 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePDE foundation models are skillful AI weather emulators for the Martian atmosphere
Feb 16, 2026We show that AI foundation models that are pretrained on numerical solutions to a diverse corpus of partial differential equations can be adapted and fine-tuned to obtain skillful predictive weather emulators for the Martian atmosphere. We base our work on the Poseidon PDE foundation model for two-dimensional systems. We develop a method to extend Poseidon from two to three dimensions while keeping the pretraining information. Moreover, we investigate the performance of the model in the presence of sparse initial conditions. Our results make use of four Martian years (approx.~34 GB) of training data and a median compute budget of 13 GPU hours. We find that the combination of pretraining and model extension yields a performance increase of 34.4\% on a held-out year. This shows that PDEs-FMs can not only approximate solutions to (other) PDEs but also anchor models for real-world problems with complex interactions that lack a sufficient amount of training data or a suitable compute budget.
Landslide Hazard Mapping with Geospatial Foundation Models: Geographical Generalizability, Data Scarcity, and Band Adaptability
Nov 06, 2025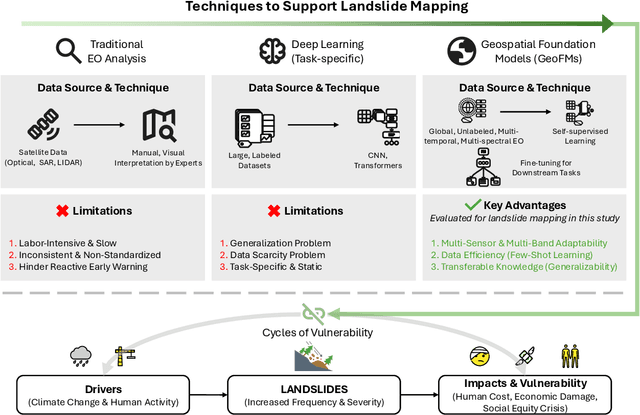
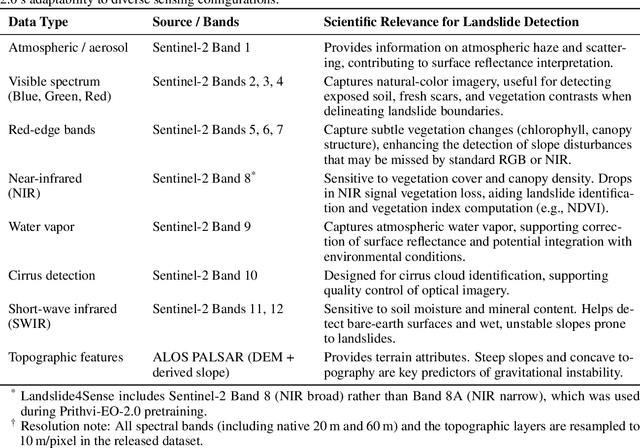
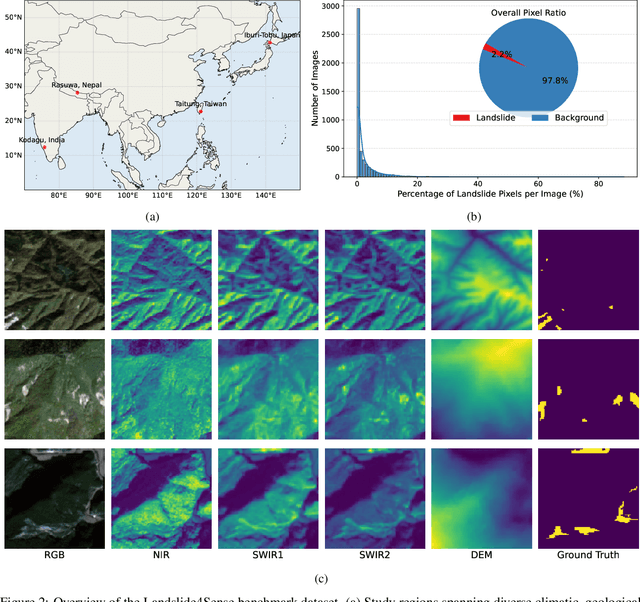
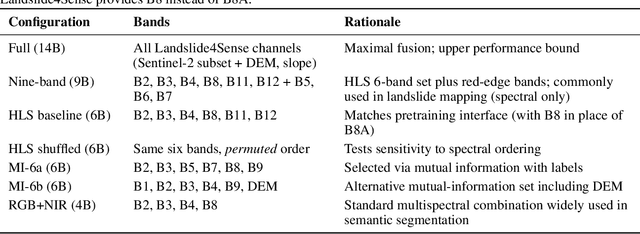
Landslides cause severe damage to lives, infrastructure, and the environment, making accurate and timely mapping essential for disaster preparedness and response. However, conventional deep learning models often struggle when applied across different sensors, regions, or under conditions of limited training data. To address these challenges, we present a three-axis analytical framework of sensor, label, and domain for adapting geospatial foundation models (GeoFMs), focusing on Prithvi-EO-2.0 for landslide mapping. Through a series of experiments, we show that it consistently outperforms task-specific CNNs (U-Net, U-Net++), vision transformers (Segformer, SwinV2-B), and other GeoFMs (TerraMind, SatMAE). The model, built on global pretraining, self-supervision, and adaptable fine-tuning, proved resilient to spectral variation, maintained accuracy under label scarcity, and generalized more reliably across diverse datasets and geographic settings. Alongside these strengths, we also highlight remaining challenges such as computational cost and the limited availability of reusable AI-ready training data for landslide research. Overall, our study positions GeoFMs as a step toward more robust and scalable approaches for landslide risk reduction and environmental monitoring.
Finetuning AI Foundation Models to Develop Subgrid-Scale Parameterizations: A Case Study on Atmospheric Gravity Waves
Sep 04, 2025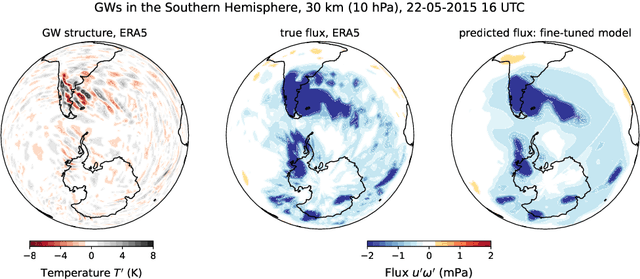



Global climate models parameterize a range of atmospheric-oceanic processes like gravity waves, clouds, moist convection, and turbulence that cannot be sufficiently resolved. These subgrid-scale closures for unresolved processes are a leading source of model uncertainty. Here, we present a new approach to developing machine learning parameterizations of small-scale climate processes by fine-tuning a pre-trained AI foundation model (FM). FMs are largely unexplored in climate research. A pre-trained encoder-decoder from a 2.3 billion parameter FM (NASA and IBM Research's Prithvi WxC) -- which contains a latent probabilistic representation of atmospheric evolution -- is fine-tuned (or reused) to create a deep learning parameterization for atmospheric gravity waves (GWs). The parameterization captures GW effects for a coarse-resolution climate model by learning the fluxes from an atmospheric reanalysis with 10 times finer resolution. A comparison of monthly averages and instantaneous evolution with a machine learning model baseline (an Attention U-Net) reveals superior predictive performance of the FM parameterization throughout the atmosphere, even in regions excluded from pre-training. This performance boost is quantified using the Hellinger distance, which is 0.11 for the baseline and 0.06 for the fine-tuned model. Our findings emphasize the versatility and reusability of FMs, which could be used to accomplish a range of atmosphere- and climate-related applications, leading the way for the creation of observations-driven and physically accurate parameterizations for more earth-system processes.
How Well Does GPT-4o Understand Vision? Evaluating Multimodal Foundation Models on Standard Computer Vision Tasks
Jul 02, 2025Multimodal foundation models, such as GPT-4o, have recently made remarkable progress, but it is not clear where exactly these models stand in terms of understanding vision. In this paper, we benchmark the performance of popular multimodal foundation models (GPT-4o, o4-mini, Gemini 1.5 Pro and Gemini 2.0 Flash, Claude 3.5 Sonnet, Qwen2-VL, Llama 3.2) on standard computer vision tasks (semantic segmentation, object detection, image classification, depth and surface normal prediction) using established datasets (e.g., COCO, ImageNet and its variants, etc). The main challenges to performing this are: 1) most models are trained to output text and cannot natively express versatile domains, such as segments or 3D geometry, and 2) many leading models are proprietary and accessible only at an API level, i.e., there is no weight access to adapt them. We address these challenges by translating standard vision tasks into equivalent text-promptable and API-compatible tasks via prompt chaining to create a standardized benchmarking framework. We observe that 1) the models are not close to the state-of-the-art specialist models at any task. However, 2) they are respectable generalists; this is remarkable as they are presumably trained on primarily image-text-based tasks. 3) They perform semantic tasks notably better than geometric ones. 4) While the prompt-chaining techniques affect performance, better models exhibit less sensitivity to prompt variations. 5) GPT-4o performs the best among non-reasoning models, securing the top position in 4 out of 6 tasks, 6) reasoning models, e.g. o3, show improvements in geometric tasks, and 7) a preliminary analysis of models with native image generation, like the latest GPT-4o, shows they exhibit quirks like hallucinations and spatial misalignments.
TerraMind: Large-Scale Generative Multimodality for Earth Observation
Apr 15, 2025



We present TerraMind, the first any-to-any generative, multimodal foundation model for Earth observation (EO). Unlike other multimodal models, TerraMind is pretrained on dual-scale representations combining both token-level and pixel-level data across modalities. On a token level, TerraMind encodes high-level contextual information to learn cross-modal relationships, while on a pixel level, TerraMind leverages fine-grained representations to capture critical spatial nuances. We pretrained TerraMind on nine geospatial modalities of a global, large-scale dataset. In this paper, we demonstrate that (i) TerraMind's dual-scale early fusion approach unlocks a range of zero-shot and few-shot applications for Earth observation, (ii) TerraMind introduces "Thinking-in-Modalities" (TiM) -- the capability of generating additional artificial data during finetuning and inference to improve the model output -- and (iii) TerraMind achieves beyond state-of-the-art performance in community-standard benchmarks for EO like PANGAEA. The pretraining dataset, the model weights, and our code is open-sourced under a permissive license.
WxC-Bench: A Novel Dataset for Weather and Climate Downstream Tasks
Dec 03, 2024



High-quality machine learning (ML)-ready datasets play a foundational role in developing new artificial intelligence (AI) models or fine-tuning existing models for scientific applications such as weather and climate analysis. Unfortunately, despite the growing development of new deep learning models for weather and climate, there is a scarcity of curated, pre-processed machine learning (ML)-ready datasets. Curating such high-quality datasets for developing new models is challenging particularly because the modality of the input data varies significantly for different downstream tasks addressing different atmospheric scales (spatial and temporal). Here we introduce WxC-Bench (Weather and Climate Bench), a multi-modal dataset designed to support the development of generalizable AI models for downstream use-cases in weather and climate research. WxC-Bench is designed as a dataset of datasets for developing ML-models for a complex weather and climate system, addressing selected downstream tasks as machine learning phenomenon. WxC-Bench encompasses several atmospheric processes from meso-$\beta$ (20 - 200 km) scale to synoptic scales (2500 km), such as aviation turbulence, hurricane intensity and track monitoring, weather analog search, gravity wave parameterization, and natural language report generation. We provide a comprehensive description of the dataset and also present a technical validation for baseline analysis. The dataset and code to prepare the ML-ready data have been made publicly available on Hugging Face -- https://huggingface.co/datasets/nasa-impact/WxC-Bench
Prithvi-EO-2.0: A Versatile Multi-Temporal Foundation Model for Earth Observation Applications
Dec 03, 2024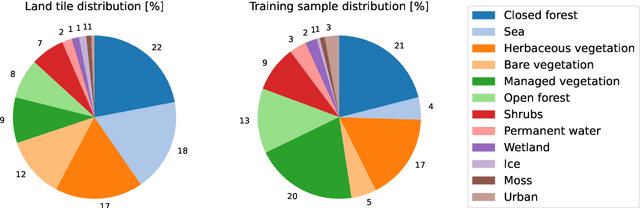
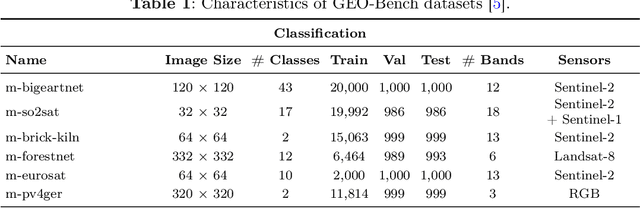
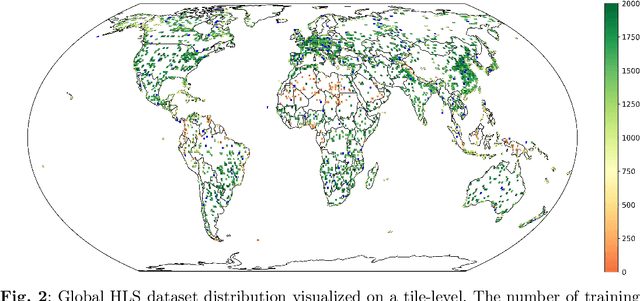
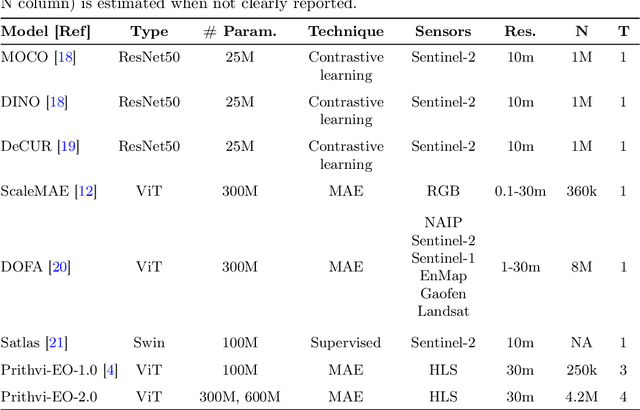
This technical report presents Prithvi-EO-2.0, a new geospatial foundation model that offers significant improvements over its predecessor, Prithvi-EO-1.0. Trained on 4.2M global time series samples from NASA's Harmonized Landsat and Sentinel-2 data archive at 30m resolution, the new 300M and 600M parameter models incorporate temporal and location embeddings for enhanced performance across various geospatial tasks. Through extensive benchmarking with GEO-Bench, the 600M version outperforms the previous Prithvi-EO model by 8\% across a range of tasks. It also outperforms six other geospatial foundation models when benchmarked on remote sensing tasks from different domains and resolutions (i.e. from 0.1m to 15m). The results demonstrate the versatility of the model in both classical earth observation and high-resolution applications. Early involvement of end-users and subject matter experts (SMEs) are among the key factors that contributed to the project's success. In particular, SME involvement allowed for constant feedback on model and dataset design, as well as successful customization for diverse SME-led applications in disaster response, land use and crop mapping, and ecosystem dynamics monitoring. Prithvi-EO-2.0 is available on Hugging Face and IBM terratorch, with additional resources on GitHub. The project exemplifies the Trusted Open Science approach embraced by all involved organizations.
Challenges in Guardrailing Large Language Models for Science
Nov 12, 2024The rapid development in large language models (LLMs) has transformed the landscape of natural language processing and understanding (NLP/NLU), offering significant benefits across various domains. However, when applied to scientific research, these powerful models exhibit critical failure modes related to scientific integrity and trustworthiness. Existing general-purpose LLM guardrails are insufficient to address these unique challenges in the scientific domain. We provide comprehensive guidelines for deploying LLM guardrails in the scientific domain. We identify specific challenges -- including time sensitivity, knowledge contextualization, conflict resolution, and intellectual property concerns -- and propose a guideline framework for the guardrails that can align with scientific needs. These guardrail dimensions include trustworthiness, ethics & bias, safety, and legal aspects. We also outline in detail the implementation strategies that employ white-box, black-box, and gray-box methodologies that can be enforced within scientific contexts.
On Evaluation of Vision Datasets and Models using Human Competency Frameworks
Sep 06, 2024



Evaluating models and datasets in computer vision remains a challenging task, with most leaderboards relying solely on accuracy. While accuracy is a popular metric for model evaluation, it provides only a coarse assessment by considering a single model's score on all dataset items. This paper explores Item Response Theory (IRT), a framework that infers interpretable latent parameters for an ensemble of models and each dataset item, enabling richer evaluation and analysis beyond the single accuracy number. Leveraging IRT, we assess model calibration, select informative data subsets, and demonstrate the usefulness of its latent parameters for analyzing and comparing models and datasets in computer vision.
Machine Learning Global Simulation of Nonlocal Gravity Wave Propagation
Jun 20, 2024Global climate models typically operate at a grid resolution of hundreds of kilometers and fail to resolve atmospheric mesoscale processes, e.g., clouds, precipitation, and gravity waves (GWs). Model representation of these processes and their sources is essential to the global circulation and planetary energy budget, but subgrid scale contributions from these processes are often only approximately represented in models using parameterizations. These parameterizations are subject to approximations and idealizations, which limit their capability and accuracy. The most drastic of these approximations is the "single-column approximation" which completely neglects the horizontal evolution of these processes, resulting in key biases in current climate models. With a focus on atmospheric GWs, we present the first-ever global simulation of atmospheric GW fluxes using machine learning (ML) models trained on the WINDSET dataset to emulate global GW emulation in the atmosphere, as an alternative to traditional single-column parameterizations. Using an Attention U-Net-based architecture trained on globally resolved GW momentum fluxes, we illustrate the importance and effectiveness of global nonlocality, when simulating GWs using data-driven schemes.