 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBollywood Movie Corpus for Text, Images and Videos
Oct 11, 2017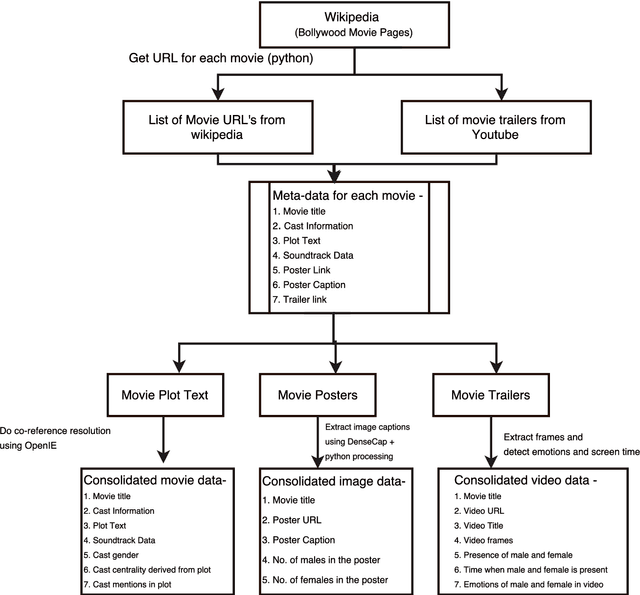
In past few years, several data-sets have been released for text and images. We present an approach to create the data-set for use in detecting and removing gender bias from text. We also include a set of challenges we have faced while creating this corpora. In this work, we have worked with movie data from Wikipedia plots and movie trailers from YouTube. Our Bollywood Movie corpus contains 4000 movies extracted from Wikipedia and 880 trailers extracted from YouTube which were released from 1970-2017. The corpus contains csv files with the following data about each movie - Wikipedia title of movie, cast, plot text, co-referenced plot text, soundtrack information, link to movie poster, caption of movie poster, number of males in poster, number of females in poster. In addition to that, corresponding to each cast member the following data is available - cast name, cast gender, cast verbs, cast adjectives, cast relations, cast centrality, cast mentions. We present some preliminary results on the task of bias removal which suggest that the data-set is quite useful for performing such tasks.