 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDINOSTAR: Deep Iterative Neural Object Detector Self-Supervised Training for Roadside LiDAR Applications
Jan 28, 2025



Recent advancements in deep-learning methods for object detection in point-cloud data have enabled numerous roadside applications, fostering improvements in transportation safety and management. However, the intricate nature of point-cloud data poses significant challenges for human-supervised labeling, resulting in substantial expenditures of time and capital. This paper addresses the issue by developing an end-to-end, scalable, and self-supervised framework for training deep object detectors tailored for roadside point-cloud data. The proposed framework leverages self-supervised, statistically modeled teachers to train off-the-shelf deep object detectors, thus circumventing the need for human supervision. The teacher models follow fine-tuned set standard practices of background filtering, object clustering, bounding-box fitting, and classification to generate noisy labels. It is presented that by training the student model over the combined noisy annotations from multitude of teachers enhances its capacity to discern background/foreground more effectively and forces it to learn diverse point-cloud-representations for object categories of interest. The evaluations, involving publicly available roadside datasets and state-of-art deep object detectors, demonstrate that the proposed framework achieves comparable performance to deep object detectors trained on human-annotated labels, despite not utilizing such human-annotations in its training process.
Taurus: An Intelligent Data Plane
Feb 12, 2020
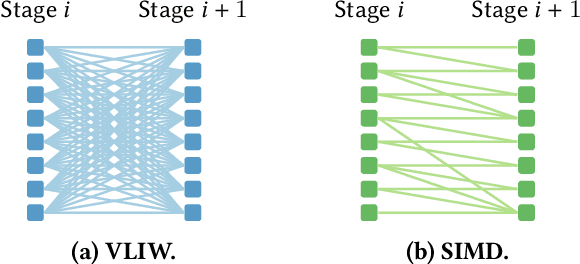
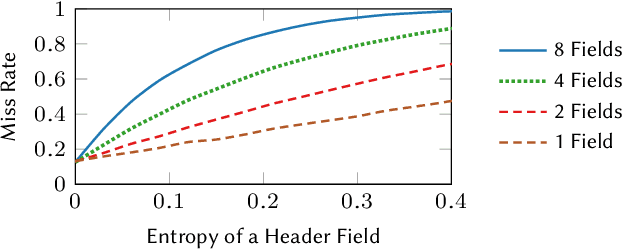
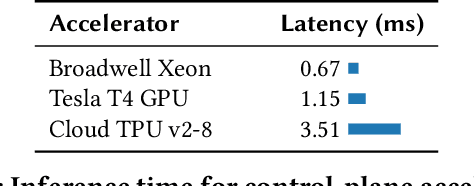
Emerging applications -- cloud computing, the internet of things, and augmented/virtual reality -- need responsive, available, secure, ubiquitous, and scalable datacenter networks. Network management currently uses simple, per-packet, data-plane heuristics (e.g., ECMP and sketches) under an intelligent, millisecond-latency control plane that runs data-driven performance and security policies. However, to meet users' quality-of-service expectations in a modern data center, networks must operate intelligently at line rate. In this paper, we present Taurus, an intelligent data plane capable of machine-learning inference at line rate. Taurus adds custom hardware based on a map-reduce abstraction to programmable network devices, such as switches and NICs; this new hardware uses pipelined and SIMD parallelism for fast inference. Our evaluation of a Taurus-enabled switch ASIC -- supporting several real-world benchmarks -- shows that Taurus operates three orders of magnitude faster than a server-based control plane, while increasing area by 24% and latency, on average, by 178 ns. On the long road to self-driving networks, Taurus is the equivalent of adaptive cruise control: deterministic rules steer flows, while machine learning tunes performance and heightens security.
Polystore++: Accelerated Polystore System for Heterogeneous Workloads
May 24, 2019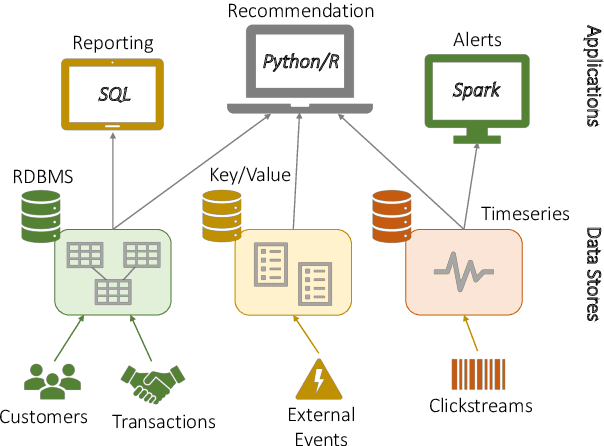
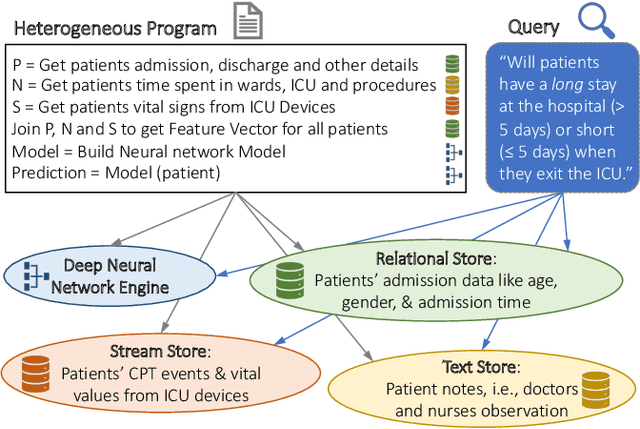
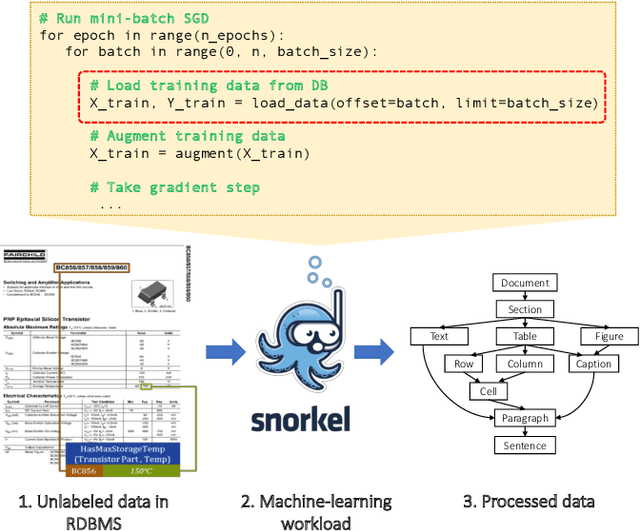
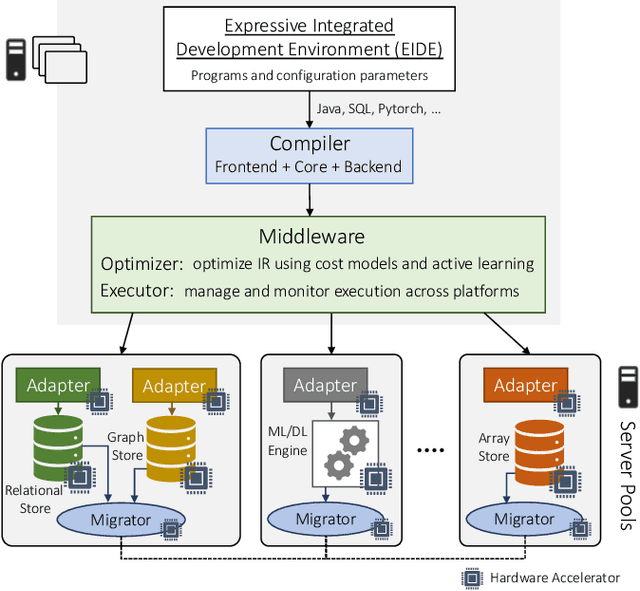
Modern real-time business analytic consist of heterogeneous workloads (e.g, database queries, graph processing, and machine learning). These analytic applications need programming environments that can capture all aspects of the constituent workloads (including data models they work on and movement of data across processing engines). Polystore systems suit such applications; however, these systems currently execute on CPUs and the slowdown of Moore's Law means they cannot meet the performance and efficiency requirements of modern workloads. We envision Polystore++, an architecture to accelerate existing polystore systems using hardware accelerators (e.g, FPGAs, CGRAs, and GPUs). Polystore++ systems can achieve high performance at low power by identifying and offloading components of a polystore system that are amenable to acceleration using specialized hardware. Building a Polystore++ system is challenging and introduces new research problems motivated by the use of hardware accelerators (e.g, optimizing and mapping query plans across heterogeneous computing units and exploiting hardware pipelining and parallelism to improve performance). In this paper, we discuss these challenges in detail and list possible approaches to address these problems.
* 11 pages, Accepted in ICDCS 2019