 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparison of Graph Neural Networks for Malware Classification
Mar 22, 2023Managing the threat posed by malware requires accurate detection and classification techniques. Traditional detection strategies, such as signature scanning, rely on manual analysis of malware to extract relevant features, which is labor intensive and requires expert knowledge. Function call graphs consist of a set of program functions and their inter-procedural calls, providing a rich source of information that can be leveraged to classify malware without the labor intensive feature extraction step of traditional techniques. In this research, we treat malware classification as a graph classification problem. Based on Local Degree Profile features, we train a wide range of Graph Neural Network (GNN) architectures to generate embeddings which we then classify. We find that our best GNN models outperform previous comparable research involving the well-known MalNet-Tiny Android malware dataset. In addition, our GNN models do not suffer from the overfitting issues that commonly afflict non-GNN techniques, although GNN models require longer training times.
Bollywood Movie Corpus for Text, Images and Videos
Oct 11, 2017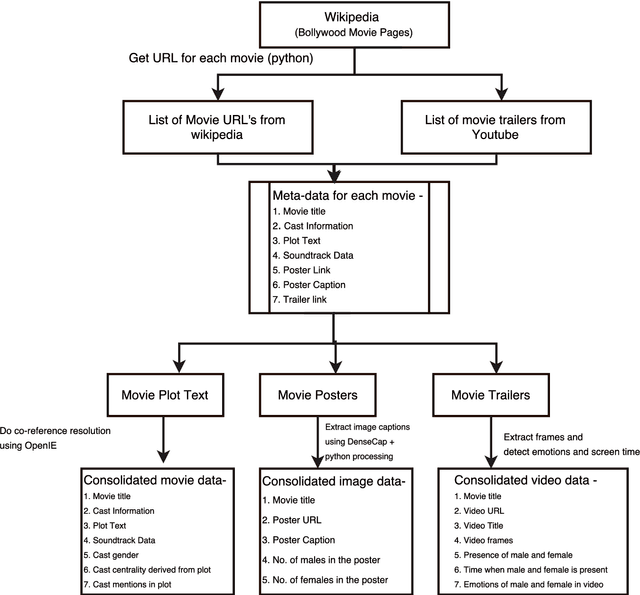
In past few years, several data-sets have been released for text and images. We present an approach to create the data-set for use in detecting and removing gender bias from text. We also include a set of challenges we have faced while creating this corpora. In this work, we have worked with movie data from Wikipedia plots and movie trailers from YouTube. Our Bollywood Movie corpus contains 4000 movies extracted from Wikipedia and 880 trailers extracted from YouTube which were released from 1970-2017. The corpus contains csv files with the following data about each movie - Wikipedia title of movie, cast, plot text, co-referenced plot text, soundtrack information, link to movie poster, caption of movie poster, number of males in poster, number of females in poster. In addition to that, corresponding to each cast member the following data is available - cast name, cast gender, cast verbs, cast adjectives, cast relations, cast centrality, cast mentions. We present some preliminary results on the task of bias removal which suggest that the data-set is quite useful for performing such tasks.