that meets strict low-latency requirements under highconcurrency scenarios. First, xGR unifies the processing of prefill and decode phases through staged computation and separated KV cache. Second, xGR enables early sorting termination and mask-based item filtering with data structure reuse. Third, xGR reconstructs the overall pipeline to exploit multilevel overlap and multi-stream parallelism. Our experiments with real-world recommendation service datasets demonstrate that xGR achieves at least 3.49x throughput compared to the state-of-the-art baseline under strict latency constraints.
Pre$^3$: Enabling Deterministic Pushdown Automata for Faster Structured LLM Generation
Jun 04, 2025Extensive LLM applications demand efficient structured generations, particularly for LR(1) grammars, to produce outputs in specified formats (e.g., JSON). Existing methods primarily parse LR(1) grammars into a pushdown automaton (PDA), leading to runtime execution overhead for context-dependent token processing, especially inefficient under large inference batches. To address these issues, we propose Pre$^3$ that exploits deterministic pushdown automata (DPDA) to optimize the constrained LLM decoding efficiency. First, by precomputing prefix-conditioned edges during the preprocessing, Pre$^3$ enables ahead-of-time edge analysis and thus makes parallel transition processing possible. Second, by leveraging the prefix-conditioned edges, Pre$^3$ introduces a novel approach that transforms LR(1) transition graphs into DPDA, eliminating the need for runtime path exploration and achieving edge transitions with minimal overhead. Pre$^3$ can be seamlessly integrated into standard LLM inference frameworks, reducing time per output token (TPOT) by up to 40% and increasing throughput by up to 36% in our experiments. Our code is available at https://github.com/ModelTC/lightllm.
CIKT: A Collaborative and Iterative Knowledge Tracing Framework with Large Language Models
May 23, 2025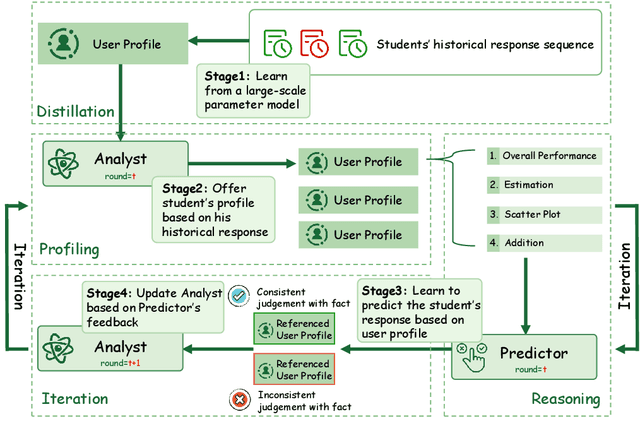
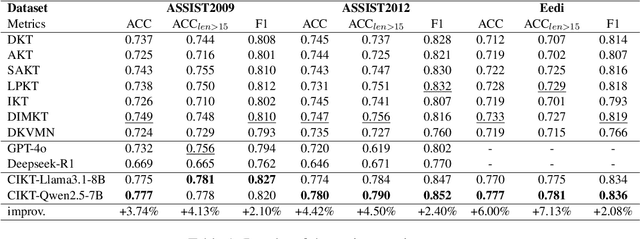
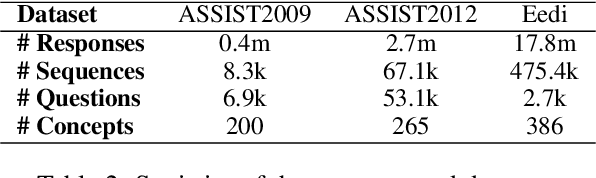
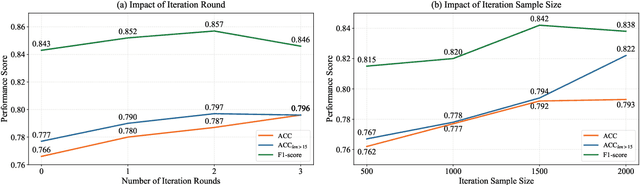
Knowledge Tracing (KT) aims to model a student's learning state over time and predict their future performance. However, traditional KT methods often face challenges in explainability, scalability, and effective modeling of complex knowledge dependencies. While Large Language Models (LLMs) present new avenues for KT, their direct application often struggles with generating structured, explainable student representations and lacks mechanisms for continuous, task-specific refinement. To address these gaps, we propose Collaborative Iterative Knowledge Tracing (CIKT), a framework that harnesses LLMs to enhance both prediction accuracy and explainability. CIKT employs a dual-component architecture: an Analyst generates dynamic, explainable user profiles from student historical responses, and a Predictor utilizes these profiles to forecast future performance. The core of CIKT is a synergistic optimization loop. In this loop, the Analyst is iteratively refined based on the predictive accuracy of the Predictor, which conditions on the generated profiles, and the Predictor is subsequently retrained using these enhanced profiles. Evaluated on multiple educational datasets, CIKT demonstrates significant improvements in prediction accuracy, offers enhanced explainability through its dynamically updated user profiles, and exhibits improved scalability. Our work presents a robust and explainable solution for advancing knowledge tracing systems, effectively bridging the gap between predictive performance and model transparency.
Cognitive LLMs: Towards Integrating Cognitive Architectures and Large Language Models for Manufacturing Decision-making
Aug 17, 2024



Resolving the dichotomy between the human-like yet constrained reasoning processes of Cognitive Architectures and the broad but often noisy inference behavior of Large Language Models (LLMs) remains a challenging but exciting pursuit, for enabling reliable machine reasoning capabilities in production systems. Because Cognitive Architectures are famously developed for the purpose of modeling the internal mechanisms of human cognitive decision-making at a computational level, new investigations consider the goal of informing LLMs with the knowledge necessary for replicating such processes, e.g., guided perception, memory, goal-setting, and action. Previous approaches that use LLMs for grounded decision-making struggle with complex reasoning tasks that require slower, deliberate cognition over fast and intuitive inference -- reporting issues related to the lack of sufficient grounding, as in hallucination. To resolve these challenges, we introduce LLM-ACTR, a novel neuro-symbolic architecture that provides human-aligned and versatile decision-making by integrating the ACT-R Cognitive Architecture with LLMs. Our framework extracts and embeds knowledge of ACT-R's internal decision-making process as latent neural representations, injects this information into trainable LLM adapter layers, and fine-tunes the LLMs for downstream prediction. Our experiments on novel Design for Manufacturing tasks show both improved task performance as well as improved grounded decision-making capability of our approach, compared to LLM-only baselines that leverage chain-of-thought reasoning strategies.
LLM-based MOFs Synthesis Condition Extraction using Few-Shot Demonstrations
Aug 06, 2024



The extraction of Metal-Organic Frameworks (MOFs) synthesis conditions from literature text has been challenging but crucial for the logical design of new MOFs with desirable functionality. The recent advent of large language models (LLMs) provides disruptively new solution to this long-standing problem and latest researches have reported over 90% F1 in extracting correct conditions from MOFs literature. We argue in this paper that most existing synthesis extraction practices with LLMs stay with the primitive zero-shot learning, which could lead to downgraded extraction and application performance due to the lack of specialized knowledge. This work pioneers and optimizes the few-shot in-context learning paradigm for LLM extraction of material synthesis conditions. First, we propose a human-AI joint data curation process to secure high-quality ground-truth demonstrations for few-shot learning. Second, we apply a BM25 algorithm based on the retrieval-augmented generation (RAG) technique to adaptively select few-shot demonstrations for each MOF's extraction. Over a dataset randomly sampled from 84,898 well-defined MOFs, the proposed few-shot method achieves much higher average F1 performance (0.93 vs. 0.81, +14.8%) than the native zero-shot LLM using the same GPT-4 model, under fully automatic evaluation that are more objective than the previous human evaluation. The proposed method is further validated through real-world material experiments: compared with the baseline zero-shot LLM, the proposed few-shot approach increases the MOFs structural inference performance (R^2) by 29.4% in average.
BARET : Balanced Attention based Real image Editing driven by Target-text Inversion
Dec 09, 2023
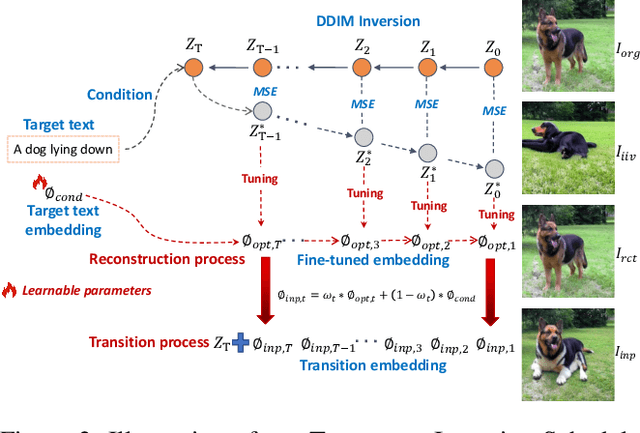


Image editing approaches with diffusion models have been rapidly developed, yet their applicability are subject to requirements such as specific editing types (e.g., foreground or background object editing, style transfer), multiple conditions (e.g., mask, sketch, caption), and time consuming fine-tuning of diffusion models. For alleviating these limitations and realizing efficient real image editing, we propose a novel editing technique that only requires an input image and target text for various editing types including non-rigid edits without fine-tuning diffusion model. Our method contains three novelties:(I) Target-text Inversion Schedule (TTIS) is designed to fine-tune the input target text embedding to achieve fast image reconstruction without image caption and acceleration of convergence.(II) Progressive Transition Scheme applies progressive linear interpolation between target text embedding and its fine-tuned version to generate transition embedding for maintaining non-rigid editing capability.(III) Balanced Attention Module (BAM) balances the tradeoff between textual description and image semantics.By the means of combining self-attention map from reconstruction process and cross-attention map from transition process, the guidance of target text embeddings in diffusion process is optimized.In order to demonstrate editing capability, effectiveness and efficiency of the proposed BARET, we have conducted extensive qualitative and quantitative experiments. Moreover, results derived from user study and ablation study further prove the superiority over other methods.
Structural Hawkes Processes for Learning Causal Structure from Discrete-Time Event Sequences
May 10, 2023



Learning causal structure among event types from discrete-time event sequences is a particularly important but challenging task. Existing methods, such as the multivariate Hawkes processes based methods, mostly boil down to learning the so-called Granger causality which assumes that the cause event happens strictly prior to its effect event. Such an assumption is often untenable beyond applications, especially when dealing with discrete-time event sequences in low-resolution; and typical discrete Hawkes processes mainly suffer from identifiability issues raised by the instantaneous effect, i.e., the causal relationship that occurred simultaneously due to the low-resolution data will not be captured by Granger causality. In this work, we propose Structure Hawkes Processes (SHPs) that leverage the instantaneous effect for learning the causal structure among events type in discrete-time event sequence. The proposed method is featured with the minorization-maximization of the likelihood function and a sparse optimization scheme. Theoretical results show that the instantaneous effect is a blessing rather than a curse, and the causal structure is identifiable under the existence of the instantaneous effect. Experiments on synthetic and real-world data verify the effectiveness of the proposed method.
THP: Topological Hawkes Processes for Learning Granger Causality on Event Sequences
May 23, 2021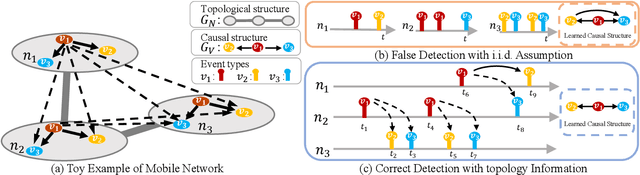

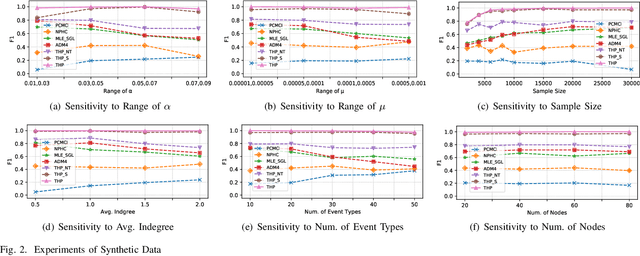
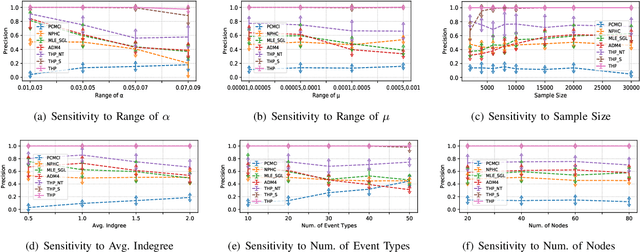
Learning Granger causality among event types on multi-type event sequences is an important but challenging task. Existing methods, such as the Multivariate Hawkes processes, mostly assumed that each sequence is independent and identically distributed. However, in many real-world applications, it is commonplace to encounter a topological network behind the event sequences such that an event is excited or inhibited not only by its history but also by its topological neighbors. Consequently, the failure in describing the topological dependency among the event sequences leads to the error detection of the causal structure. By considering the Hawkes processes from the view of temporal convolution, we propose a Topological Hawkes processes (THP) to draw a connection between the graph convolution in topology domain and the temporal convolution in time domains. We further propose a Granger causality learning method on THP in a likelihood framework. The proposed method is featured with the graph convolution-based likelihood function of THP and a sparse optimization scheme with an Expectation-Maximization of the likelihood function. Theoretical analysis and experiments on both synthetic and real-world data demonstrate the effectiveness of the proposed method.