 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Sentiment Analysis: Perceived vs Induced Sentiments
Dec 12, 2023Social media has created a global network where people can easily access and exchange vast information. This information gives rise to a variety of opinions, reflecting both positive and negative viewpoints. GIFs stand out as a multimedia format offering a visually engaging way for users to communicate. In this research, we propose a multimodal framework that integrates visual and textual features to predict the GIF sentiment. It also incorporates attributes including face emotion detection and OCR generated captions to capture the semantic aspects of the GIF. The developed classifier achieves an accuracy of 82.7% on Twitter GIFs, which is an improvement over state-of-the-art models. Moreover, we have based our research on the ReactionGIF dataset, analysing the variance in sentiment perceived by the author and sentiment induced in the reader
Can GAN-induced Attribute Manipulations Impact Face Recognition?
Sep 07, 2022
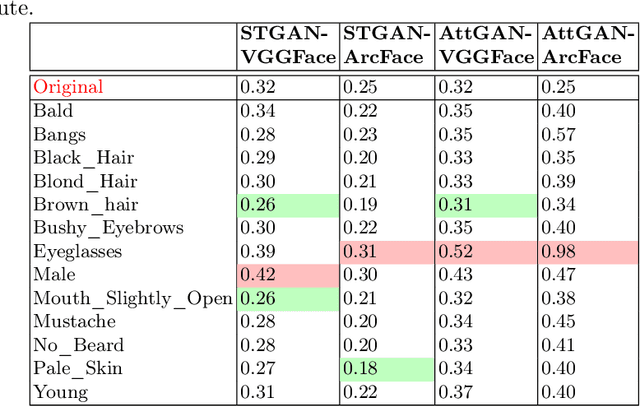
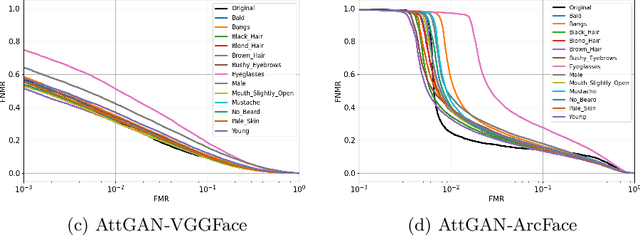
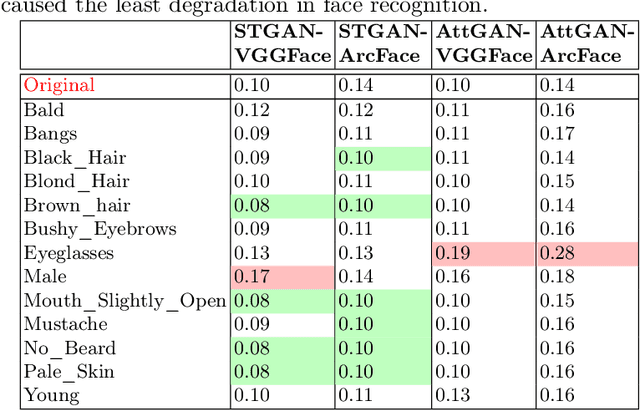
Impact due to demographic factors such as age, sex, race, etc., has been studied extensively in automated face recognition systems. However, the impact of \textit{digitally modified} demographic and facial attributes on face recognition is relatively under-explored. In this work, we study the effect of attribute manipulations induced via generative adversarial networks (GANs) on face recognition performance. We conduct experiments on the CelebA dataset by intentionally modifying thirteen attributes using AttGAN and STGAN and evaluating their impact on two deep learning-based face verification methods, ArcFace and VGGFace. Our findings indicate that some attribute manipulations involving eyeglasses and digital alteration of sex cues can significantly impair face recognition by up to 73% and need further analysis.
Bollywood Movie Corpus for Text, Images and Videos
Oct 11, 2017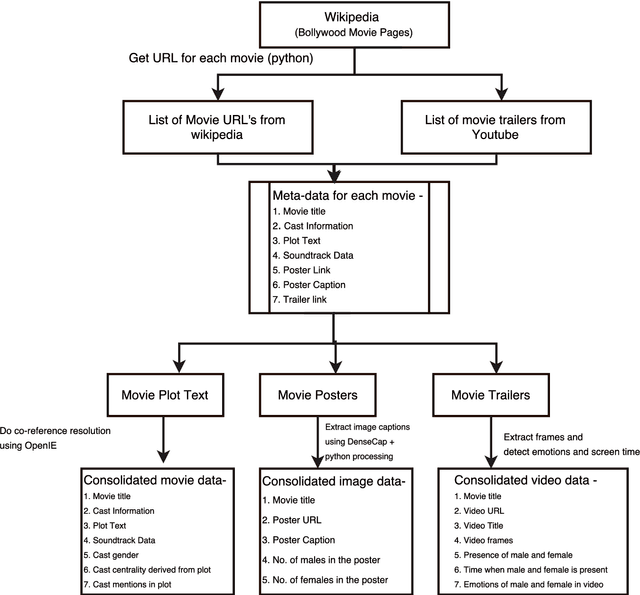
In past few years, several data-sets have been released for text and images. We present an approach to create the data-set for use in detecting and removing gender bias from text. We also include a set of challenges we have faced while creating this corpora. In this work, we have worked with movie data from Wikipedia plots and movie trailers from YouTube. Our Bollywood Movie corpus contains 4000 movies extracted from Wikipedia and 880 trailers extracted from YouTube which were released from 1970-2017. The corpus contains csv files with the following data about each movie - Wikipedia title of movie, cast, plot text, co-referenced plot text, soundtrack information, link to movie poster, caption of movie poster, number of males in poster, number of females in poster. In addition to that, corresponding to each cast member the following data is available - cast name, cast gender, cast verbs, cast adjectives, cast relations, cast centrality, cast mentions. We present some preliminary results on the task of bias removal which suggest that the data-set is quite useful for performing such tasks.