 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashSinkhorn: IO-Aware Entropic Optimal Transport
Feb 03, 2026Entropic optimal transport (EOT) via Sinkhorn iterations is widely used in modern machine learning, yet GPU solvers remain inefficient at scale. Tensorized implementations suffer quadratic HBM traffic from dense $n\times m$ interactions, while existing online backends avoid storing dense matrices but still rely on generic tiled map-reduce reduction kernels with limited fusion. We present \textbf{FlashSinkhorn}, an IO-aware EOT solver for squared Euclidean cost that rewrites stabilized log-domain Sinkhorn updates as row-wise LogSumExp reductions of biased dot-product scores, the same normalization as transformer attention. This enables FlashAttention-style fusion and tiling: fused Triton kernels stream tiles through on-chip SRAM and update dual potentials in a single pass, substantially reducing HBM IO per iteration while retaining linear-memory operations. We further provide streaming kernels for transport application, enabling scalable first- and second-order optimization. On A100 GPUs, FlashSinkhorn achieves up to $32\times$ forward-pass and $161\times$ end-to-end speedups over state-of-the-art online baselines on point-cloud OT, improves scalability on OT-based downstream tasks. For reproducibility, we release an open-source implementation at https://github.com/ot-triton-lab/ot_triton.
INDUS: Effective and Efficient Language Models for Scientific Applications
May 17, 2024
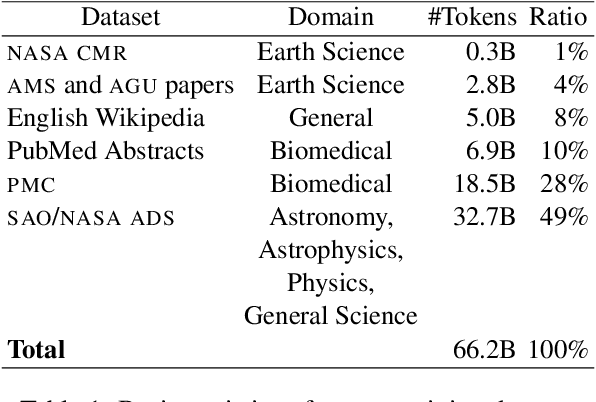
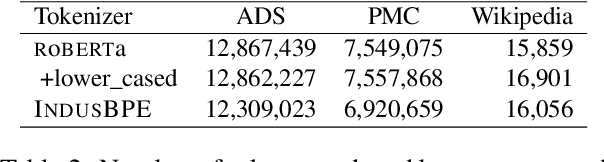

Large language models (LLMs) trained on general domain corpora showed remarkable results on natural language processing (NLP) tasks. However, previous research demonstrated LLMs trained using domain-focused corpora perform better on specialized tasks. Inspired by this pivotal insight, we developed INDUS, a comprehensive suite of LLMs tailored for the Earth science, biology, physics, heliophysics, planetary sciences and astrophysics domains and trained using curated scientific corpora drawn from diverse data sources. The suite of models include: (1) an encoder model trained using domain-specific vocabulary and corpora to address natural language understanding tasks, (2) a contrastive-learning-based general text embedding model trained using a diverse set of datasets drawn from multiple sources to address information retrieval tasks and (3) smaller versions of these models created using knowledge distillation techniques to address applications which have latency or resource constraints. We also created three new scientific benchmark datasets namely, CLIMATE-CHANGE-NER (entity-recognition), NASA-QA (extractive QA) and NASA-IR (IR) to accelerate research in these multi-disciplinary fields. Finally, we show that our models outperform both general-purpose encoders (RoBERTa) and existing domain-specific encoders (SciBERT) on these new tasks as well as existing benchmark tasks in the domains of interest.
Accelerating Production LLMs with Combined Token/Embedding Speculators
Apr 29, 2024This technical report describes the design and training of novel speculative decoding draft models, for accelerating the inference speeds of large language models in a production environment. By conditioning draft predictions on both context vectors and sampled tokens, we can train our speculators to efficiently predict high-quality n-grams, which the base model then accepts or rejects. This allows us to effectively predict multiple tokens per inference forward pass, accelerating wall-clock inference speeds of highly optimized base model implementations by a factor of 2-3x. We explore these initial results and describe next steps for further improvements.
SudokuSens: Enhancing Deep Learning Robustness for IoT Sensing Applications using a Generative Approach
Feb 08, 2024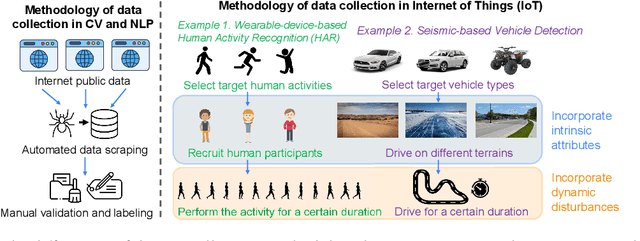
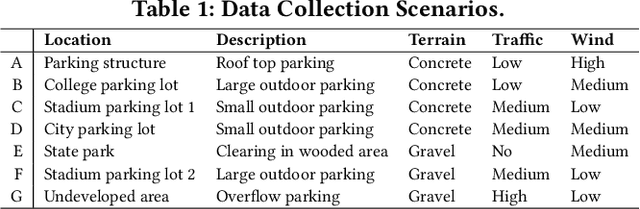
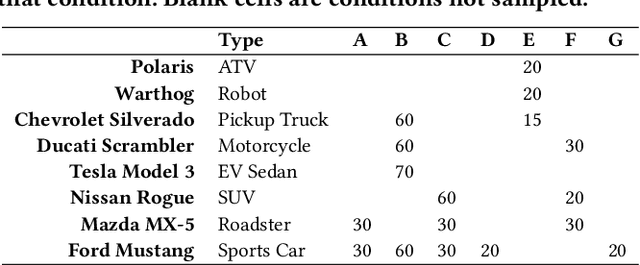
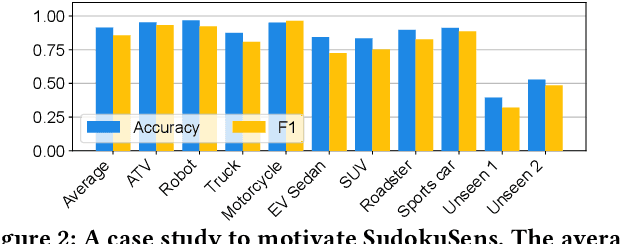
This paper introduces SudokuSens, a generative framework for automated generation of training data in machine-learning-based Internet-of-Things (IoT) applications, such that the generated synthetic data mimic experimental configurations not encountered during actual sensor data collection. The framework improves the robustness of resulting deep learning models, and is intended for IoT applications where data collection is expensive. The work is motivated by the fact that IoT time-series data entangle the signatures of observed objects with the confounding intrinsic properties of the surrounding environment and the dynamic environmental disturbances experienced. To incorporate sufficient diversity into the IoT training data, one therefore needs to consider a combinatorial explosion of training cases that are multiplicative in the number of objects considered and the possible environmental conditions in which such objects may be encountered. Our framework substantially reduces these multiplicative training needs. To decouple object signatures from environmental conditions, we employ a Conditional Variational Autoencoder (CVAE) that allows us to reduce data collection needs from multiplicative to (nearly) linear, while synthetically generating (data for) the missing conditions. To obtain robustness with respect to dynamic disturbances, a session-aware temporal contrastive learning approach is taken. Integrating the aforementioned two approaches, SudokuSens significantly improves the robustness of deep learning for IoT applications. We explore the degree to which SudokuSens benefits downstream inference tasks in different data sets and discuss conditions under which the approach is particularly effective.
Diagnosing and Remedying Shot Sensitivity with Cosine Few-Shot Learners
Jul 07, 2022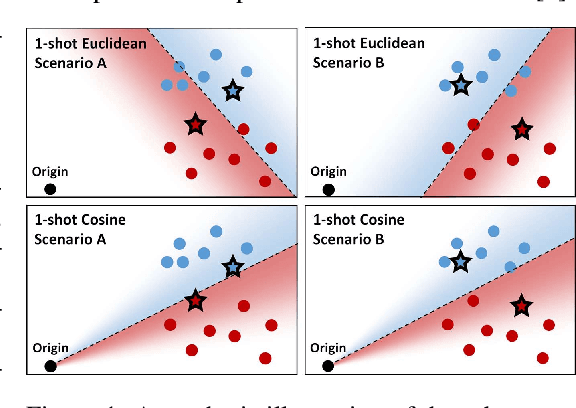
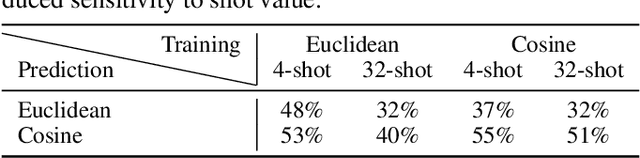
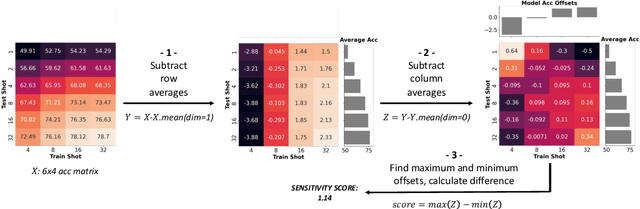
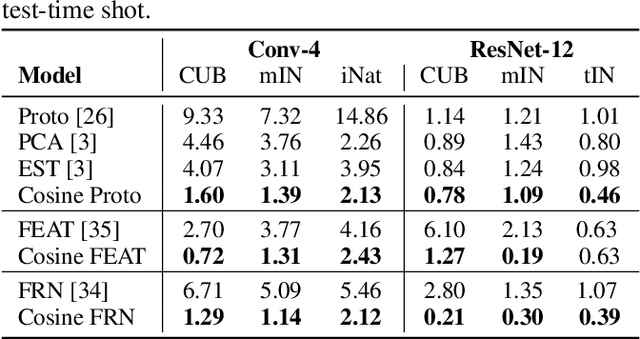
Few-shot recognition involves training an image classifier to distinguish novel concepts at test time using few examples (shot). Existing approaches generally assume that the shot number at test time is known in advance. This is not realistic, and the performance of a popular and foundational method has been shown to suffer when train and test shots do not match. We conduct a systematic empirical study of this phenomenon. In line with prior work, we find that shot sensitivity is broadly present across metric-based few-shot learners, but in contrast to prior work, larger neural architectures provide a degree of built-in robustness to varying test shot. More importantly, a simple, previously known but greatly overlooked class of approaches based on cosine distance consistently and greatly improves robustness to shot variation, by removing sensitivity to sample noise. We derive cosine alternatives to popular and recent few-shot classifiers, broadening their applicability to realistic settings. These cosine models consistently improve shot-robustness, outperform prior shot-robust state of the art, and provide competitive accuracy on a range of benchmarks and architectures, including notable gains in the very-low-shot regime.
Fine-Grained Few-Shot Classification with Feature Map Reconstruction Networks
Dec 02, 2020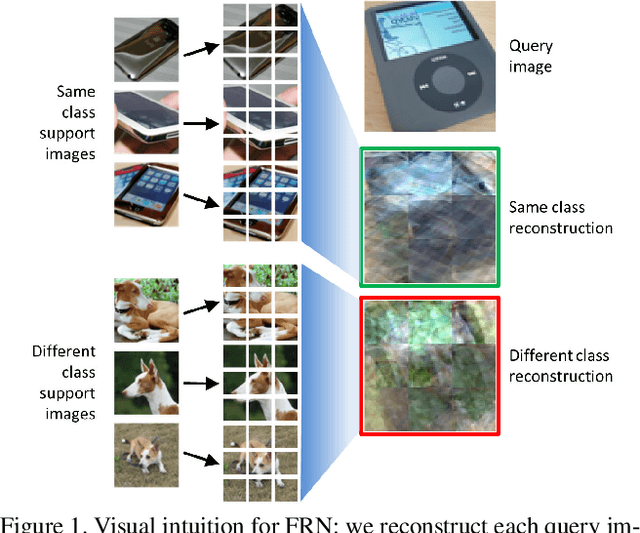
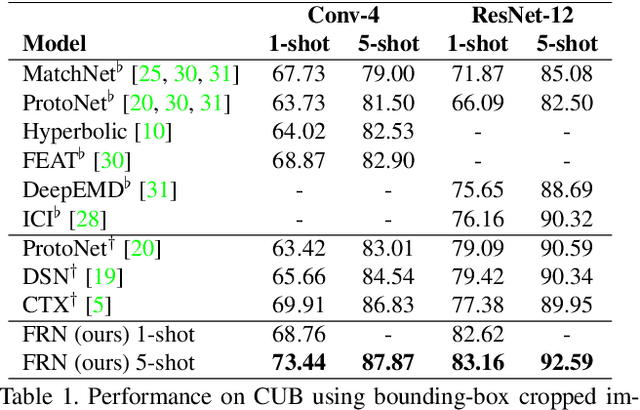
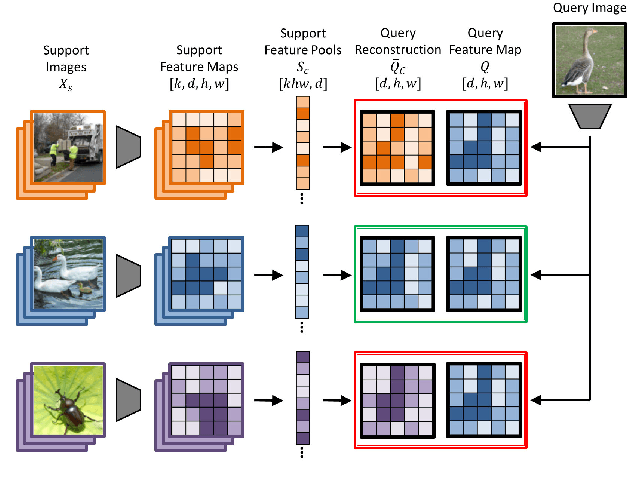

In this paper we reformulate few-shot classification as a reconstruction problem in latent space. The ability of the network to reconstruct a query feature map from support features of a given class predicts membership of the query in that class. We introduce a novel mechanism for few-shot classification by regressing directly from support features to query features in closed form, without introducing any new modules or large-scale learnable parameters. The resulting Feature Map Reconstruction Networks are both more performant and computationally efficient than previous approaches. We demonstrate consistent and significant accuracy gains on four fine-grained benchmarks with varying neural architectures. Our model is also competitive on the non-fine-grained mini-ImageNet benchmark with minimal bells and whistles.
Augmentation-Interpolative AutoEncoders for Unsupervised Few-Shot Image Generation
Nov 25, 2020
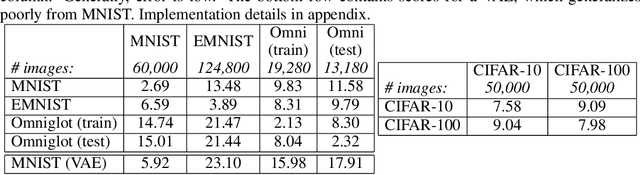

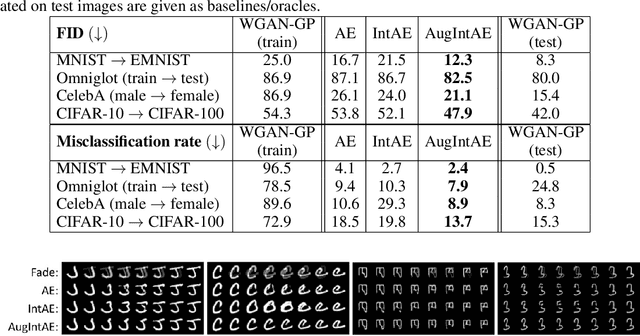
We aim to build image generation models that generalize to new domains from few examples. To this end, we first investigate the generalization properties of classic image generators, and discover that autoencoders generalize extremely well to new domains, even when trained on highly constrained data. We leverage this insight to produce a robust, unsupervised few-shot image generation algorithm, and introduce a novel training procedure based on recovering an image from data augmentations. Our Augmentation-Interpolative AutoEncoders synthesize realistic images of novel objects from only a few reference images, and outperform both prior interpolative models and supervised few-shot image generators. Our procedure is simple and lightweight, generalizes broadly, and requires no category labels or other supervision during training.
Revisiting Pose-Normalization for Fine-Grained Few-Shot Recognition
Apr 01, 2020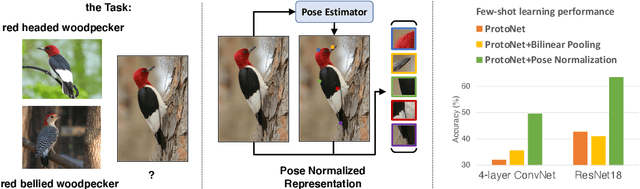
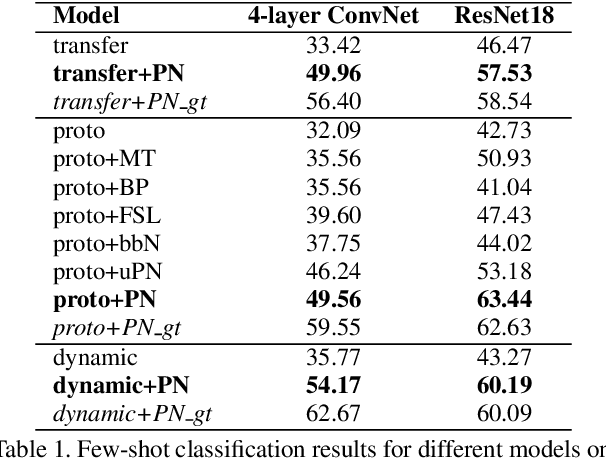
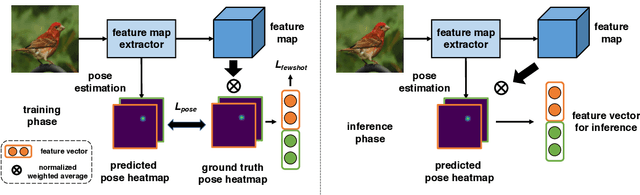
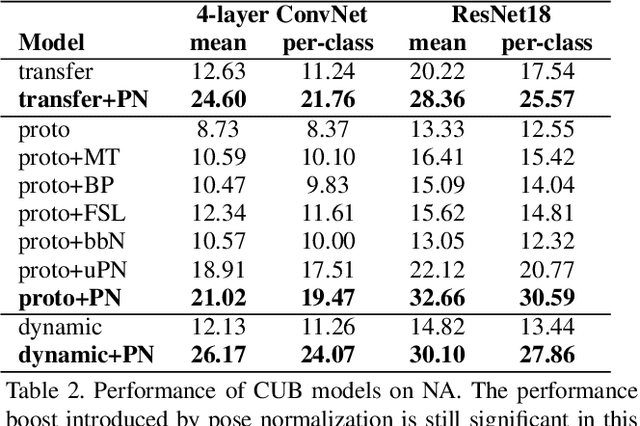
Few-shot, fine-grained classification requires a model to learn subtle, fine-grained distinctions between different classes (e.g., birds) based on a few images alone. This requires a remarkable degree of invariance to pose, articulation and background. A solution is to use pose-normalized representations: first localize semantic parts in each image, and then describe images by characterizing the appearance of each part. While such representations are out of favor for fully supervised classification, we show that they are extremely effective for few-shot fine-grained classification. With a minimal increase in model capacity, pose normalization improves accuracy between 10 and 20 percentage points for shallow and deep architectures, generalizes better to new domains, and is effective for multiple few-shot algorithms and network backbones. Code is available at https://github.com/Tsingularity/PoseNorm_Fewshot
Few-Shot Learning with Localization in Realistic Settings
Apr 09, 2019
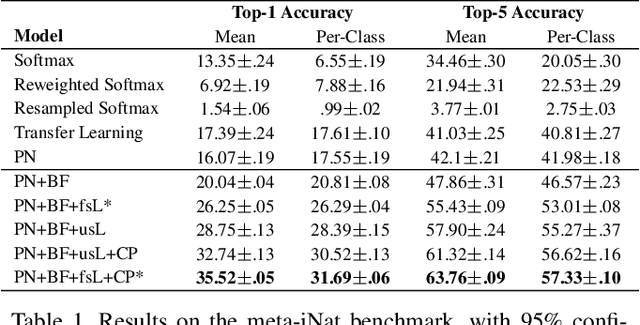
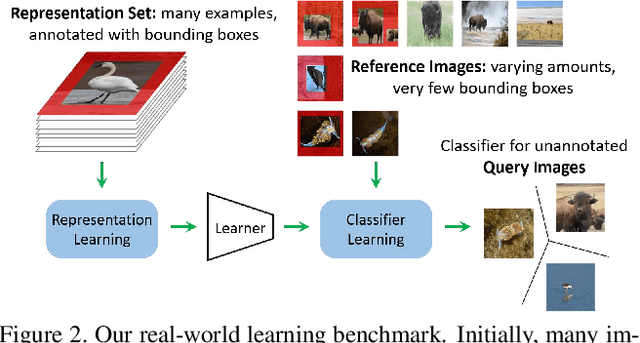
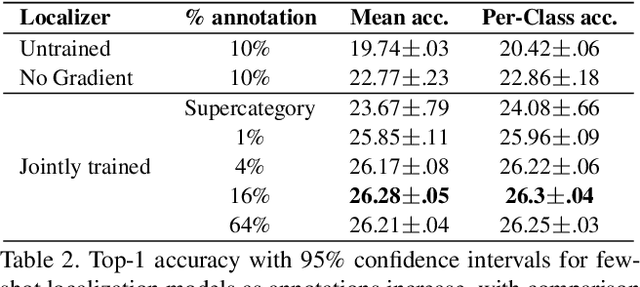
Traditional recognition methods typically require large, artificially-balanced training classes, while few-shot learning methods are tested on artificially small ones. In contrast to both extremes, real world recognition problems exhibit heavy-tailed class distributions, with cluttered scenes and a mix of coarse and fine-grained class distinctions. We show that prior methods designed for few-shot learning do not work out of the box in these challenging conditions, based on a new "meta-iNat" benchmark. We introduce three parameter-free improvements: (a) better training procedures based on adapting cross-validation to meta-learning, (b) novel architectures that localize objects using limited bounding box annotations before classification, and (c) simple parameter-free expansions of the feature space based on bilinear pooling. Together, these improvements double the accuracy of state-of-the-art models on meta-iNat while generalizing to prior benchmarks, complex neural architectures, and settings with substantial domain shift.