 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Evaluation of Vision Datasets and Models using Human Competency Frameworks
Sep 06, 2024



Evaluating models and datasets in computer vision remains a challenging task, with most leaderboards relying solely on accuracy. While accuracy is a popular metric for model evaluation, it provides only a coarse assessment by considering a single model's score on all dataset items. This paper explores Item Response Theory (IRT), a framework that infers interpretable latent parameters for an ensemble of models and each dataset item, enabling richer evaluation and analysis beyond the single accuracy number. Leveraging IRT, we assess model calibration, select informative data subsets, and demonstrate the usefulness of its latent parameters for analyzing and comparing models and datasets in computer vision.
Automated Testing of AI Models
Oct 07, 2021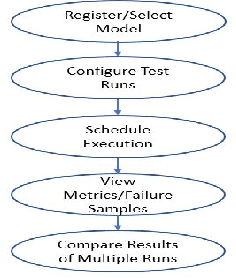
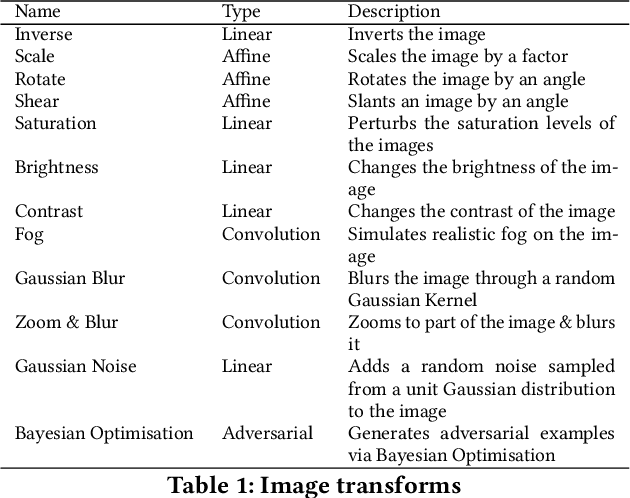
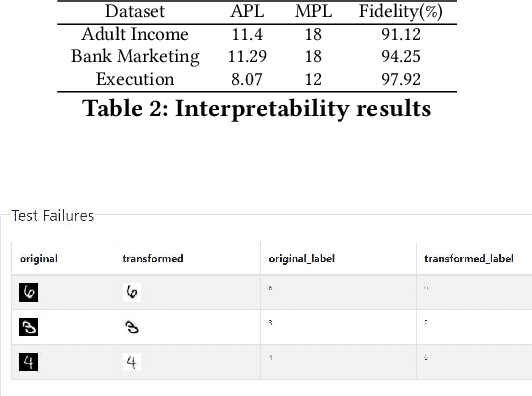
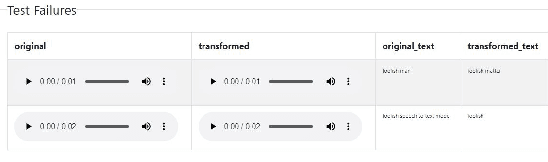
The last decade has seen tremendous progress in AI technology and applications. With such widespread adoption, ensuring the reliability of the AI models is crucial. In past, we took the first step of creating a testing framework called AITEST for metamorphic properties such as fairness, robustness properties for tabular, time-series, and text classification models. In this paper, we extend the capability of the AITEST tool to include the testing techniques for Image and Speech-to-text models along with interpretability testing for tabular models. These novel extensions make AITEST a comprehensive framework for testing AI models.
Inducing Semantic Grouping of Latent Concepts for Explanations: An Ante-Hoc Approach
Aug 25, 2021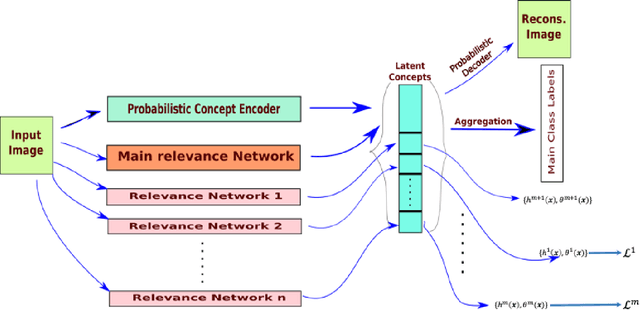

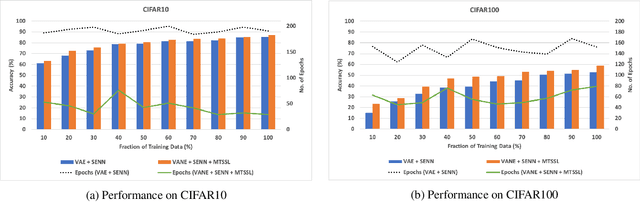

Self-explainable deep models are devised to represent the hidden concepts in the dataset without requiring any posthoc explanation generation technique. We worked with one of such models motivated by explicitly representing the classifier function as a linear function and showed that by exploiting probabilistic latent and properly modifying different parts of the model can result better explanation as well as provide superior predictive performance. Apart from standard visualization techniques, we proposed a new technique which can strengthen human understanding towards hidden concepts. We also proposed a technique of using two different self-supervision techniques to extract meaningful concepts related to the type of self-supervision considered and achieved significant performance boost. The most important aspect of our method is that it works nicely in a low data regime and reaches the desired accuracy in a few number of epochs. We reported exhaustive results with CIFAR10, CIFAR100, and AWA2 datasets to show effect of our method with moderate and relatively complex datasets.
Verifying Individual Fairness in Machine Learning Models
Jun 21, 2020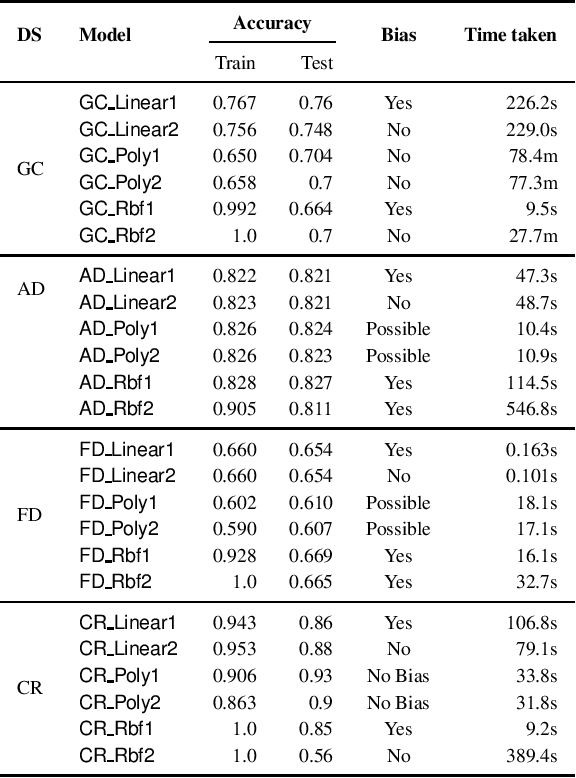
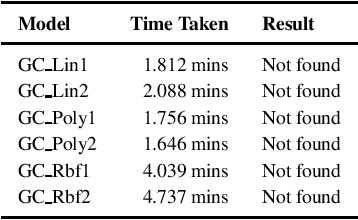

We consider the problem of whether a given decision model, working with structured data, has individual fairness. Following the work of Dwork, a model is individually biased (or unfair) if there is a pair of valid inputs which are close to each other (according to an appropriate metric) but are treated differently by the model (different class label, or large difference in output), and it is unbiased (or fair) if no such pair exists. Our objective is to construct verifiers for proving individual fairness of a given model, and we do so by considering appropriate relaxations of the problem. We construct verifiers which are sound but not complete for linear classifiers, and kernelized polynomial/radial basis function classifiers. We also report the experimental results of evaluating our proposed algorithms on publicly available datasets.
Exploring the Hyperparameter Landscape of Adversarial Robustness
May 09, 2019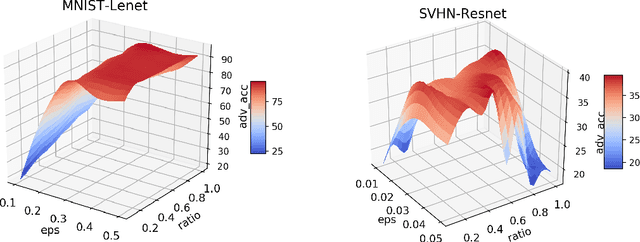
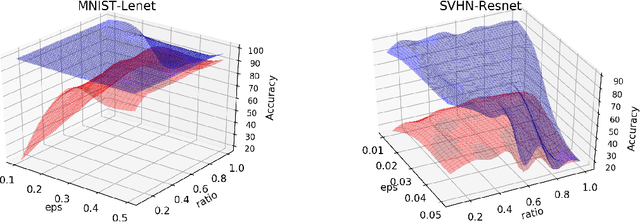
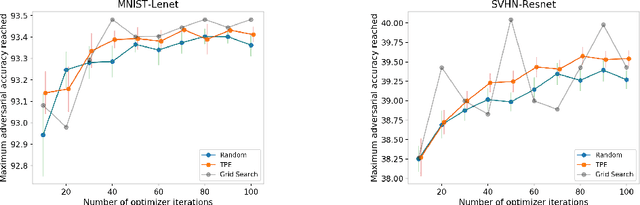
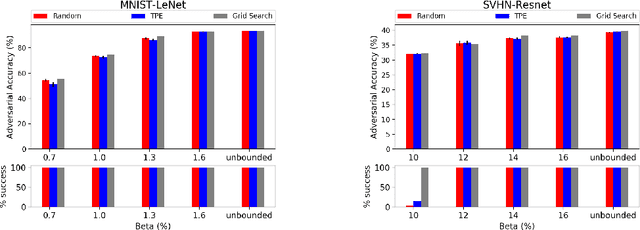
Adversarial training shows promise as an approach for training models that are robust towards adversarial perturbation. In this paper, we explore some of the practical challenges of adversarial training. We present a sensitivity analysis that illustrates that the effectiveness of adversarial training hinges on the settings of a few salient hyperparameters. We show that the robustness surface that emerges across these salient parameters can be surprisingly complex and that therefore no effective one-size-fits-all parameter settings exist. We then demonstrate that we can use the same salient hyperparameters as tuning knob to navigate the tension that can arise between robustness and accuracy. Based on these findings, we present a practical approach that leverages hyperparameter optimization techniques for tuning adversarial training to maximize robustness while keeping the loss in accuracy within a defined budget.
Explaining Deep Learning Models using Causal Inference
Nov 11, 2018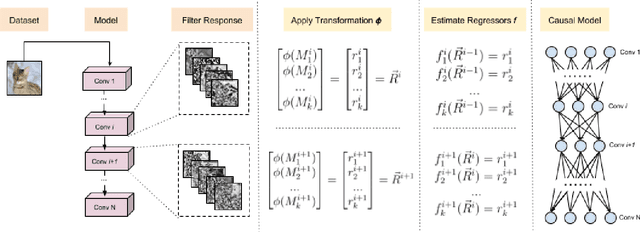
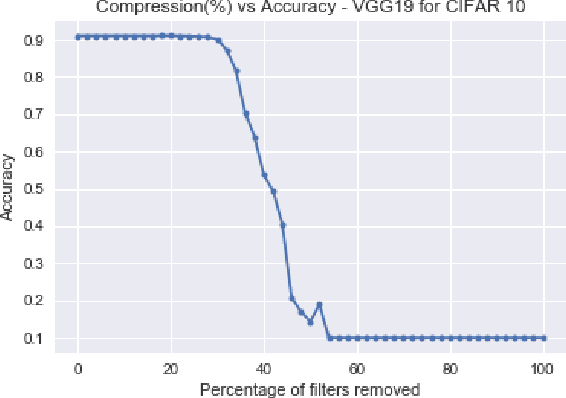

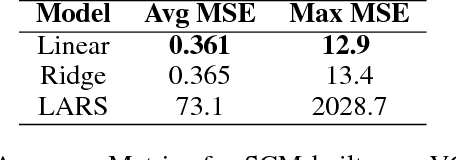
Although deep learning models have been successfully applied to a variety of tasks, due to the millions of parameters, they are becoming increasingly opaque and complex. In order to establish trust for their widespread commercial use, it is important to formalize a principled framework to reason over these models. In this work, we use ideas from causal inference to describe a general framework to reason over CNN models. Specifically, we build a Structural Causal Model (SCM) as an abstraction over a specific aspect of the CNN. We also formulate a method to quantitatively rank the filters of a convolution layer according to their counterfactual importance. We illustrate our approach with popular CNN architectures such as LeNet5, VGG19, and ResNet32.
Hardening Deep Neural Networks via Adversarial Model Cascades
Nov 04, 2018
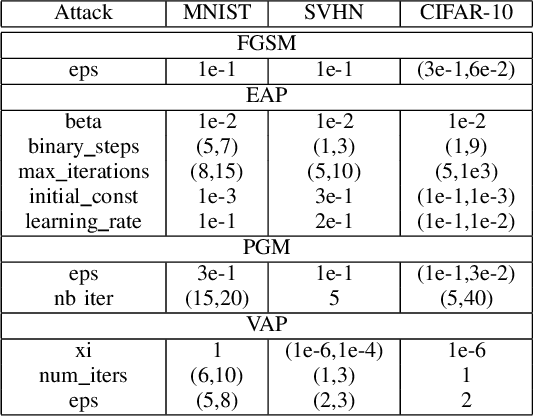
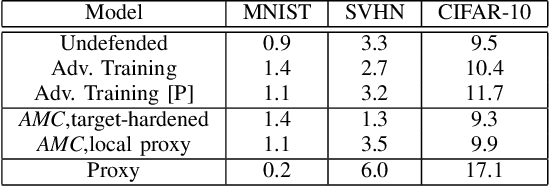
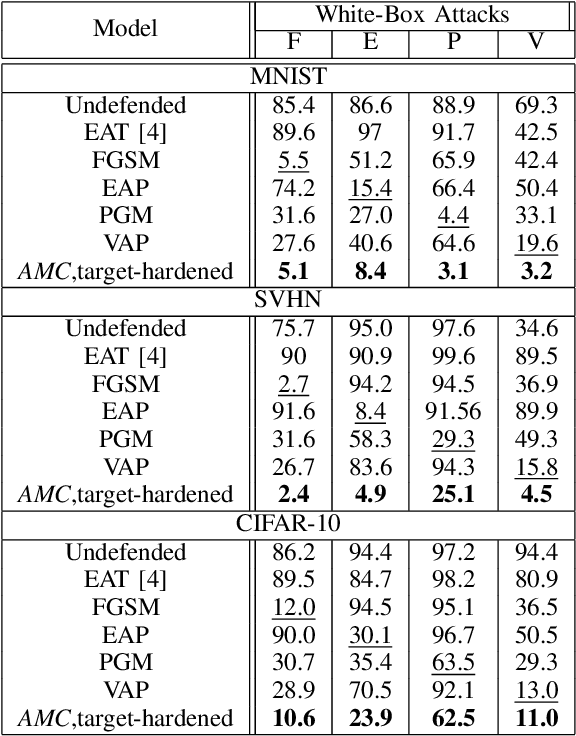
Deep neural networks (DNNs) are vulnerable to malicious inputs crafted by an adversary to produce erroneous outputs. Works on securing neural networks against adversarial examples achieve high empirical robustness on simple datasets such as MNIST. However, these techniques are inadequate when empirically tested on complex data sets such as CIFAR-10 and SVHN. Further, existing techniques are designed to target specific attacks and fail to generalize across attacks. We propose the Adversarial Model Cascades (AMC) as a way to tackle the above inadequacies. Our approach trains a cascade of models sequentially where each model is optimized to be robust towards a mixture of multiple attacks. Ultimately, it yields a single model which is secure against a wide range of attacks; namely FGSM, Elastic, Virtual Adversarial Perturbations and Madry. On an average, AMC increases the model's empirical robustness against various attacks simultaneously, by a significant margin (of 6.225% for MNIST, 5.075% for SVHN and 2.65% for CIFAR10). At the same time, the model's performance on non-adversarial inputs is comparable to the state-of-the-art models.
Debugging Machine Learning Tasks
Mar 23, 2016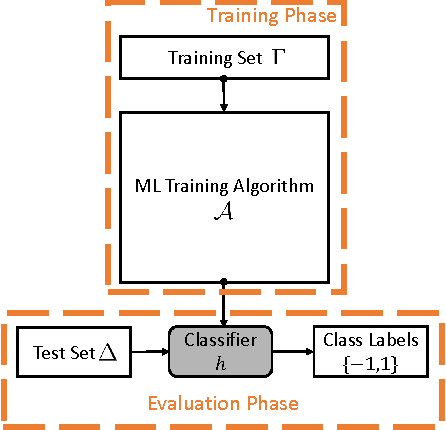
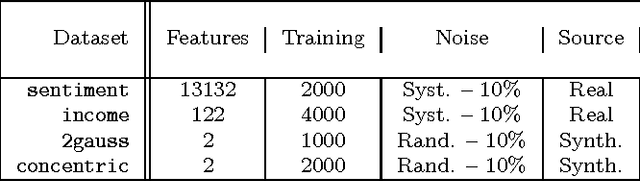
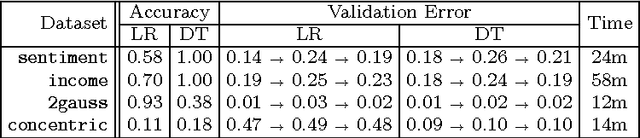
Unlike traditional programs (such as operating systems or word processors) which have large amounts of code, machine learning tasks use programs with relatively small amounts of code (written in machine learning libraries), but voluminous amounts of data. Just like developers of traditional programs debug errors in their code, developers of machine learning tasks debug and fix errors in their data. However, algorithms and tools for debugging and fixing errors in data are less common, when compared to their counterparts for detecting and fixing errors in code. In this paper, we consider classification tasks where errors in training data lead to misclassifications in test points, and propose an automated method to find the root causes of such misclassifications. Our root cause analysis is based on Pearl's theory of causation, and uses Pearl's PS (Probability of Sufficiency) as a scoring metric. Our implementation, Psi, encodes the computation of PS as a probabilistic program, and uses recent work on probabilistic programs and transformations on probabilistic programs (along with gray-box models of machine learning algorithms) to efficiently compute PS. Psi is able to identify root causes of data errors in interesting data sets.