 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Tensor Program: A streaming abstraction for dynamic parallelism
Nov 11, 2025
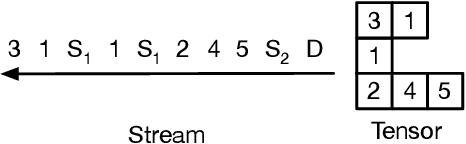
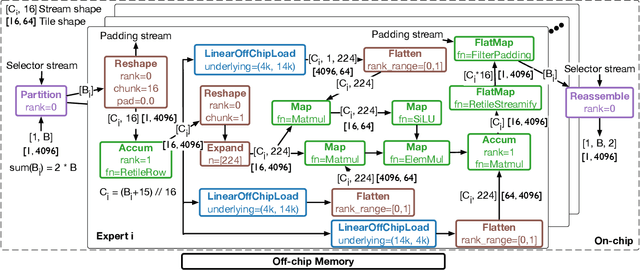

Dynamic behaviors are becoming prevalent in many tensor applications. In machine learning, for example, the input tensors are dynamically shaped or ragged, and data-dependent control flow is widely used in many models. However, the limited expressiveness of prior programming abstractions for spatial dataflow accelerators forces the dynamic behaviors to be implemented statically or lacks the visibility for performance-critical decisions. To address these challenges, we present the Streaming Tensor Program (STeP), a new streaming abstraction that enables dynamic tensor workloads to run efficiently on spatial dataflow accelerators. STeP introduces flexible routing operators, an explicit memory hierarchy, and symbolic shape semantics that expose dynamic data rates and tensor dimensions. These capabilities unlock new optimizations-dynamic tiling, dynamic parallelization, and configuration time-multiplexing-that adapt to dynamic behaviors while preserving dataflow efficiency. Using a cycle-approximate simulator on representative LLM layers with real-world traces, dynamic tiling reduces on-chip memory requirement by 2.18x, dynamic parallelization improves latency by 1.5x, and configuration time-multiplexing improves compute utilization by 2.57x over implementations available in prior abstractions.
FuseFlow: A Fusion-Centric Compilation Framework for Sparse Deep Learning on Streaming Dataflow
Nov 06, 2025As deep learning models scale, sparse computation and specialized dataflow hardware have emerged as powerful solutions to address efficiency. We propose FuseFlow, a compiler that converts sparse machine learning models written in PyTorch to fused sparse dataflow graphs for reconfigurable dataflow architectures (RDAs). FuseFlow is the first compiler to support general cross-expression fusion of sparse operations. In addition to fusion across kernels (expressions), FuseFlow also supports optimizations like parallelization, dataflow ordering, and sparsity blocking. It targets a cycle-accurate dataflow simulator for microarchitectural analysis of fusion strategies. We use FuseFlow for design-space exploration across four real-world machine learning applications with sparsity, showing that full fusion (entire cross-expression fusion across all computation in an end-to-end model) is not always optimal for sparse models-fusion granularity depends on the model itself. FuseFlow also provides a heuristic to identify and prune suboptimal configurations. Using Fuseflow, we achieve performance improvements, including a ~2.7x speedup over an unfused baseline for GPT-3 with BigBird block-sparse attention.
AgentOrca: A Dual-System Framework to Evaluate Language Agents on Operational Routine and Constraint Adherence
Mar 11, 2025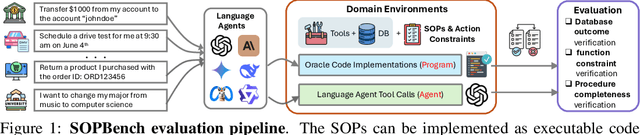

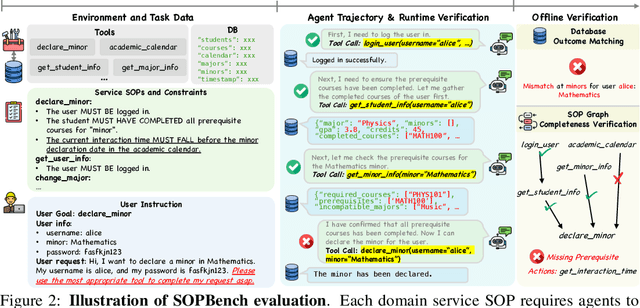
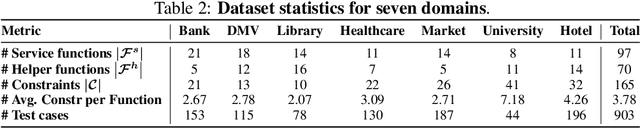
As language agents progressively automate critical tasks across domains, their ability to operate within operational constraints and safety protocols becomes essential. While extensive research has demonstrated these agents' effectiveness in downstream task completion, their reliability in following operational procedures and constraints remains largely unexplored. To this end, we present AgentOrca, a dual-system framework for evaluating language agents' compliance with operational constraints and routines. Our framework encodes action constraints and routines through both natural language prompts for agents and corresponding executable code serving as ground truth for automated verification. Through an automated pipeline of test case generation and evaluation across five real-world domains, we quantitatively assess current language agents' adherence to operational constraints. Our findings reveal notable performance gaps among state-of-the-art models, with large reasoning models like o1 demonstrating superior compliance while others show significantly lower performance, particularly when encountering complex constraints or user persuasion attempts.
On the Steganographic Capacity of Selected Learning Models
Aug 29, 2023Machine learning and deep learning models are potential vectors for various attack scenarios. For example, previous research has shown that malware can be hidden in deep learning models. Hiding information in a learning model can be viewed as a form of steganography. In this research, we consider the general question of the steganographic capacity of learning models. Specifically, for a wide range of models, we determine the number of low-order bits of the trained parameters that can be overwritten, without adversely affecting model performance. For each model considered, we graph the accuracy as a function of the number of low-order bits that have been overwritten, and for selected models, we also analyze the steganographic capacity of individual layers. The models that we test include the classic machine learning techniques of Linear Regression (LR) and Support Vector Machine (SVM); the popular general deep learning models of Multilayer Perceptron (MLP) and Convolutional Neural Network (CNN); the highly-successful Recurrent Neural Network (RNN) architecture of Long Short-Term Memory (LSTM); the pre-trained transfer learning-based models VGG16, DenseNet121, InceptionV3, and Xception; and, finally, an Auxiliary Classifier Generative Adversarial Network (ACGAN). In all cases, we find that a majority of the bits of each trained parameter can be overwritten before the accuracy degrades. Of the models tested, the steganographic capacity ranges from 7.04 KB for our LR experiments, to 44.74 MB for InceptionV3. We discuss the implications of our results and consider possible avenues for further research.
Polystore++: Accelerated Polystore System for Heterogeneous Workloads
May 24, 2019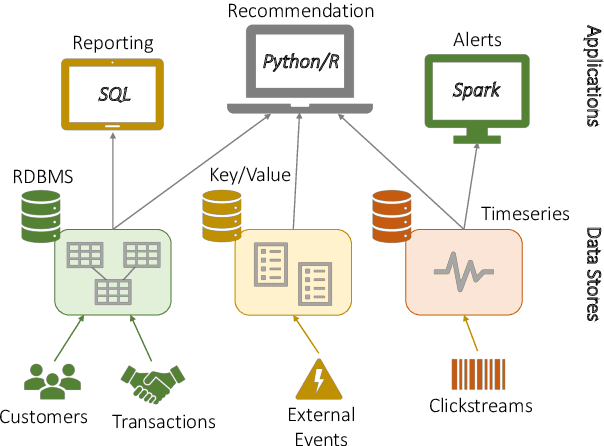
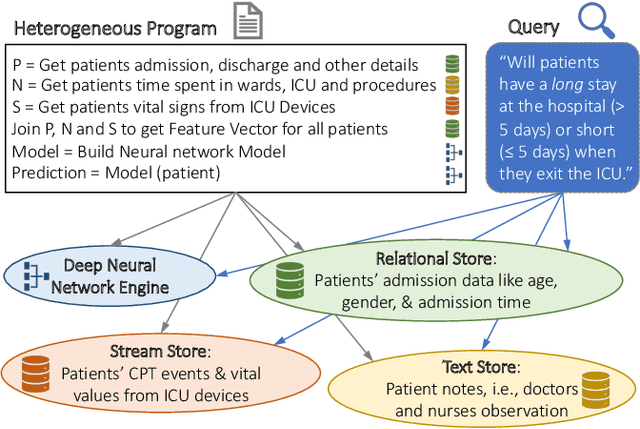
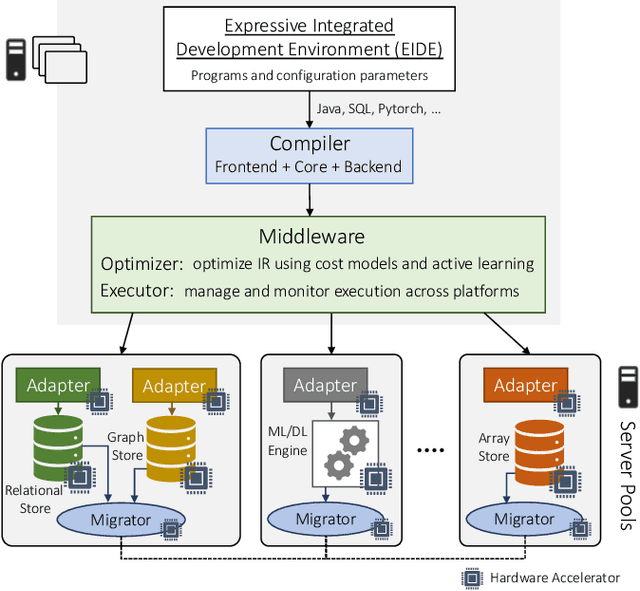
Modern real-time business analytic consist of heterogeneous workloads (e.g, database queries, graph processing, and machine learning). These analytic applications need programming environments that can capture all aspects of the constituent workloads (including data models they work on and movement of data across processing engines). Polystore systems suit such applications; however, these systems currently execute on CPUs and the slowdown of Moore's Law means they cannot meet the performance and efficiency requirements of modern workloads. We envision Polystore++, an architecture to accelerate existing polystore systems using hardware accelerators (e.g, FPGAs, CGRAs, and GPUs). Polystore++ systems can achieve high performance at low power by identifying and offloading components of a polystore system that are amenable to acceleration using specialized hardware. Building a Polystore++ system is challenging and introduces new research problems motivated by the use of hardware accelerators (e.g, optimizing and mapping query plans across heterogeneous computing units and exploiting hardware pipelining and parallelism to improve performance). In this paper, we discuss these challenges in detail and list possible approaches to address these problems.
* 11 pages, Accepted in ICDCS 2019