 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre$^3$: Enabling Deterministic Pushdown Automata for Faster Structured LLM Generation
Jun 04, 2025Extensive LLM applications demand efficient structured generations, particularly for LR(1) grammars, to produce outputs in specified formats (e.g., JSON). Existing methods primarily parse LR(1) grammars into a pushdown automaton (PDA), leading to runtime execution overhead for context-dependent token processing, especially inefficient under large inference batches. To address these issues, we propose Pre$^3$ that exploits deterministic pushdown automata (DPDA) to optimize the constrained LLM decoding efficiency. First, by precomputing prefix-conditioned edges during the preprocessing, Pre$^3$ enables ahead-of-time edge analysis and thus makes parallel transition processing possible. Second, by leveraging the prefix-conditioned edges, Pre$^3$ introduces a novel approach that transforms LR(1) transition graphs into DPDA, eliminating the need for runtime path exploration and achieving edge transitions with minimal overhead. Pre$^3$ can be seamlessly integrated into standard LLM inference frameworks, reducing time per output token (TPOT) by up to 40% and increasing throughput by up to 36% in our experiments. Our code is available at https://github.com/ModelTC/lightllm.
Responsive DNN Adaptation for Video Analytics against Environment Shift via Hierarchical Mobile-Cloud Collaborations
Apr 30, 2025Mobile video analysis systems often encounter various deploying environments, where environment shifts present greater demands for responsiveness in adaptations of deployed "expert DNN models". Existing model adaptation frameworks primarily operate in a cloud-centric way, exhibiting degraded performance during adaptation and delayed reactions to environment shifts. Instead, this paper proposes MOCHA, a novel framework optimizing the responsiveness of continuous model adaptation through hierarchical collaborations between mobile and cloud resources. Specifically, MOCHA (1) reduces adaptation response delays by performing on-device model reuse and fast fine-tuning before requesting cloud model retrieval and end-to-end retraining; (2) accelerates history expert model retrieval by organizing them into a structured taxonomy utilizing domain semantics analyzed by a cloud foundation model as indices; (3) enables efficient local model reuse by maintaining onboard expert model caches for frequent scenes, which proactively prefetch model weights from the cloud model database. Extensive evaluations with real-world videos on three DNN tasks show MOCHA improves the model accuracy during adaptation by up to 6.8% while saving the response delay and retraining time by up to 35.5x and 3.0x respectively.
InfoMAE: Pair-Efficient Cross-Modal Alignment for Multimodal Time-Series Sensing Signals
Apr 13, 2025Standard multimodal self-supervised learning (SSL) algorithms regard cross-modal synchronization as implicit supervisory labels during pretraining, thus posing high requirements on the scale and quality of multimodal samples. These constraints significantly limit the performance of sensing intelligence in IoT applications, as the heterogeneity and the non-interpretability of time-series signals result in abundant unimodal data but scarce high-quality multimodal pairs. This paper proposes InfoMAE, a cross-modal alignment framework that tackles the challenge of multimodal pair efficiency under the SSL setting by facilitating efficient cross-modal alignment of pretrained unimodal representations. InfoMAE achieves \textit{efficient cross-modal alignment} with \textit{limited data pairs} through a novel information theory-inspired formulation that simultaneously addresses distribution-level and instance-level alignment. Extensive experiments on two real-world IoT applications are performed to evaluate InfoMAE's pairing efficiency to bridge pretrained unimodal models into a cohesive joint multimodal model. InfoMAE enhances downstream multimodal tasks by over 60% with significantly improved multimodal pairing efficiency. It also improves unimodal task accuracy by an average of 22%.
On the Efficiency and Robustness of Vibration-based Foundation Models for IoT Sensing: A Case Study
Apr 03, 2024



This paper demonstrates the potential of vibration-based Foundation Models (FMs), pre-trained with unlabeled sensing data, to improve the robustness of run-time inference in (a class of) IoT applications. A case study is presented featuring a vehicle classification application using acoustic and seismic sensing. The work is motivated by the success of foundation models in the areas of natural language processing and computer vision, leading to generalizations of the FM concept to other domains as well, where significant amounts of unlabeled data exist that can be used for self-supervised pre-training. One such domain is IoT applications. Foundation models for selected sensing modalities in the IoT domain can be pre-trained in an environment-agnostic fashion using available unlabeled sensor data and then fine-tuned to the deployment at hand using a small amount of labeled data. The paper shows that the pre-training/fine-tuning approach improves the robustness of downstream inference and facilitates adaptation to different environmental conditions. More specifically, we present a case study in a real-world setting to evaluate a simple (vibration-based) FM-like model, called FOCAL, demonstrating its superior robustness and adaptation, compared to conventional supervised deep neural networks (DNNs). We also demonstrate its superior convergence over supervised solutions. Our findings highlight the advantages of vibration-based FMs (and FM-inspired selfsupervised models in general) in terms of inference robustness, runtime efficiency, and model adaptation (via fine-tuning) in resource-limited IoT settings.
SudokuSens: Enhancing Deep Learning Robustness for IoT Sensing Applications using a Generative Approach
Feb 08, 2024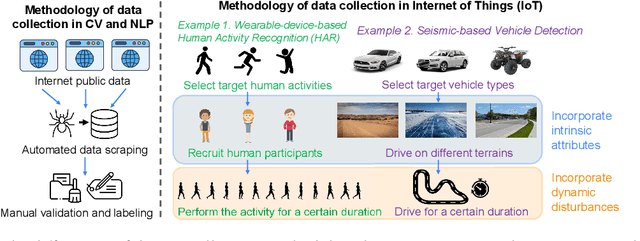
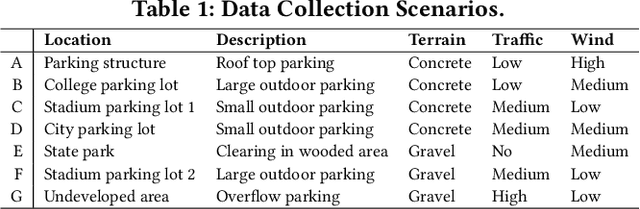
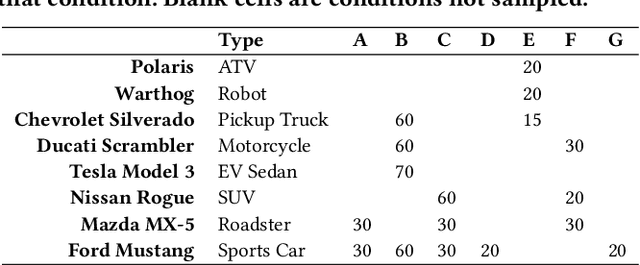
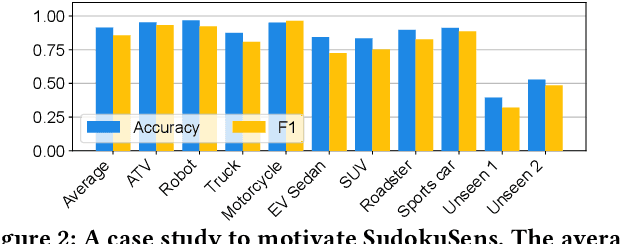
This paper introduces SudokuSens, a generative framework for automated generation of training data in machine-learning-based Internet-of-Things (IoT) applications, such that the generated synthetic data mimic experimental configurations not encountered during actual sensor data collection. The framework improves the robustness of resulting deep learning models, and is intended for IoT applications where data collection is expensive. The work is motivated by the fact that IoT time-series data entangle the signatures of observed objects with the confounding intrinsic properties of the surrounding environment and the dynamic environmental disturbances experienced. To incorporate sufficient diversity into the IoT training data, one therefore needs to consider a combinatorial explosion of training cases that are multiplicative in the number of objects considered and the possible environmental conditions in which such objects may be encountered. Our framework substantially reduces these multiplicative training needs. To decouple object signatures from environmental conditions, we employ a Conditional Variational Autoencoder (CVAE) that allows us to reduce data collection needs from multiplicative to (nearly) linear, while synthetically generating (data for) the missing conditions. To obtain robustness with respect to dynamic disturbances, a session-aware temporal contrastive learning approach is taken. Integrating the aforementioned two approaches, SudokuSens significantly improves the robustness of deep learning for IoT applications. We explore the degree to which SudokuSens benefits downstream inference tasks in different data sets and discuss conditions under which the approach is particularly effective.
FOCAL: Contrastive Learning for Multimodal Time-Series Sensing Signals in Factorized Orthogonal Latent Space
Oct 30, 2023



This paper proposes a novel contrastive learning framework, called FOCAL, for extracting comprehensive features from multimodal time-series sensing signals through self-supervised training. Existing multimodal contrastive frameworks mostly rely on the shared information between sensory modalities, but do not explicitly consider the exclusive modality information that could be critical to understanding the underlying sensing physics. Besides, contrastive frameworks for time series have not handled the temporal information locality appropriately. FOCAL solves these challenges by making the following contributions: First, given multimodal time series, it encodes each modality into a factorized latent space consisting of shared features and private features that are orthogonal to each other. The shared space emphasizes feature patterns consistent across sensory modalities through a modal-matching objective. In contrast, the private space extracts modality-exclusive information through a transformation-invariant objective. Second, we propose a temporal structural constraint for modality features, such that the average distance between temporally neighboring samples is no larger than that of temporally distant samples. Extensive evaluations are performed on four multimodal sensing datasets with two backbone encoders and two classifiers to demonstrate the superiority of FOCAL. It consistently outperforms the state-of-the-art baselines in downstream tasks with a clear margin, under different ratios of available labels. The code and self-collected dataset are available at https://github.com/tomoyoshki/focal.
Noisy Positive-Unlabeled Learning with Self-Training for Speculative Knowledge Graph Reasoning
Jun 13, 2023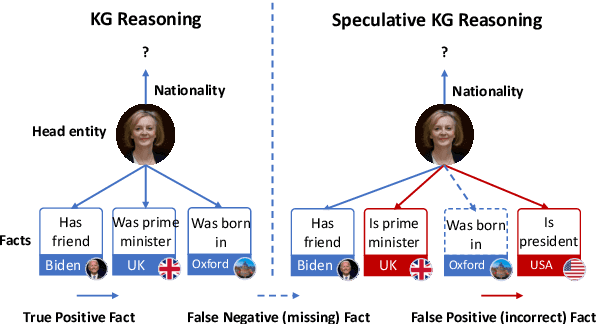
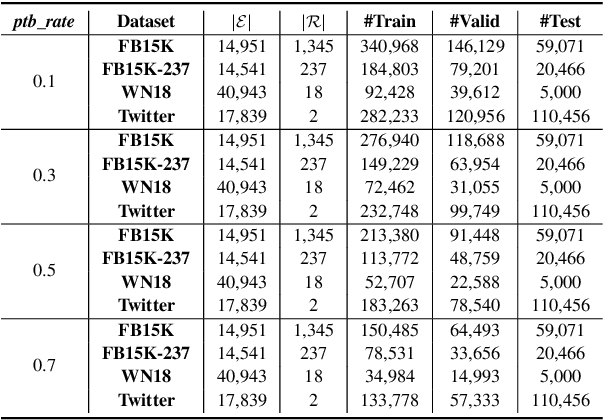
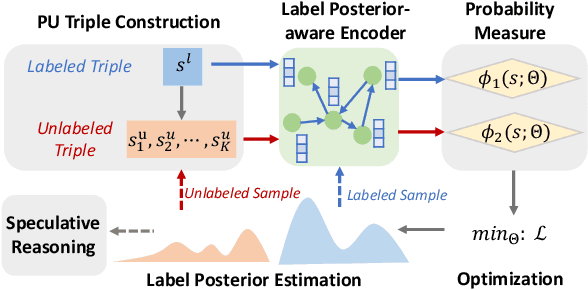
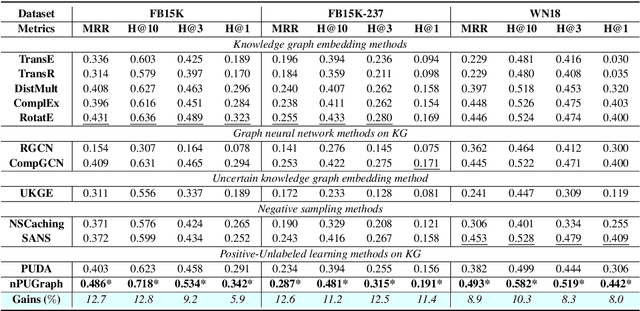
This paper studies speculative reasoning task on real-world knowledge graphs (KG) that contain both \textit{false negative issue} (i.e., potential true facts being excluded) and \textit{false positive issue} (i.e., unreliable or outdated facts being included). State-of-the-art methods fall short in the speculative reasoning ability, as they assume the correctness of a fact is solely determined by its presence in KG, making them vulnerable to false negative/positive issues. The new reasoning task is formulated as a noisy Positive-Unlabeled learning problem. We propose a variational framework, namely nPUGraph, that jointly estimates the correctness of both collected and uncollected facts (which we call \textit{label posterior}) and updates model parameters during training. The label posterior estimation facilitates speculative reasoning from two perspectives. First, it improves the robustness of a label posterior-aware graph encoder against false positive links. Second, it identifies missing facts to provide high-quality grounds of reasoning. They are unified in a simple yet effective self-training procedure. Empirically, extensive experiments on three benchmark KG and one Twitter dataset with various degrees of false negative/positive cases demonstrate the effectiveness of nPUGraph.
Learning to Sample and Aggregate: Few-shot Reasoning over Temporal Knowledge Graphs
Oct 16, 2022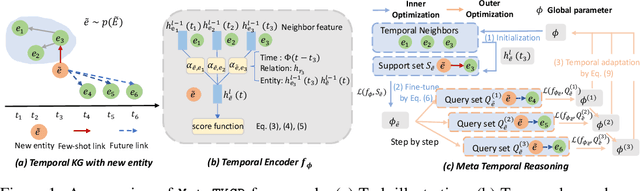
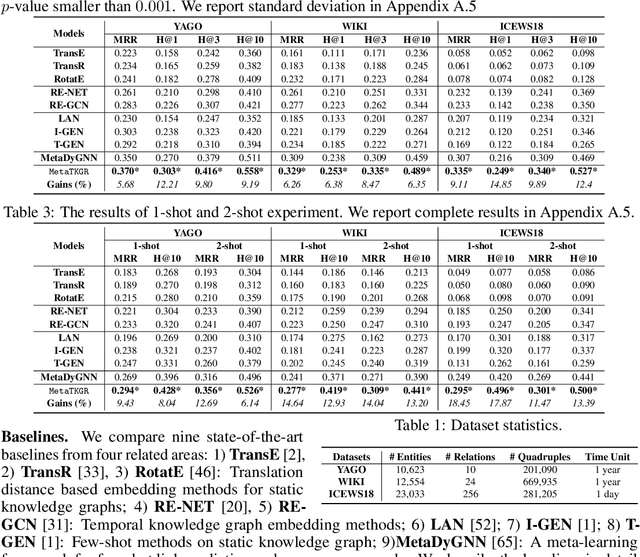
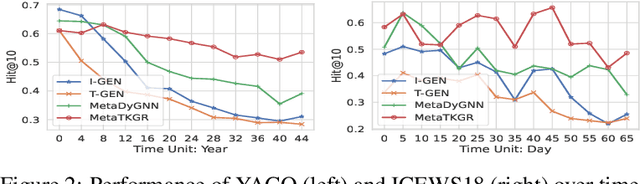
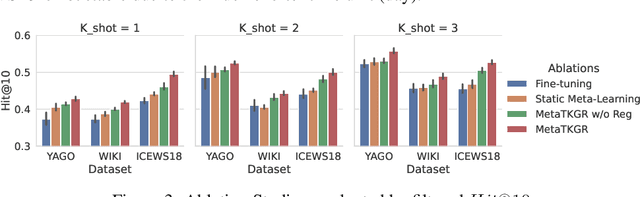
In this paper, we investigate a realistic but underexplored problem, called few-shot temporal knowledge graph reasoning, that aims to predict future facts for newly emerging entities based on extremely limited observations in evolving graphs. It offers practical value in applications that need to derive instant new knowledge about new entities in temporal knowledge graphs (TKGs) with minimal supervision. The challenges mainly come from the few-shot and time shift properties of new entities. First, the limited observations associated with them are insufficient for training a model from scratch. Second, the potentially dynamic distributions from the initially observable facts to the future facts ask for explicitly modeling the evolving characteristics of new entities. We correspondingly propose a novel Meta Temporal Knowledge Graph Reasoning (MetaTKGR) framework. Unlike prior work that relies on rigid neighborhood aggregation schemes to enhance low-data entity representation, MetaTKGR dynamically adjusts the strategies of sampling and aggregating neighbors from recent facts for new entities, through temporally supervised signals on future facts as instant feedback. Besides, such a meta temporal reasoning procedure goes beyond existing meta-learning paradigms on static knowledge graphs that fail to handle temporal adaptation with large entity variance. We further provide a theoretical analysis and propose a temporal adaptation regularizer to stabilize the meta temporal reasoning over time. Empirically, extensive experiments on three real-world TKGs demonstrate the superiority of MetaTKGR over state-of-the-art baselines by a large margin.
LiDAR Cluster First and Camera Inference Later: A New Perspective Towards Autonomous Driving
Nov 19, 2021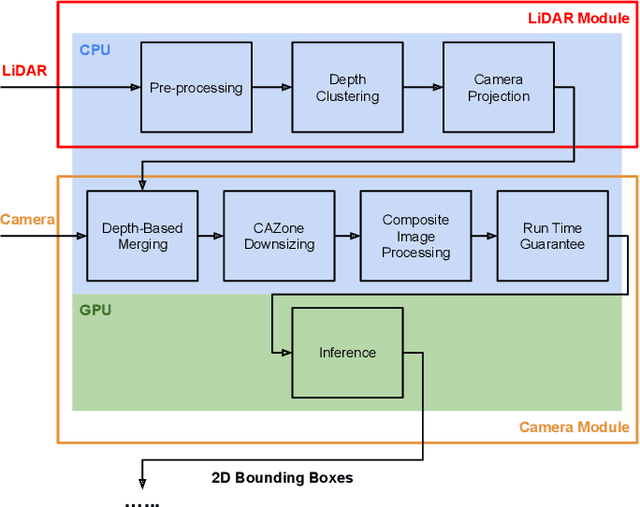
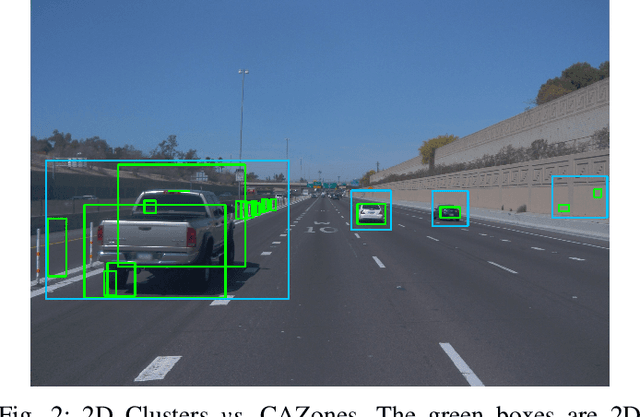
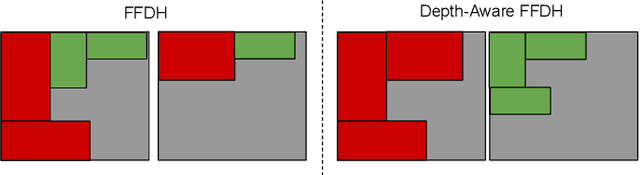

Object detection in state-of-the-art Autonomous Vehicles (AV) framework relies heavily on deep neural networks. Typically, these networks perform object detection uniformly on the entire camera LiDAR frames. However, this uniformity jeopardizes the safety of the AV by giving the same priority to all objects in the scenes regardless of their risk of collision to the AV. In this paper, we present a new end-to-end pipeline for AV that introduces the concept of LiDAR cluster first and camera inference later to detect and classify objects. The benefits of our proposed framework are twofold. First, our pipeline prioritizes detecting objects that pose a higher risk of collision to the AV, giving more time for the AV to react to unsafe conditions. Second, it also provides, on average, faster inference speeds compared to popular deep neural network pipelines. We design our framework using the real-world datasets, the Waymo Open Dataset, solving challenges arising from the limitations of LiDAR sensors and object detection algorithms. We show that our novel object detection pipeline prioritizes the detection of higher risk objects while simultaneously achieving comparable accuracy and a 25% higher average speed compared to camera inference only.
Unsupervised Belief Representation Learning in Polarized Networks with Information-Theoretic Variational Graph Auto-Encoders
Oct 11, 2021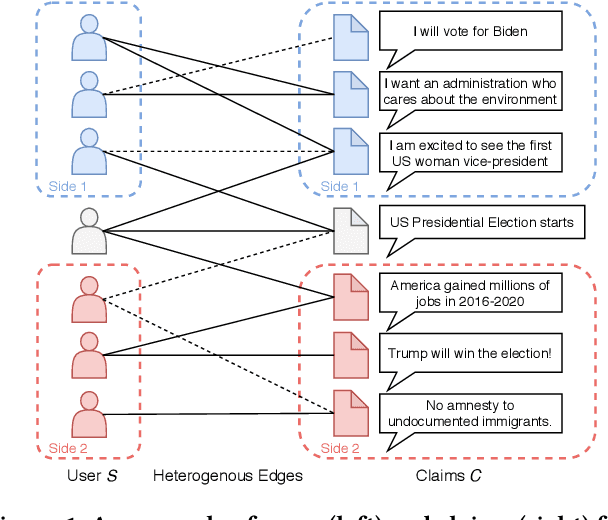
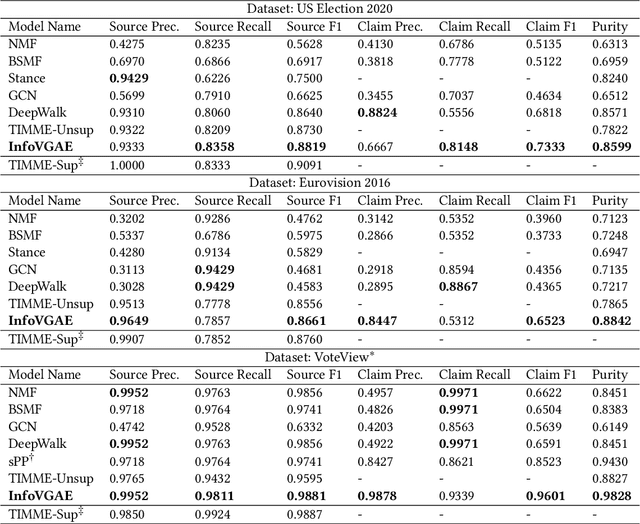
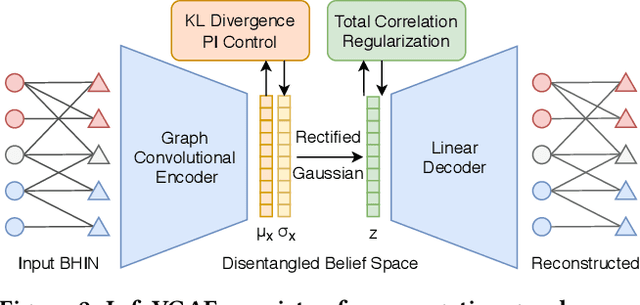

This paper develops a novel unsupervised algorithm for belief representation learning in polarized networks that (i) uncovers the latent dimensions of the underlying belief space and (ii) jointly embeds users and content items (that they interact with) into that space in a manner that facilitates a number of downstream tasks, such as stance detection, stance prediction, and ideology mapping. Inspired by total correlation in information theory, we propose a novel Information-Theoretic Variational Graph Auto-Encoder (InfoVGAE) that learns to project both users and content items (e.g., posts that represent user views) into an appropriate disentangled latent space. In order to better disentangle orthogonal latent variables in that space, we develop total correlation regularization, PI control module, and adopt rectified Gaussian Distribution for the latent space. The latent representation of users and content can then be used to quantify their ideological leaning and detect/predict their stances on issues. We evaluate the performance of the proposed InfoVGAE on three real-world datasets, of which two are collected from Twitter and one from U.S. Congress voting records. The evaluation results show that our model outperforms state-of-the-art unsupervised models and produce comparable result with supervised models. We also discuss stance prediction and user ranking within ideological groups.