 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransforming Chatbot Text: A Sequence-to-Sequence Approach
Jun 15, 2025Due to advances in Large Language Models (LLMs) such as ChatGPT, the boundary between human-written text and AI-generated text has become blurred. Nevertheless, recent work has demonstrated that it is possible to reliably detect GPT-generated text. In this paper, we adopt a novel strategy to adversarially transform GPT-generated text using sequence-to-sequence (Seq2Seq) models, with the goal of making the text more human-like. We experiment with the Seq2Seq models T5-small and BART which serve to modify GPT-generated sentences to include linguistic, structural, and semantic components that may be more typical of human-authored text. Experiments show that classification models trained to distinguish GPT-generated text are significantly less accurate when tested on text that has been modified by these Seq2Seq models. However, after retraining classification models on data generated by our Seq2Seq technique, the models are able to distinguish the transformed GPT-generated text from human-generated text with high accuracy. This work adds to the accumulating knowledge of text transformation as a tool for both attack -- in the sense of defeating classification models -- and defense -- in the sense of improved classifiers -- thereby advancing our understanding of AI-generated text.
AGRO: An Autonomous AI Rover for Precision Agriculture
May 02, 2025
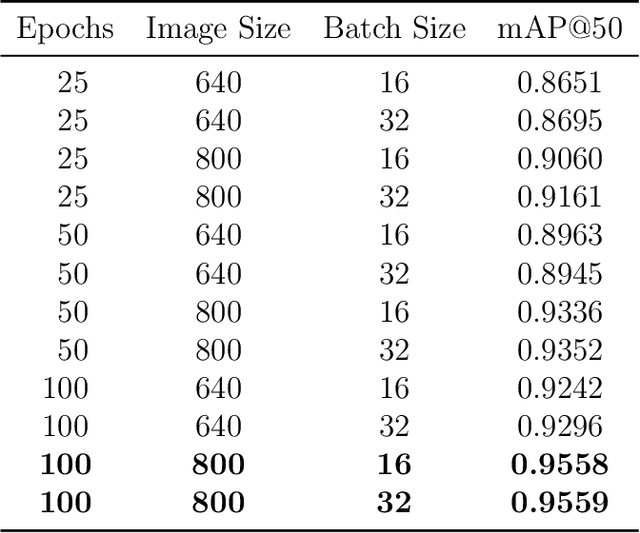

Unmanned Ground Vehicles (UGVs) are emerging as a crucial tool in the world of precision agriculture. The combination of UGVs with machine learning allows us to find solutions for a range of complex agricultural problems. This research focuses on developing a UGV capable of autonomously traversing agricultural fields and capturing data. The project, known as AGRO (Autonomous Ground Rover Observer) leverages machine learning, computer vision and other sensor technologies. AGRO uses its capabilities to determine pistachio yields, performing self-localization and real-time environmental mapping while avoiding obstacles. The main objective of this research work is to automate resource-consuming operations so that AGRO can support farmers in making data-driven decisions. Furthermore, AGRO provides a foundation for advanced machine learning techniques as it captures the world around it.
Detecting AI-generated Artwork
Apr 09, 2025The high efficiency and quality of artwork generated by Artificial Intelligence (AI) has created new concerns and challenges for human artists. In particular, recent improvements in generative AI have made it difficult for people to distinguish between human-generated and AI-generated art. In this research, we consider the potential utility of various types of Machine Learning (ML) and Deep Learning (DL) models in distinguishing AI-generated artwork from human-generated artwork. We focus on three challenging artistic styles, namely, baroque, cubism, and expressionism. The learning models we test are Logistic Regression (LR), Support Vector Machine (SVM), Multilayer Perceptron (MLP), and Convolutional Neural Network (CNN). Our best experimental results yield a multiclass accuracy of 0.8208 over six classes, and an impressive accuracy of 0.9758 for the binary classification problem of distinguishing AI-generated from human-generated art.
Cluster Analysis and Concept Drift Detection in Malware
Feb 19, 2025
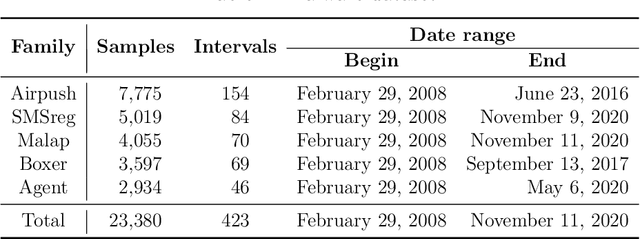
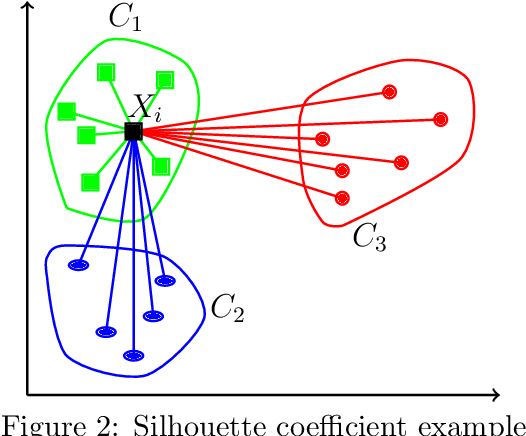
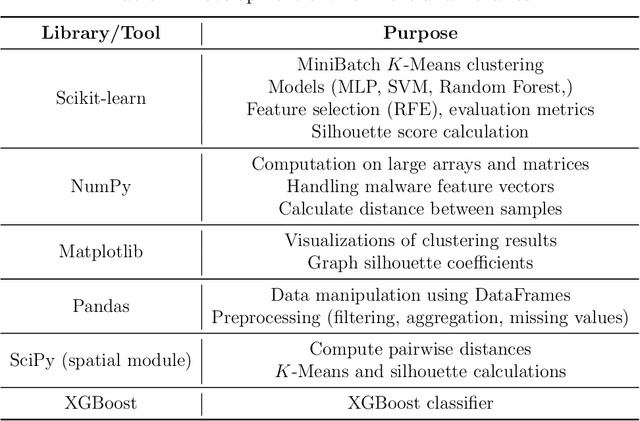
Concept drift refers to gradual or sudden changes in the properties of data that affect the accuracy of machine learning models. In this paper, we address the problem of concept drift detection in the malware domain. Specifically, we propose and analyze a clustering-based approach to detecting concept drift. Using a subset of the KronoDroid dataset, malware samples are partitioned into temporal batches and analyzed using MiniBatch $K$-Means clustering. The silhouette coefficient is used as a metric to identify points in time where concept drift has likely occurred. To verify our drift detection results, we train learning models under three realistic scenarios, which we refer to as static training, periodic retraining, and drift-aware retraining. In each scenario, we consider four supervised classifiers, namely, Multilayer Perceptron (MLP), Support Vector Machine (SVM), Random Forest, and XGBoost. Experimental results demonstrate that drift-aware retraining guided by silhouette coefficient thresholding achieves classification accuracy far superior to static models, and generally within 1% of periodic retraining, while also being far more efficient than periodic retraining. These results provide strong evidence that our clustering-based approach is effective at detecting concept drift, while also illustrating a highly practical and efficient fully automated approach to improved malware classification via concept drift detection.
Multimodal Techniques for Malware Classification
Jan 19, 2025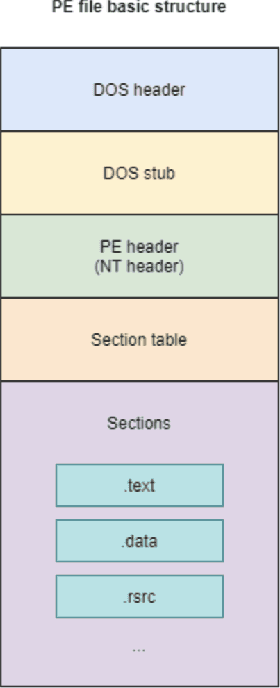
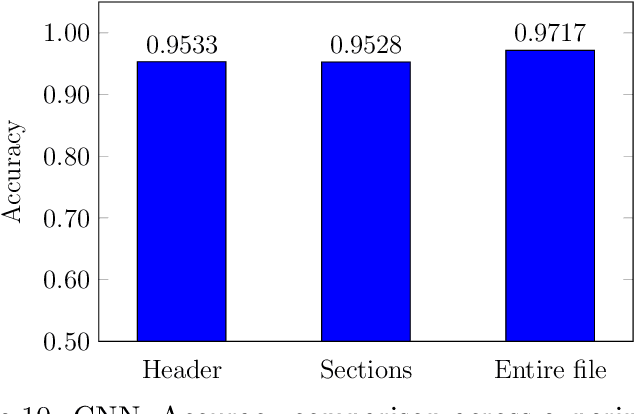
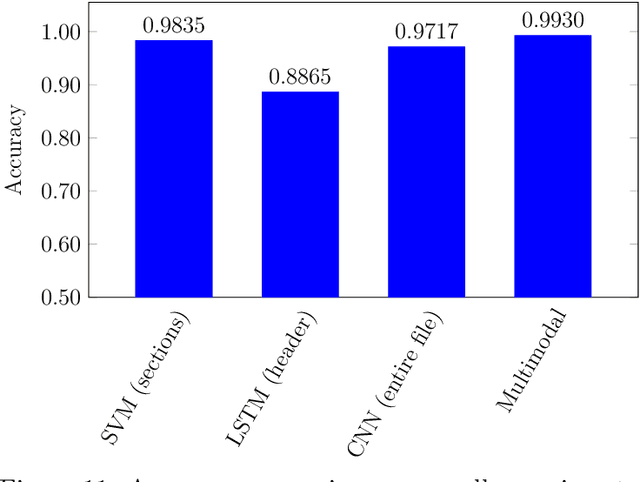
The threat of malware is a serious concern for computer networks and systems, highlighting the need for accurate classification techniques. In this research, we experiment with multimodal machine learning approaches for malware classification, based on the structured nature of the Windows Portable Executable (PE) file format. Specifically, we train Support Vector Machine (SVM), Long Short-Term Memory (LSTM), and Convolutional Neural Network (CNN) models on features extracted from PE headers, we train these same models on features extracted from the other sections of PE files, and train each model on features extracted from the entire PE file. We then train SVM models on each of the nine header-sections combinations of these baseline models, using the output layer probabilities of the component models as feature vectors. We compare the baseline cases to these multimodal combinations. In our experiments, we find that the best of the multimodal models outperforms the best of the baseline cases, indicating that it can be advantageous to train separate models on distinct parts of Windows PE files.
Temporal Analysis of Adversarial Attacks in Federated Learning
Jan 19, 2025



In this paper, we experimentally analyze the robustness of selected Federated Learning (FL) systems in the presence of adversarial clients. We find that temporal attacks significantly affect model performance in the FL models tested, especially when the adversaries are active throughout or during the later rounds. We consider a variety of classic learning models, including Multinominal Logistic Regression (MLR), Random Forest, XGBoost, Support Vector Classifier (SVC), as well as various Neural Network models including Multilayer Perceptron (MLP), Convolution Neural Network (CNN), Recurrent Neural Network (RNN), and Long Short-Term Memory (LSTM). Our results highlight the effectiveness of temporal attacks and the need to develop strategies to make the FL process more robust against such attacks. We also briefly consider the effectiveness of defense mechanisms, including outlier detection in the aggregation algorithm.
Malware Classification using a Hybrid Hidden Markov Model-Convolutional Neural Network
Dec 25, 2024



The proliferation of malware variants poses a significant challenges to traditional malware detection approaches, such as signature-based methods, necessitating the development of advanced machine learning techniques. In this research, we present a novel approach based on a hybrid architecture combining features extracted using a Hidden Markov Model (HMM), with a Convolutional Neural Network (CNN) then used for malware classification. Inspired by the strong results in previous work using an HMM-Random Forest model, we propose integrating HMMs, which serve to capture sequential patterns in opcode sequences, with CNNs, which are adept at extracting hierarchical features. We demonstrate the effectiveness of our approach on the popular Malicia dataset, and we obtain superior performance, as compared to other machine learning methods -- our results surpass the aforementioned HMM-Random Forest model. Our findings underscore the potential of hybrid HMM-CNN architectures in bolstering malware classification capabilities, offering several promising avenues for further research in the field of cybersecurity.
An Empirical Analysis of Federated Learning Models Subject to Label-Flipping Adversarial Attack
Dec 24, 2024
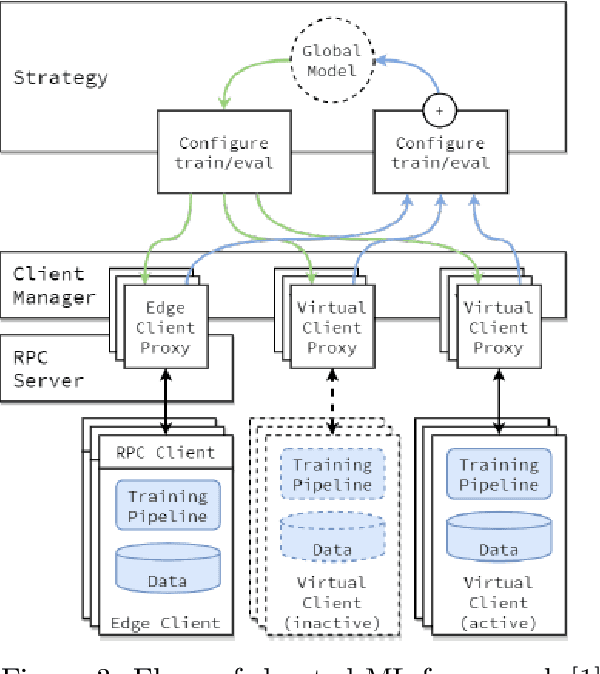
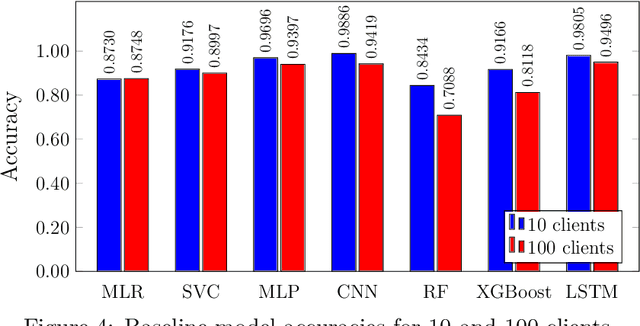
In this paper, we empirically analyze adversarial attacks on selected federated learning models. The specific learning models considered are Multinominal Logistic Regression (MLR), Support Vector Classifier (SVC), Multilayer Perceptron (MLP), Convolution Neural Network (CNN), %Recurrent Neural Network (RNN), Random Forest, XGBoost, and Long Short-Term Memory (LSTM). For each model, we simulate label-flipping attacks, experimenting extensively with 10 federated clients and 100 federated clients. We vary the percentage of adversarial clients from 10% to 100% and, simultaneously, the percentage of labels flipped by each adversarial client is also varied from 10% to 100%. Among other results, we find that models differ in their inherent robustness to the two vectors in our label-flipping attack, i.e., the percentage of adversarial clients, and the percentage of labels flipped by each adversarial client. We discuss the potential practical implications of our results.
Image-Based Malware Classification Using QR and Aztec Codes
Dec 11, 2024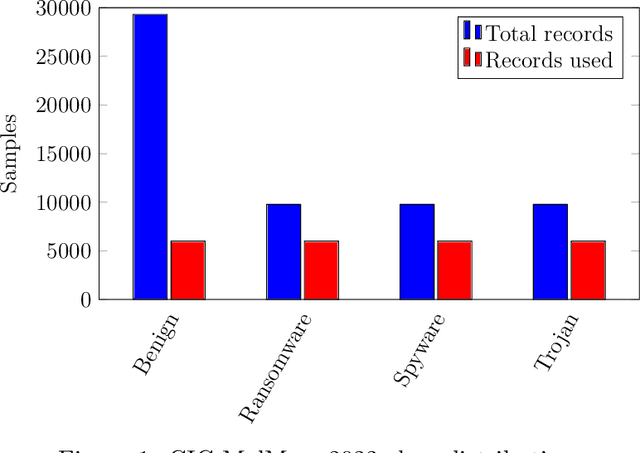

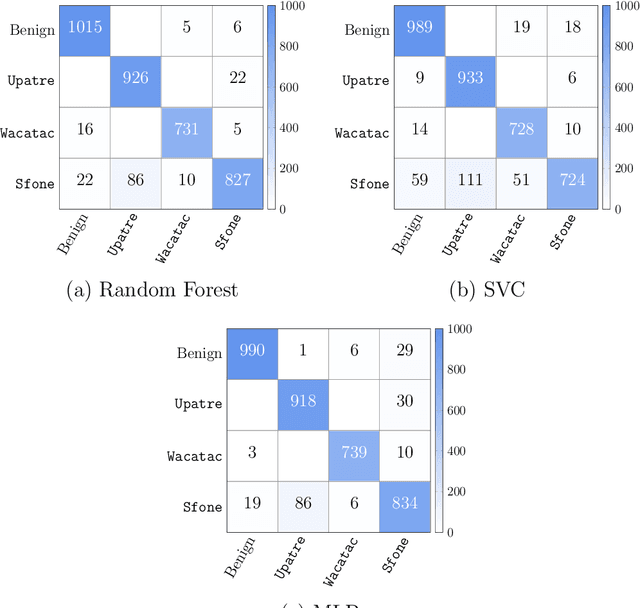

In recent years, the use of image-based techniques for malware detection has gained prominence, with numerous studies demonstrating the efficacy of deep learning approaches such as Convolutional Neural Networks (CNN) in classifying images derived from executable files. In this paper, we consider an innovative method that relies on an image conversion process that consists of transforming features extracted from executable files into QR and Aztec codes. These codes capture structural patterns in a format that may enhance the learning capabilities of CNNs. We design and implement CNN architectures tailored to the unique properties of these codes and apply them to a comprehensive analysis involving two extensive malware datasets, both of which include a significant corpus of benign samples. Our results yield a split decision, with CNNs trained on QR and Aztec codes outperforming the state of the art on one of the datasets, but underperforming more typical techniques on the other dataset. These results indicate that the use of QR and Aztec codes as a form of feature engineering holds considerable promise in the malware domain, and that additional research is needed to better understand the relative strengths and weaknesses of such an approach.
XAI and Android Malware Models
Nov 25, 2024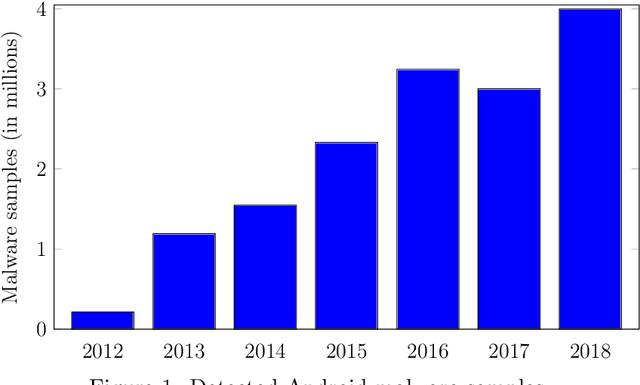
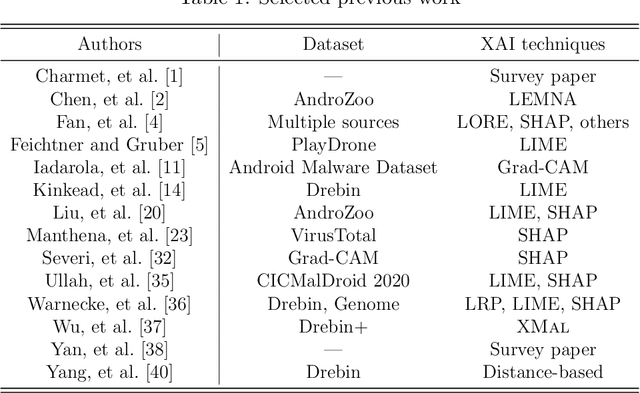
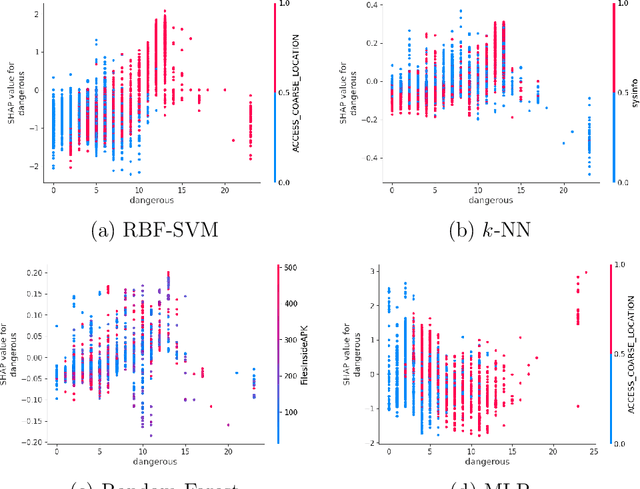
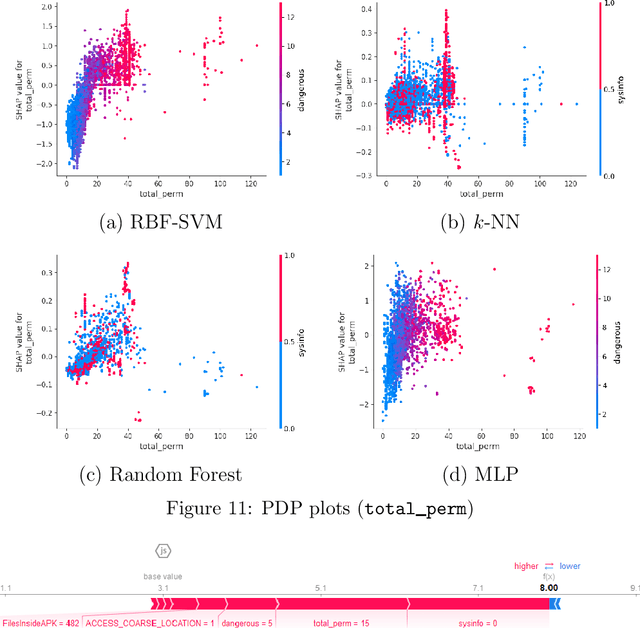
Android malware detection based on machine learning (ML) and deep learning (DL) models is widely used for mobile device security. Such models offer benefits in terms of detection accuracy and efficiency, but it is often difficult to understand how such learning models make decisions. As a result, these popular malware detection strategies are generally treated as black boxes, which can result in a lack of trust in the decisions made, as well as making adversarial attacks more difficult to detect. The field of eXplainable Artificial Intelligence (XAI) attempts to shed light on such black box models. In this paper, we apply XAI techniques to ML and DL models that have been trained on a challenging Android malware classification problem. Specifically, the classic ML models considered are Support Vector Machines (SVM), Random Forest, and $k$-Nearest Neighbors ($k$-NN), while the DL models we consider are Multi-Layer Perceptrons (MLP) and Convolutional Neural Networks (CNN). The state-of-the-art XAI techniques that we apply to these trained models are Local Interpretable Model-agnostic Explanations (LIME), Shapley Additive exPlanations (SHAP), PDP plots, ELI5, and Class Activation Mapping (CAM). We obtain global and local explanation results, and we discuss the utility of XAI techniques in this problem domain. We also provide a literature review of XAI work related to Android malware.