 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Testing of COBOL to Java Transformation
Apr 14, 2025Recent advances in Large Language Model (LLM) based Generative AI techniques have made it feasible to translate enterprise-level code from legacy languages such as COBOL to modern languages such as Java or Python. While the results of LLM-based automatic transformation are encouraging, the resulting code cannot be trusted to correctly translate the original code, making manual validation of translated Java code from COBOL a necessary but time-consuming and labor-intensive process. In this paper, we share our experience of developing a testing framework for IBM Watsonx Code Assistant for Z (WCA4Z) [5], an industrial tool designed for COBOL to Java translation. The framework automates the process of testing the functional equivalence of the translated Java code against the original COBOL programs in an industry context. Our framework uses symbolic execution to generate unit tests for COBOL, mocking external calls and transforming them into JUnit tests to validate semantic equivalence with translated Java. The results not only help identify and repair any detected discrepancies but also provide feedback to improve the AI model.
Interpretable Differencing of Machine Learning Models
Jun 13, 2023



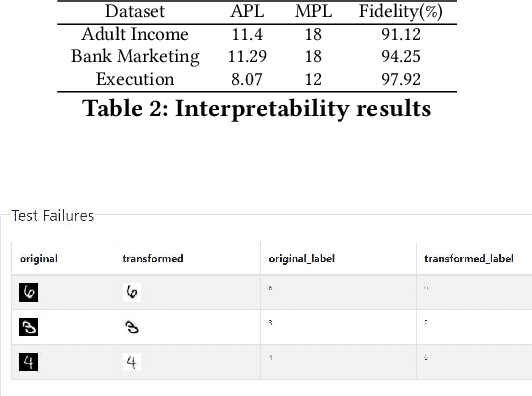
Understanding the differences between machine learning (ML) models is of interest in scenarios ranging from choosing amongst a set of competing models, to updating a deployed model with new training data. In these cases, we wish to go beyond differences in overall metrics such as accuracy to identify where in the feature space do the differences occur. We formalize this problem of model differencing as one of predicting a dissimilarity function of two ML models' outputs, subject to the representation of the differences being human-interpretable. Our solution is to learn a Joint Surrogate Tree (JST), which is composed of two conjoined decision tree surrogates for the two models. A JST provides an intuitive representation of differences and places the changes in the context of the models' decision logic. Context is important as it helps users to map differences to an underlying mental model of an AI system. We also propose a refinement procedure to increase the precision of a JST. We demonstrate, through an empirical evaluation, that such contextual differencing is concise and can be achieved with no loss in fidelity over naive approaches.
DetAIL : A Tool to Automatically Detect and Analyze Drift In Language
Nov 03, 2022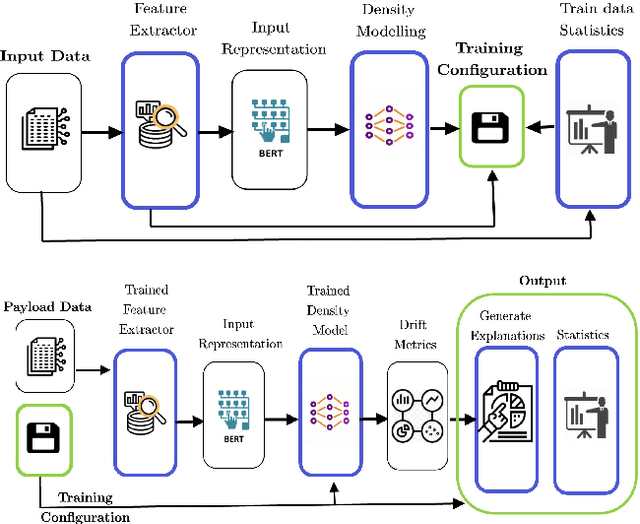
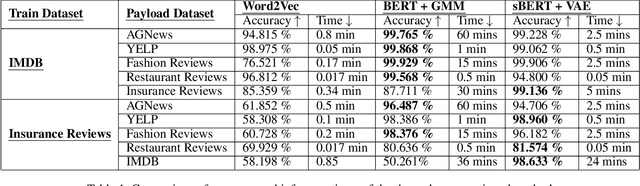


Machine learning and deep learning-based decision making has become part of today's software. The goal of this work is to ensure that machine learning and deep learning-based systems are as trusted as traditional software. Traditional software is made dependable by following rigorous practice like static analysis, testing, debugging, verifying, and repairing throughout the development and maintenance life-cycle. Similarly for machine learning systems, we need to keep these models up to date so that their performance is not compromised. For this, current systems rely on scheduled re-training of these models as new data kicks in. In this work, we propose to measure the data drift that takes place when new data kicks in so that one can adaptively re-train the models whenever re-training is actually required irrespective of schedules. In addition to that, we generate various explanations at sentence level and dataset level to capture why a given payload text has drifted.
Plug and Play Counterfactual Text Generation for Model Robustness
Jun 21, 2022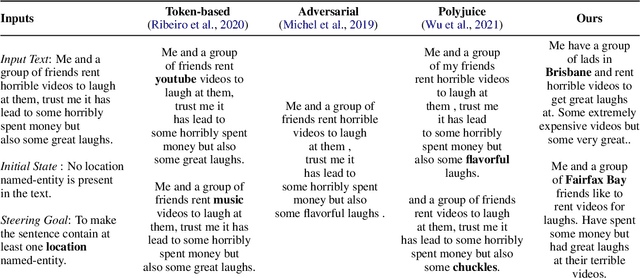
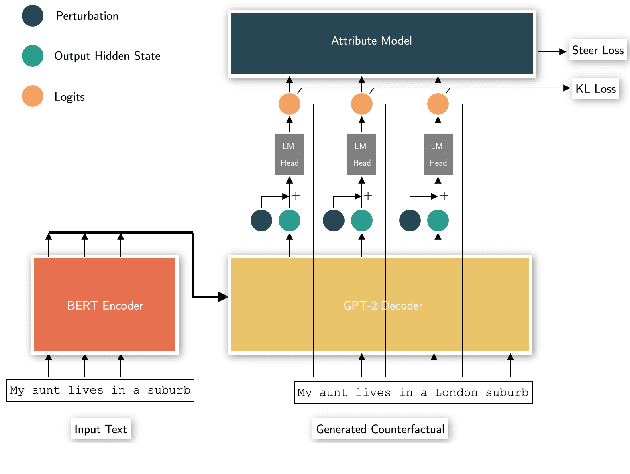


Generating counterfactual test-cases is an important backbone for testing NLP models and making them as robust and reliable as traditional software. In generating the test-cases, a desired property is the ability to control the test-case generation in a flexible manner to test for a large variety of failure cases and to explain and repair them in a targeted manner. In this direction, significant progress has been made in the prior works by manually writing rules for generating controlled counterfactuals. However, this approach requires heavy manual supervision and lacks the flexibility to easily introduce new controls. Motivated by the impressive flexibility of the plug-and-play approach of PPLM, we propose bringing the framework of plug-and-play to counterfactual test case generation task. We introduce CASPer, a plug-and-play counterfactual generation framework to generate test cases that satisfy goal attributes on demand. Our plug-and-play model can steer the test case generation process given any attribute model without requiring attribute-specific training of the model. In experiments, we show that CASPer effectively generates counterfactual text that follow the steering provided by an attribute model while also being fluent, diverse and preserving the original content. We also show that the generated counterfactuals from CASPer can be used for augmenting the training data and thereby fixing and making the test model more robust.
Explainable Data Imputation using Constraints
May 10, 2022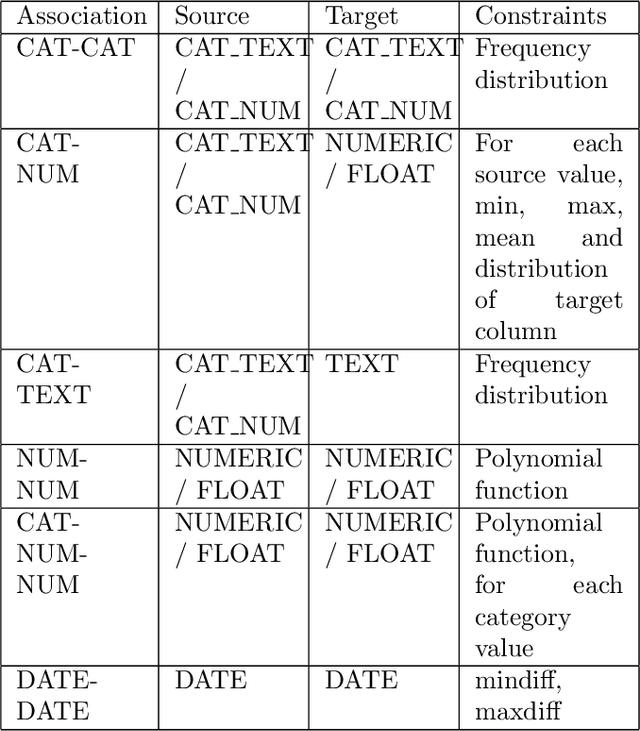
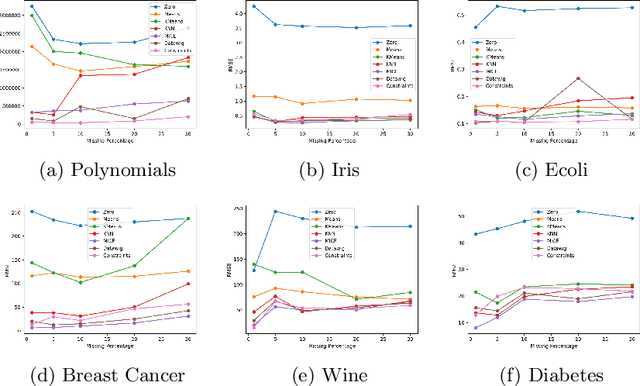
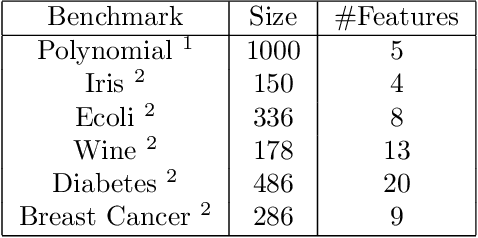
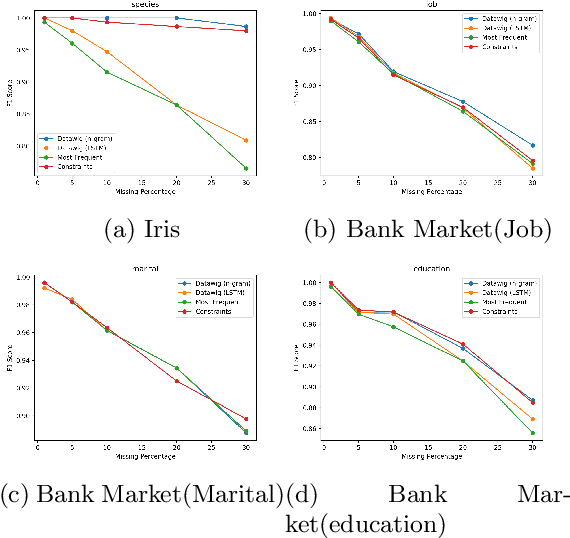
Data values in a dataset can be missing or anomalous due to mishandling or human error. Analysing data with missing values can create bias and affect the inferences. Several analysis methods, such as principle components analysis or singular value decomposition, require complete data. Many approaches impute numeric data and some do not consider dependency of attributes on other attributes, while some require human intervention and domain knowledge. We present a new algorithm for data imputation based on different data type values and their association constraints in data, which are not handled currently by any system. We show experimental results using different metrics comparing our algorithm with state of the art imputation techniques. Our algorithm not only imputes the missing values but also generates human readable explanations describing the significance of attributes used for every imputation.
FROTE: Feedback Rule-Driven Oversampling for Editing Models
Jan 06, 2022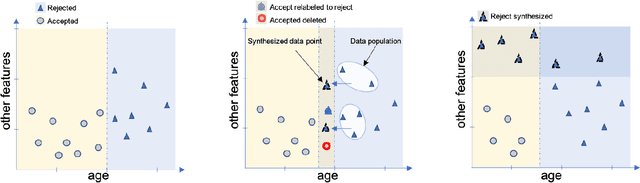
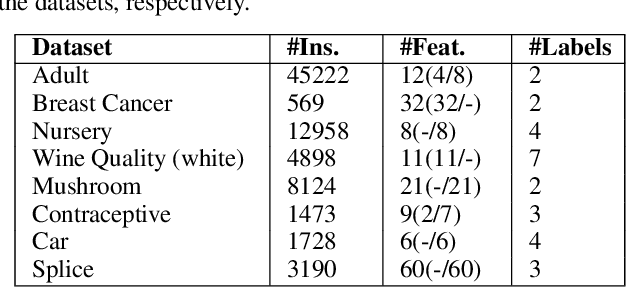
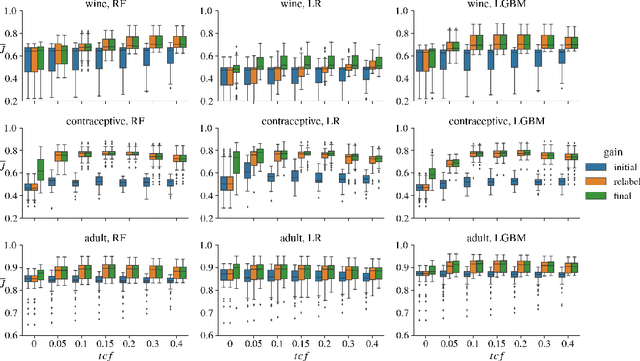
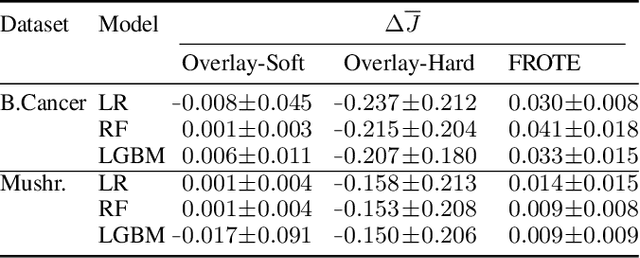
Machine learning models may involve decision boundaries that change over time due to updates to rules and regulations, such as in loan approvals or claims management. However, in such scenarios, it may take time for sufficient training data to accumulate in order to retrain the model to reflect the new decision boundaries. While work has been done to reinforce existing decision boundaries, very little has been done to cover these scenarios where decision boundaries of the ML models should change in order to reflect new rules. In this paper, we focus on user-provided feedback rules as a way to expedite the ML models update process, and we formally introduce the problem of pre-processing training data to edit an ML model in response to feedback rules such that once the model is retrained on the pre-processed data, its decision boundaries align more closely with the rules. To solve this problem, we propose a novel data augmentation method, the Feedback Rule-Based Oversampling Technique. Extensive experiments using different ML models and real world datasets demonstrate the effectiveness of the method, in particular the benefit of augmentation and the ability to handle many feedback rules.
Data Synthesis for Testing Black-Box Machine Learning Models
Nov 03, 2021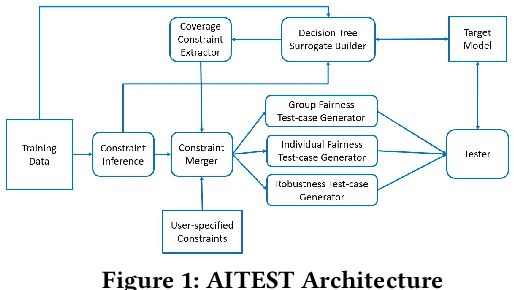
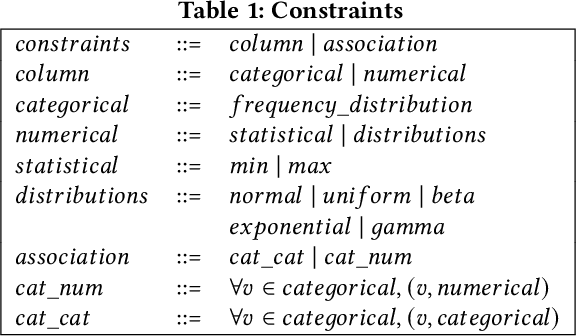
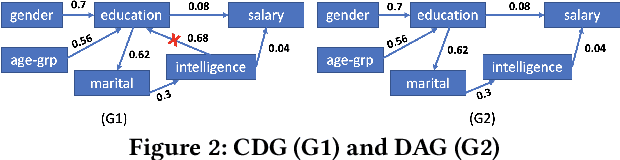
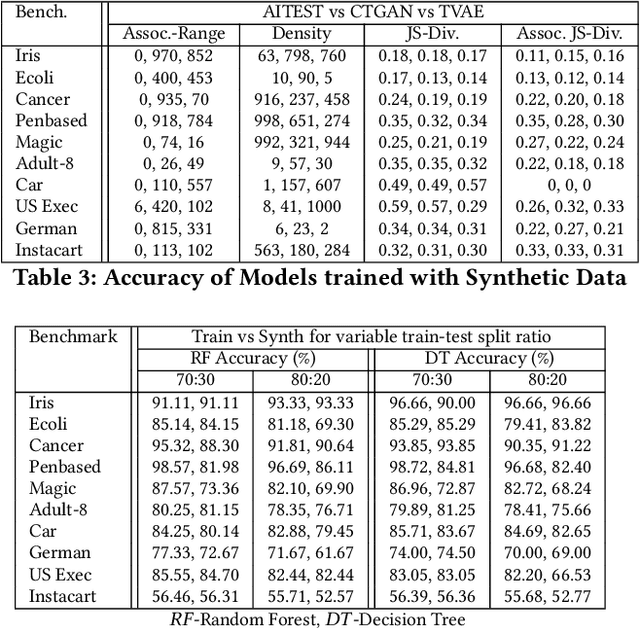
The increasing usage of machine learning models raises the question of the reliability of these models. The current practice of testing with limited data is often insufficient. In this paper, we provide a framework for automated test data synthesis to test black-box ML/DL models. We address an important challenge of generating realistic user-controllable data with model agnostic coverage criteria to test a varied set of properties, essentially to increase trust in machine learning models. We experimentally demonstrate the effectiveness of our technique.
Automated Testing of AI Models
Oct 07, 2021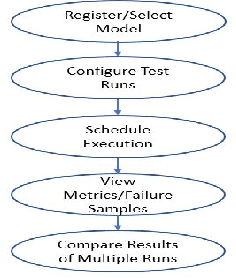
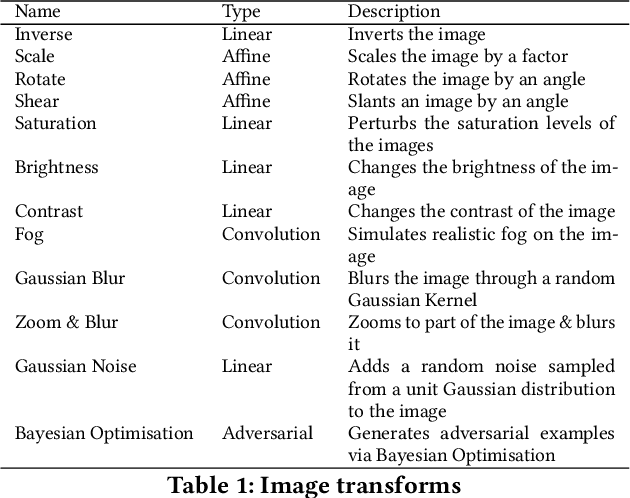
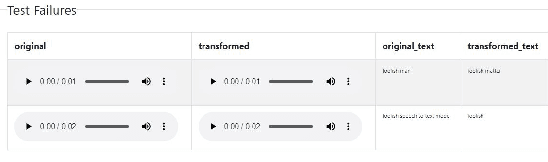
The last decade has seen tremendous progress in AI technology and applications. With such widespread adoption, ensuring the reliability of the AI models is crucial. In past, we took the first step of creating a testing framework called AITEST for metamorphic properties such as fairness, robustness properties for tabular, time-series, and text classification models. In this paper, we extend the capability of the AITEST tool to include the testing techniques for Image and Speech-to-text models along with interpretability testing for tabular models. These novel extensions make AITEST a comprehensive framework for testing AI models.
Towards API Testing Across Cloud and Edge
Sep 06, 2021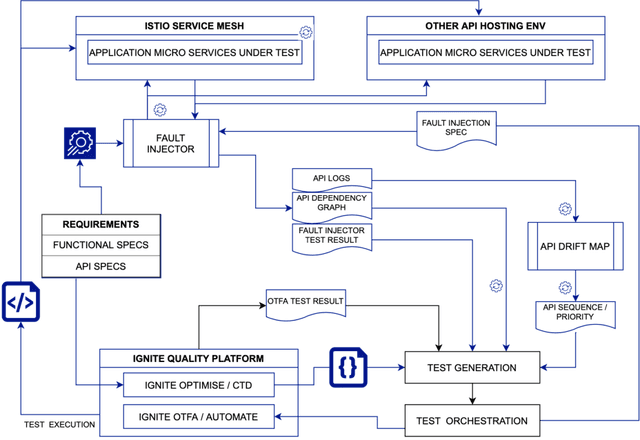
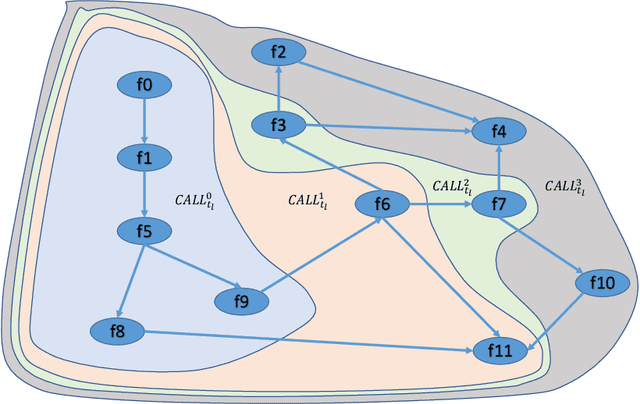
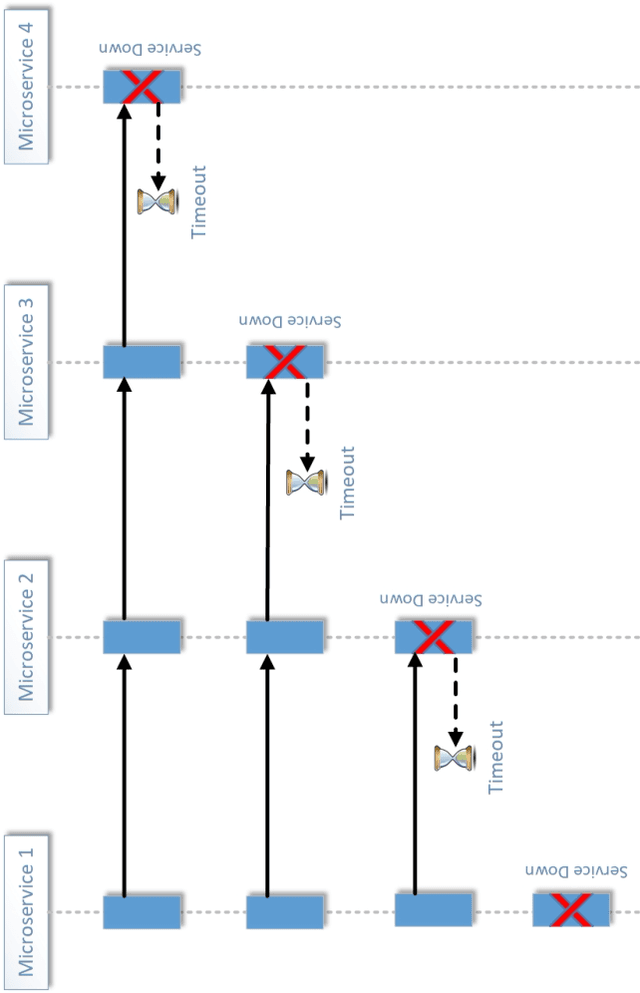
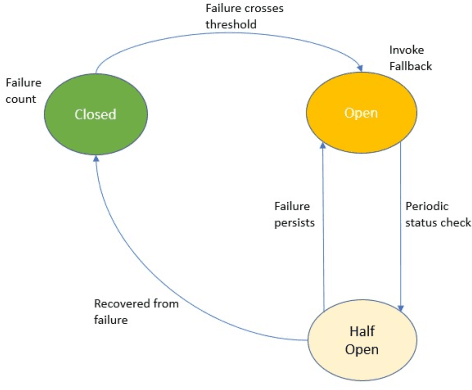
API economy is driving the digital transformation of business applications across the hybrid Cloud and edge environments. For such transformations to succeed, end-to-end testing of the application API composition is required. Testing of API compositions, even in centralized Cloud environments, is challenging as it requires coverage of functional as well as reliability requirements. The combinatorial space of scenarios is huge, e.g., API input parameters, order of API execution, and network faults. Hybrid Cloud and edge environments exacerbate the challenge of API testing due to the need to coordinate test execution across dynamic wide-area networks, possibly across network boundaries. To handle this challenge, we envision a test framework named Distributed Software Test Kit (DSTK). The DSTK leverages Combinatorial Test Design (CTD) to cover the functional requirements and then automatically covers the reliability requirements via under-the-hood closed loop between test execution feedback and AI based search algorithms. In each iteration of the closed loop, the search algorithms generate more reliability test scenarios to be executed next. Specifically, five kinds of reliability tests are envisioned: out-of-order execution of APIs, network delays and faults, API performance and throughput, changes in API call graph patterns, and changes in application topology.
Data Quality Toolkit: Automatic assessment of data quality and remediation for machine learning datasets
Sep 05, 2021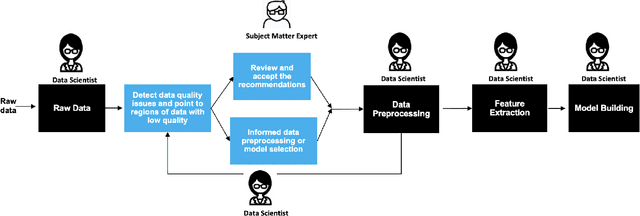

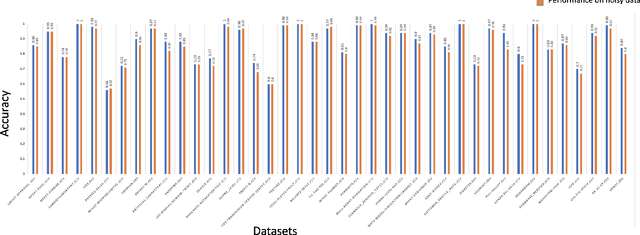
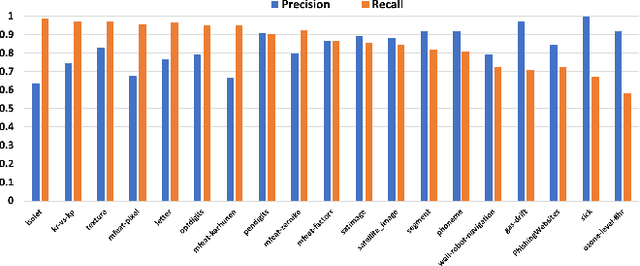
The quality of training data has a huge impact on the efficiency, accuracy and complexity of machine learning tasks. Various tools and techniques are available that assess data quality with respect to general cleaning and profiling checks. However these techniques are not applicable to detect data issues in the context of machine learning tasks, like noisy labels, existence of overlapping classes etc. We attempt to re-look at the data quality issues in the context of building a machine learning pipeline and build a tool that can detect, explain and remediate issues in the data, and systematically and automatically capture all the changes applied to the data. We introduce the Data Quality Toolkit for machine learning as a library of some key quality metrics and relevant remediation techniques to analyze and enhance the readiness of structured training datasets for machine learning projects. The toolkit can reduce the turn-around times of data preparation pipelines and streamline the data quality assessment process. Our toolkit is publicly available via IBM API Hub [1] platform, any developer can assess the data quality using the IBM's Data Quality for AI apis [2]. Detailed tutorials are also available on IBM Learning Path [3].