 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Analysis of Federated Learning Models Subject to Label-Flipping Adversarial Attack
Dec 24, 2024
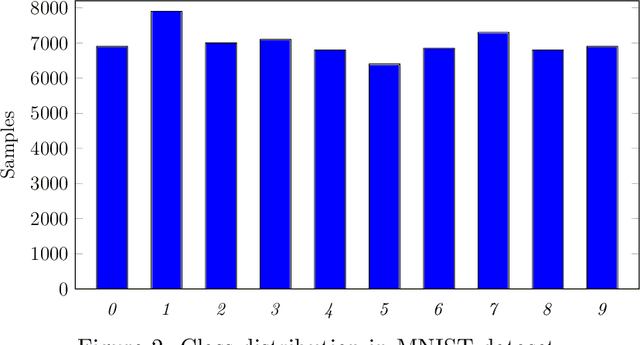
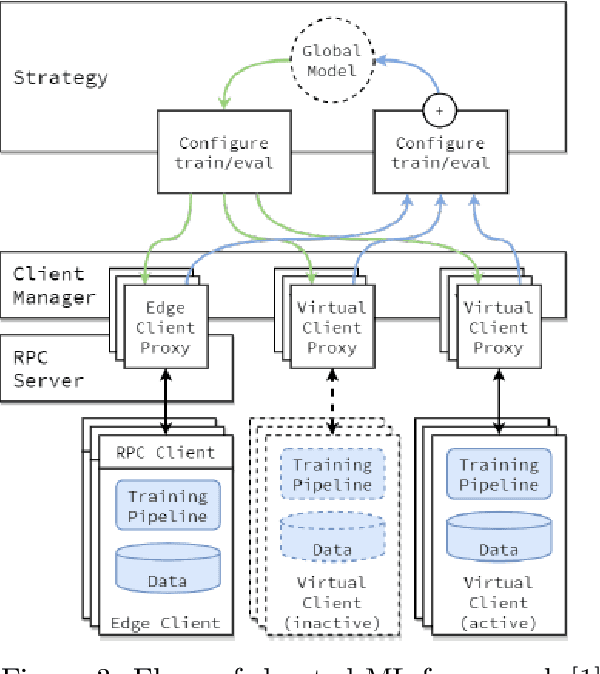
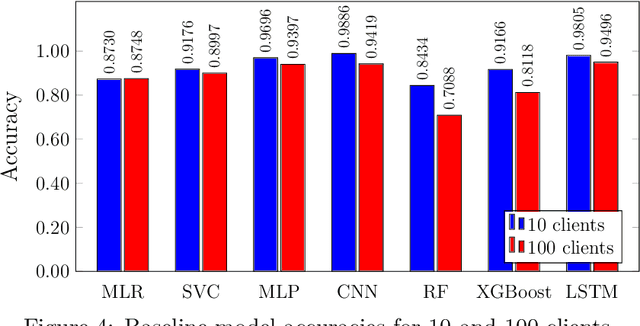
In this paper, we empirically analyze adversarial attacks on selected federated learning models. The specific learning models considered are Multinominal Logistic Regression (MLR), Support Vector Classifier (SVC), Multilayer Perceptron (MLP), Convolution Neural Network (CNN), %Recurrent Neural Network (RNN), Random Forest, XGBoost, and Long Short-Term Memory (LSTM). For each model, we simulate label-flipping attacks, experimenting extensively with 10 federated clients and 100 federated clients. We vary the percentage of adversarial clients from 10% to 100% and, simultaneously, the percentage of labels flipped by each adversarial client is also varied from 10% to 100%. Among other results, we find that models differ in their inherent robustness to the two vectors in our label-flipping attack, i.e., the percentage of adversarial clients, and the percentage of labels flipped by each adversarial client. We discuss the potential practical implications of our results.
On the Steganographic Capacity of Selected Learning Models
Aug 29, 2023Machine learning and deep learning models are potential vectors for various attack scenarios. For example, previous research has shown that malware can be hidden in deep learning models. Hiding information in a learning model can be viewed as a form of steganography. In this research, we consider the general question of the steganographic capacity of learning models. Specifically, for a wide range of models, we determine the number of low-order bits of the trained parameters that can be overwritten, without adversely affecting model performance. For each model considered, we graph the accuracy as a function of the number of low-order bits that have been overwritten, and for selected models, we also analyze the steganographic capacity of individual layers. The models that we test include the classic machine learning techniques of Linear Regression (LR) and Support Vector Machine (SVM); the popular general deep learning models of Multilayer Perceptron (MLP) and Convolutional Neural Network (CNN); the highly-successful Recurrent Neural Network (RNN) architecture of Long Short-Term Memory (LSTM); the pre-trained transfer learning-based models VGG16, DenseNet121, InceptionV3, and Xception; and, finally, an Auxiliary Classifier Generative Adversarial Network (ACGAN). In all cases, we find that a majority of the bits of each trained parameter can be overwritten before the accuracy degrades. Of the models tested, the steganographic capacity ranges from 7.04 KB for our LR experiments, to 44.74 MB for InceptionV3. We discuss the implications of our results and consider possible avenues for further research.