 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation Model Priors Enhance Object Focus in Feature Space for Source-Free Object Detection
Dec 24, 2025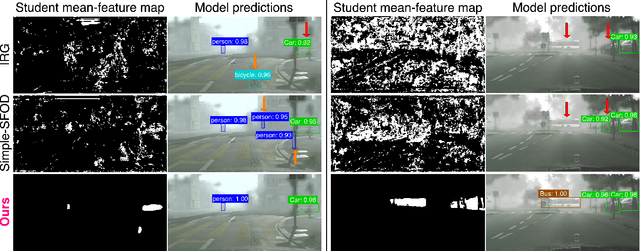
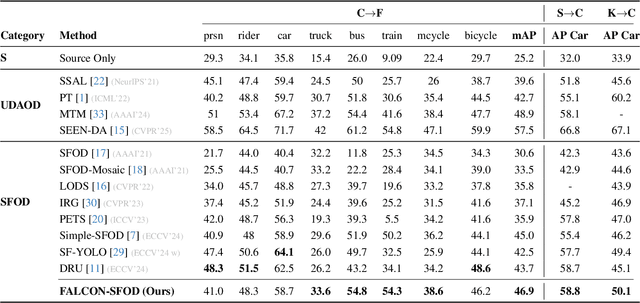
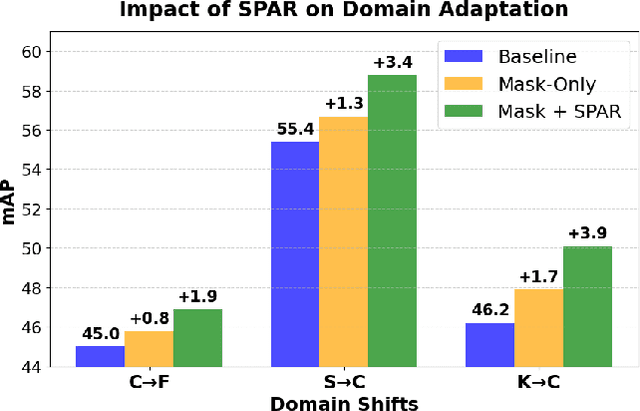
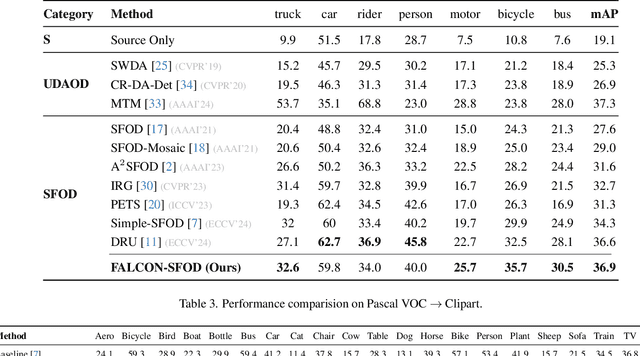
Current state-of-the-art approaches in Source-Free Object Detection (SFOD) typically rely on Mean-Teacher self-labeling. However, domain shift often reduces the detector's ability to maintain strong object-focused representations, causing high-confidence activations over background clutter. This weak object focus results in unreliable pseudo-labels from the detection head. While prior works mainly refine these pseudo-labels, they overlook the underlying need to strengthen the feature space itself. We propose FALCON-SFOD (Foundation-Aligned Learning with Clutter suppression and Noise robustness), a framework designed to enhance object-focused adaptation under domain shift. It consists of two complementary components. SPAR (Spatial Prior-Aware Regularization) leverages the generalization strength of vision foundation models to regularize the detector's feature space. Using class-agnostic binary masks derived from OV-SAM, SPAR promotes structured and foreground-focused activations by guiding the network toward object regions. IRPL (Imbalance-aware Noise Robust Pseudo-Labeling) complements SPAR by promoting balanced and noise-tolerant learning under severe foreground-background imbalance. Guided by a theoretical analysis that connects these designs to tighter localization and classification error bounds, FALCON-SFOD achieves competitive performance across SFOD benchmarks.
On Evaluation of Vision Datasets and Models using Human Competency Frameworks
Sep 06, 2024



Evaluating models and datasets in computer vision remains a challenging task, with most leaderboards relying solely on accuracy. While accuracy is a popular metric for model evaluation, it provides only a coarse assessment by considering a single model's score on all dataset items. This paper explores Item Response Theory (IRT), a framework that infers interpretable latent parameters for an ensemble of models and each dataset item, enabling richer evaluation and analysis beyond the single accuracy number. Leveraging IRT, we assess model calibration, select informative data subsets, and demonstrate the usefulness of its latent parameters for analyzing and comparing models and datasets in computer vision.