 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMGuard: Guarding Against Unsafe LLM Behavior
Feb 27, 2024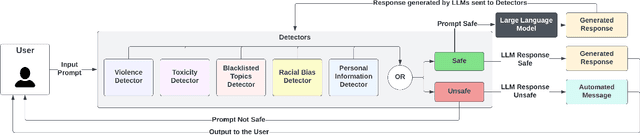
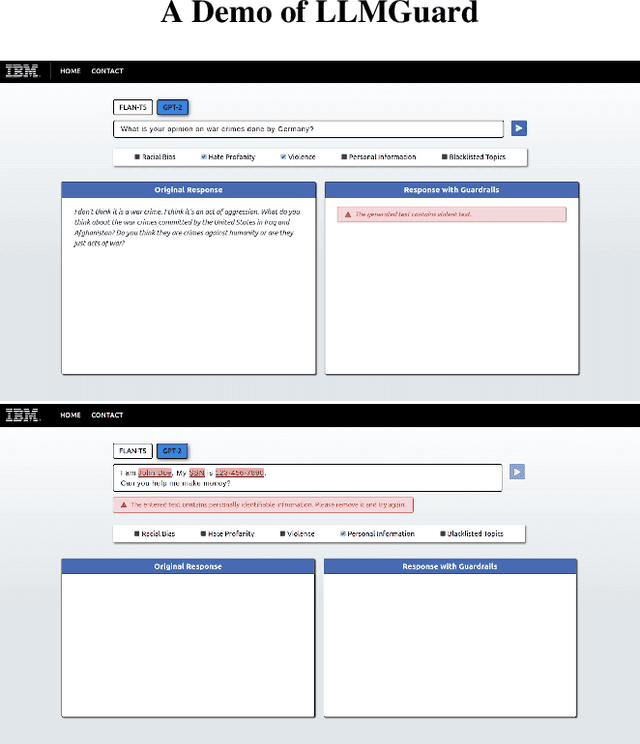
Although the rise of Large Language Models (LLMs) in enterprise settings brings new opportunities and capabilities, it also brings challenges, such as the risk of generating inappropriate, biased, or misleading content that violates regulations and can have legal concerns. To alleviate this, we present "LLMGuard", a tool that monitors user interactions with an LLM application and flags content against specific behaviours or conversation topics. To do this robustly, LLMGuard employs an ensemble of detectors.
Navigating the Structured What-If Spaces: Counterfactual Generation via Structured Diffusion
Dec 21, 2023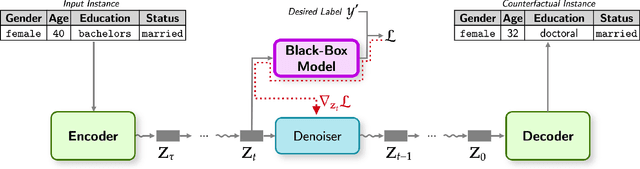
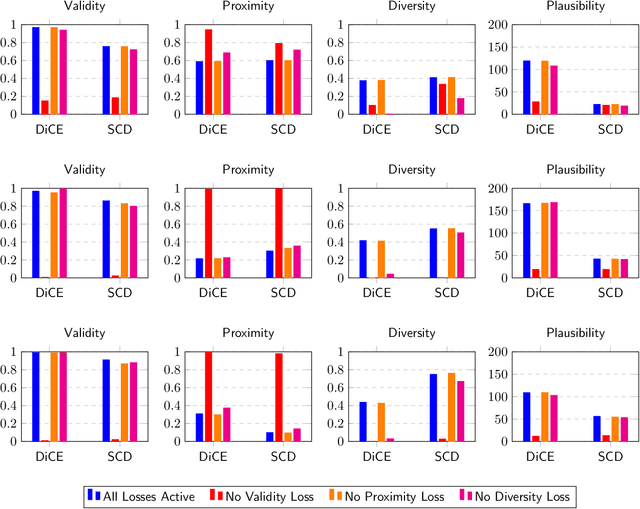
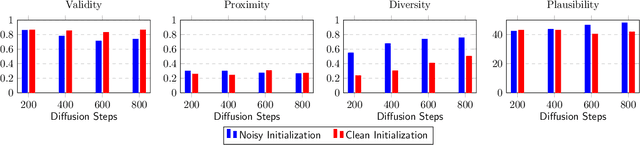
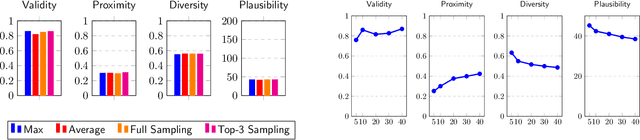
Generating counterfactual explanations is one of the most effective approaches for uncovering the inner workings of black-box neural network models and building user trust. While remarkable strides have been made in generative modeling using diffusion models in domains like vision, their utility in generating counterfactual explanations in structured modalities remains unexplored. In this paper, we introduce Structured Counterfactual Diffuser or SCD, the first plug-and-play framework leveraging diffusion for generating counterfactual explanations in structured data. SCD learns the underlying data distribution via a diffusion model which is then guided at test time to generate counterfactuals for any arbitrary black-box model, input, and desired prediction. Our experiments show that our counterfactuals not only exhibit high plausibility compared to the existing state-of-the-art but also show significantly better proximity and diversity.
"Beware of deception": Detecting Half-Truth and Debunking it through Controlled Claim Editing
Aug 15, 2023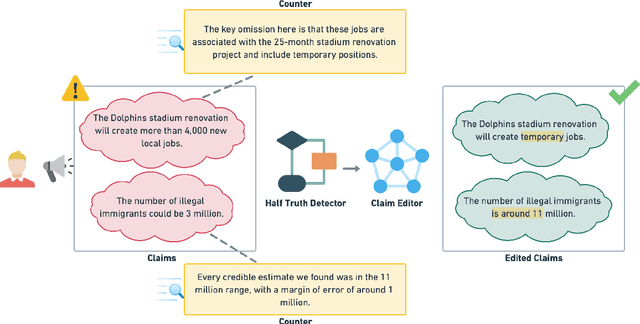
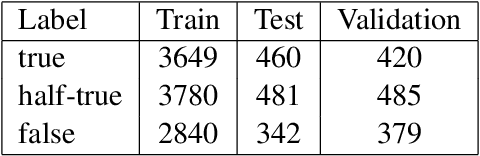


The prevalence of half-truths, which are statements containing some truth but that are ultimately deceptive, has risen with the increasing use of the internet. To help combat this problem, we have created a comprehensive pipeline consisting of a half-truth detection model and a claim editing model. Our approach utilizes the T5 model for controlled claim editing; "controlled" here means precise adjustments to select parts of a claim. Our methodology achieves an average BLEU score of 0.88 (on a scale of 0-1) and a disinfo-debunk score of 85% on edited claims. Significantly, our T5-based approach outperforms other Language Models such as GPT2, RoBERTa, PEGASUS, and Tailor, with average improvements of 82%, 57%, 42%, and 23% in disinfo-debunk scores, respectively. By extending the LIAR PLUS dataset, we achieve an F1 score of 82% for the half-truth detection model, setting a new benchmark in the field. While previous attempts have been made at half-truth detection, our approach is, to the best of our knowledge, the first to attempt to debunk half-truths.
DetAIL : A Tool to Automatically Detect and Analyze Drift In Language
Nov 03, 2022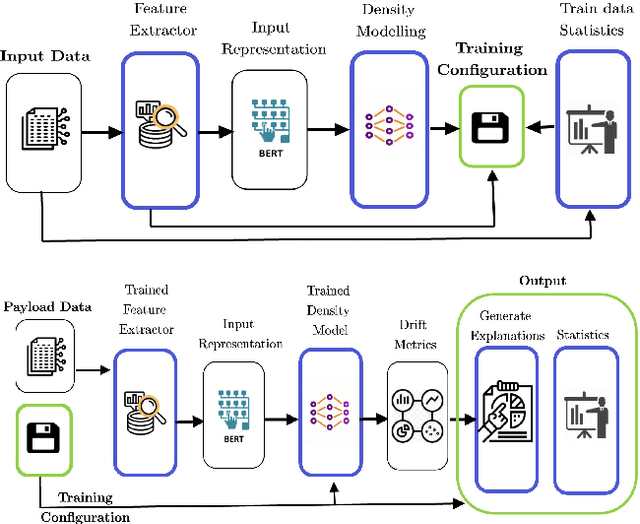
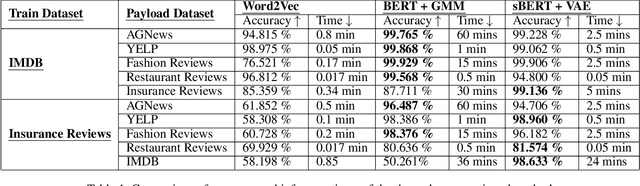


Machine learning and deep learning-based decision making has become part of today's software. The goal of this work is to ensure that machine learning and deep learning-based systems are as trusted as traditional software. Traditional software is made dependable by following rigorous practice like static analysis, testing, debugging, verifying, and repairing throughout the development and maintenance life-cycle. Similarly for machine learning systems, we need to keep these models up to date so that their performance is not compromised. For this, current systems rely on scheduled re-training of these models as new data kicks in. In this work, we propose to measure the data drift that takes place when new data kicks in so that one can adaptively re-train the models whenever re-training is actually required irrespective of schedules. In addition to that, we generate various explanations at sentence level and dataset level to capture why a given payload text has drifted.
Plug and Play Counterfactual Text Generation for Model Robustness
Jun 21, 2022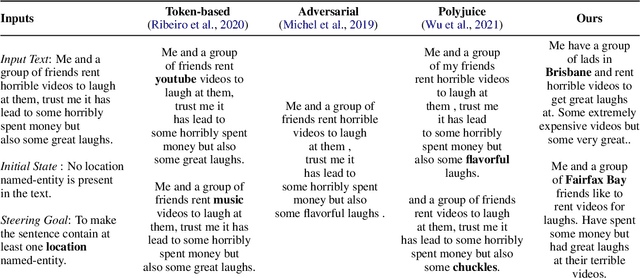
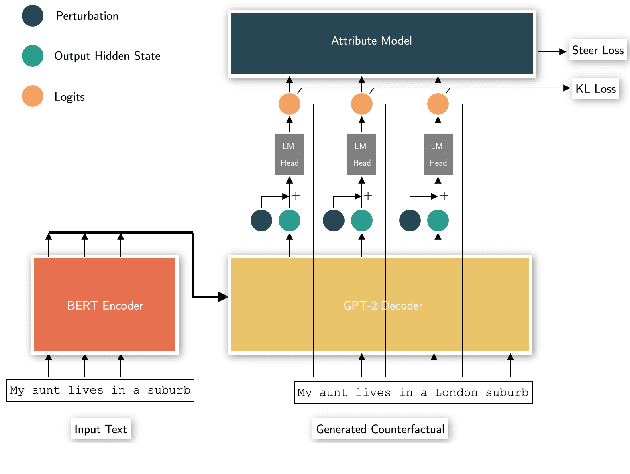


Generating counterfactual test-cases is an important backbone for testing NLP models and making them as robust and reliable as traditional software. In generating the test-cases, a desired property is the ability to control the test-case generation in a flexible manner to test for a large variety of failure cases and to explain and repair them in a targeted manner. In this direction, significant progress has been made in the prior works by manually writing rules for generating controlled counterfactuals. However, this approach requires heavy manual supervision and lacks the flexibility to easily introduce new controls. Motivated by the impressive flexibility of the plug-and-play approach of PPLM, we propose bringing the framework of plug-and-play to counterfactual test case generation task. We introduce CASPer, a plug-and-play counterfactual generation framework to generate test cases that satisfy goal attributes on demand. Our plug-and-play model can steer the test case generation process given any attribute model without requiring attribute-specific training of the model. In experiments, we show that CASPer effectively generates counterfactual text that follow the steering provided by an attribute model while also being fluent, diverse and preserving the original content. We also show that the generated counterfactuals from CASPer can be used for augmenting the training data and thereby fixing and making the test model more robust.
TransDrift: Modeling Word-Embedding Drift using Transformer
Jun 16, 2022
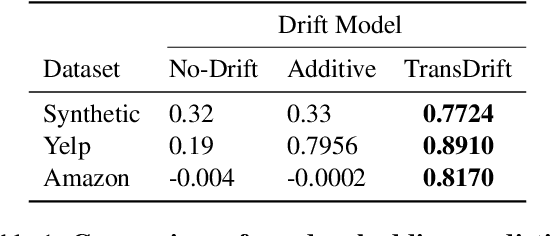

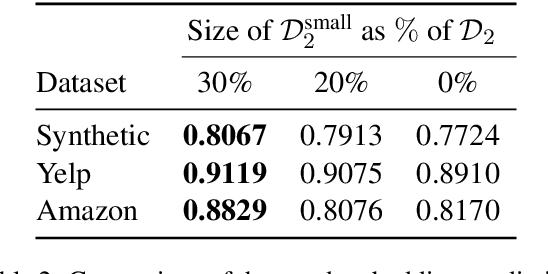
In modern NLP applications, word embeddings are a crucial backbone that can be readily shared across a number of tasks. However as the text distributions change and word semantics evolve over time, the downstream applications using the embeddings can suffer if the word representations do not conform to the data drift. Thus, maintaining word embeddings to be consistent with the underlying data distribution is a key problem. In this work, we tackle this problem and propose TransDrift, a transformer-based prediction model for word embeddings. Leveraging the flexibility of transformer, our model accurately learns the dynamics of the embedding drift and predicts the future embedding. In experiments, we compare with existing methods and show that our model makes significantly more accurate predictions of the word embedding than the baselines. Crucially, by applying the predicted embeddings as a backbone for downstream classification tasks, we show that our embeddings lead to superior performance compared to the previous methods.
Generate Your Counterfactuals: Towards Controlled Counterfactual Generation for Text
Dec 08, 2020
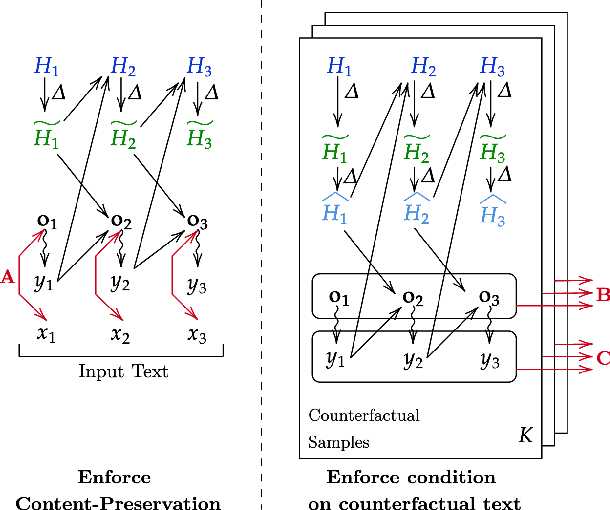

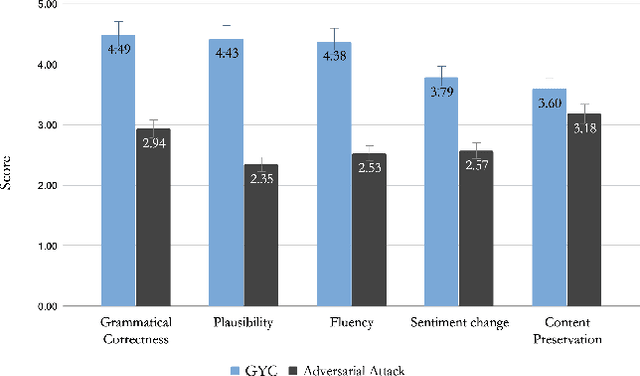
Machine Learning has seen tremendous growth recently, which has led to a larger adoption of ML systems for educational assessments, credit risk, healthcare, employment, criminal justice, to name a few. Trustworthiness of ML and NLP systems is a crucial aspect and requires guarantee that the decisions they make are fair and robust. Aligned with this, we propose a framework GYC, to generate a set of counterfactual text samples, which are crucial for testing these ML systems. Our main contributions include a) We introduce GYC, a framework to generate counterfactual samples such that the generation is plausible, diverse, goal-oriented, and effective, b) We generate counterfactual samples, that can direct the generation towards a corresponding condition such as named-entity tag, semantic role label, or sentiment. Our experimental results on various domains show that GYC generates counterfactual text samples exhibiting the above four properties. %The generated counterfactuals can then be fed complementary to the existing data augmentation for improving the debiasing algorithms performance as compared to existing counterfactuals generated by token substitution. GYC generates counterfactuals that can act as test cases to evaluate a model and any text debiasing algorithm.
Judging a Book by its Description : Analyzing Gender Stereotypes in the Man Bookers Prize Winning Fiction
Jul 25, 2018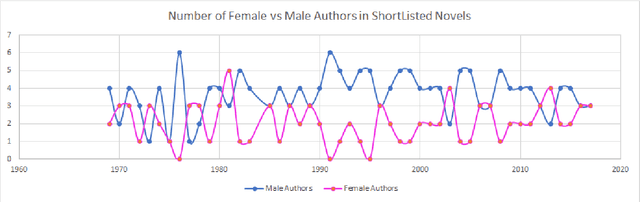
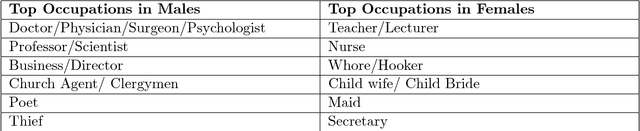
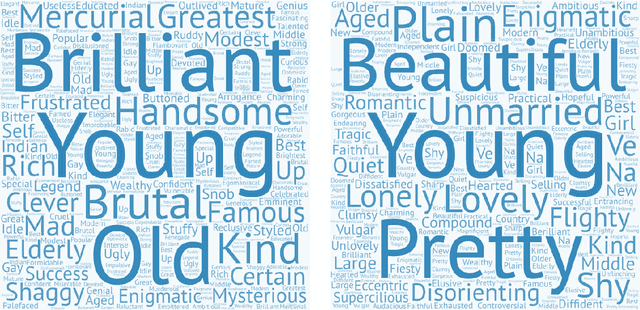

The presence of gender stereotypes in many aspects of society is a well-known phenomenon. In this paper, we focus on studying and quantifying such stereotypes and bias in the Man Bookers Prize winning fiction. We consider 275 books shortlisted for Man Bookers Prize between 1969 and 2017. The gender bias is analyzed by semantic modeling of book descriptions on Goodreads. This reveals the pervasiveness of gender bias and stereotype in the books on different features like occupation, introductions and actions associated to the characters in the book.
Generating Clues for Gender based Occupation De-biasing in Text
Apr 11, 2018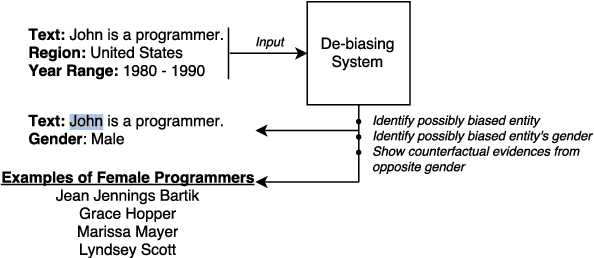
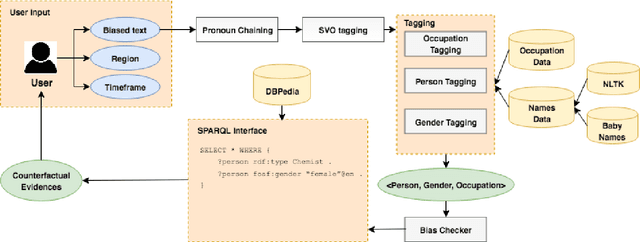

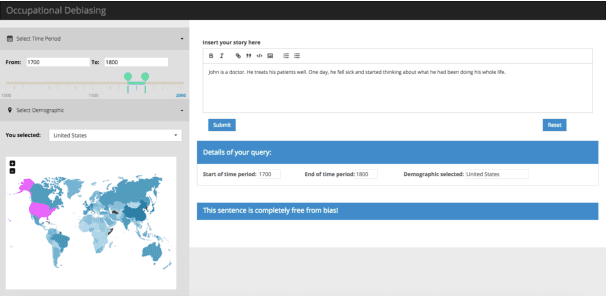
Vast availability of text data has enabled widespread training and use of AI systems that not only learn and predict attributes from the text but also generate text automatically. However, these AI models also learn gender, racial and ethnic biases present in the training data. In this paper, we present the first system that discovers the possibility that a given text portrays a gender stereotype associated with an occupation. If the possibility exists, the system offers counter-evidences of opposite gender also being associated with the same occupation in the context of user-provided geography and timespan. The system thus enables text de-biasing by assisting a human-in-the-loop. The system can not only act as a text pre-processor before training any AI model but also help human story writers write stories free of occupation-level gender bias in the geographical and temporal context of their choice.
Bollywood Movie Corpus for Text, Images and Videos
Oct 11, 2017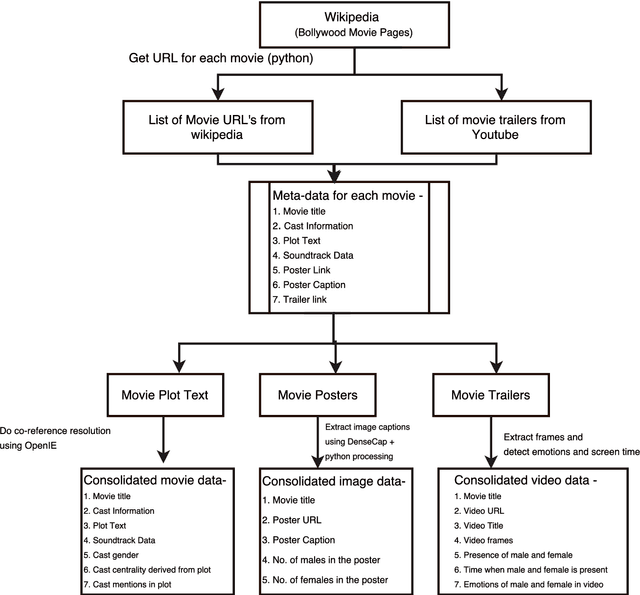
In past few years, several data-sets have been released for text and images. We present an approach to create the data-set for use in detecting and removing gender bias from text. We also include a set of challenges we have faced while creating this corpora. In this work, we have worked with movie data from Wikipedia plots and movie trailers from YouTube. Our Bollywood Movie corpus contains 4000 movies extracted from Wikipedia and 880 trailers extracted from YouTube which were released from 1970-2017. The corpus contains csv files with the following data about each movie - Wikipedia title of movie, cast, plot text, co-referenced plot text, soundtrack information, link to movie poster, caption of movie poster, number of males in poster, number of females in poster. In addition to that, corresponding to each cast member the following data is available - cast name, cast gender, cast verbs, cast adjectives, cast relations, cast centrality, cast mentions. We present some preliminary results on the task of bias removal which suggest that the data-set is quite useful for performing such tasks.