 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombee: Scaling Prompt Learning for Self-Improving Language Model Agents
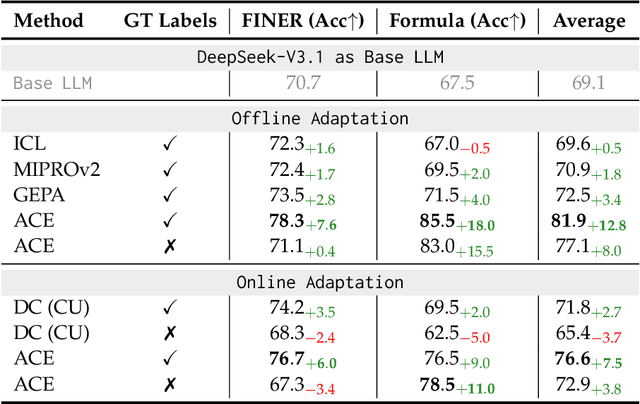
Apr 05, 2026Recent advances in prompt learning allow large language model agents to acquire task-relevant knowledge from inference-time context without parameter changes. For example, existing methods (like ACE or GEPA) can learn system prompts to improve accuracy based on previous agent runs. However, these methods primarily focus on single-agent or low-parallelism settings. This fundamentally limits their ability to efficiently learn from a large set of collected agentic traces. It would be efficient and beneficial to run prompt learning in parallel to accommodate the growing trend of learning from many agentic traces or parallel agent executions. Yet without a principled strategy for scaling, current methods suffer from quality degradation with high parallelism. To improve both the efficiency and quality of prompt learning, we propose Combee, a novel framework to scale parallel prompt learning for self-improving agents. Combee speeds up learning and enables running many agents in parallel while learning from their aggregate traces without quality degradation. To achieve this, Combee leverages parallel scans and employs an augmented shuffle mechanism; Combee also introduces a dynamic batch size controller to balance quality and delay. Evaluations on AppWorld, Terminal-Bench, Formula, and FiNER demonstrate that Combee achieves up to 17x speedup over previous methods with comparable or better accuracy and equivalent cost.
AI+HW 2035: Shaping the Next Decade
Mar 05, 2026Artificial intelligence (AI) and hardware (HW) are advancing at unprecedented rates, yet their trajectories have become inseparably intertwined. The global research community lacks a cohesive, long-term vision to strategically coordinate the development of AI and HW. This fragmentation constrains progress toward holistic, sustainable, and adaptive AI systems capable of learning, reasoning, and operating efficiently across cloud, edge, and physical environments. The future of AI depends not only on scaling intelligence, but on scaling efficiency, achieving exponential gains in intelligence per joule, rather than unbounded compute consumption. Addressing this grand challenge requires rethinking the entire computing stack. This vision paper lays out a 10-year roadmap for AI+HW co-design and co-development, spanning algorithms, architectures, systems, and sustainability. We articulate key insights that redefine scaling around energy efficiency, system-level integration, and cross-layer optimization. We identify key challenges and opportunities, candidly assess potential obstacles and pitfalls, and propose integrated solutions grounded in algorithmic innovation, hardware advances, and software abstraction. Looking ahead, we define what success means in 10 years: achieving a 1000x improvement in efficiency for AI training and inference; enabling energy-aware, self-optimizing systems that seamlessly span cloud, edge, and physical AI; democratizing access to advanced AI infrastructure; and embedding human-centric principles into the design of intelligent systems. Finally, we outline concrete action items for academia, industry, government, and the broader community, calling for coordinated national initiatives, shared infrastructure, workforce development, cross-agency collaboration, and sustained public-private partnerships to ensure that AI+HW co-design becomes a unifying long-term mission.
Streaming Tensor Program: A streaming abstraction for dynamic parallelism
Nov 11, 2025
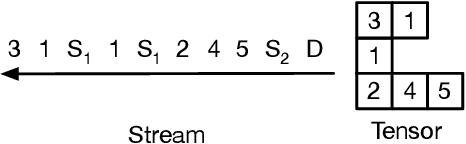
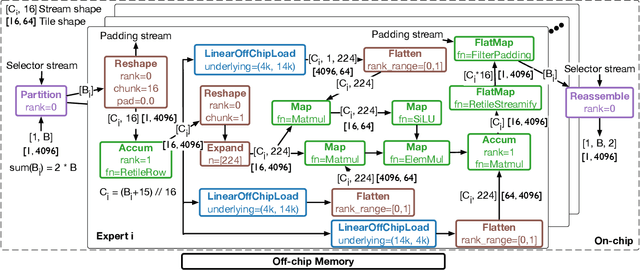

Dynamic behaviors are becoming prevalent in many tensor applications. In machine learning, for example, the input tensors are dynamically shaped or ragged, and data-dependent control flow is widely used in many models. However, the limited expressiveness of prior programming abstractions for spatial dataflow accelerators forces the dynamic behaviors to be implemented statically or lacks the visibility for performance-critical decisions. To address these challenges, we present the Streaming Tensor Program (STeP), a new streaming abstraction that enables dynamic tensor workloads to run efficiently on spatial dataflow accelerators. STeP introduces flexible routing operators, an explicit memory hierarchy, and symbolic shape semantics that expose dynamic data rates and tensor dimensions. These capabilities unlock new optimizations-dynamic tiling, dynamic parallelization, and configuration time-multiplexing-that adapt to dynamic behaviors while preserving dataflow efficiency. Using a cycle-approximate simulator on representative LLM layers with real-world traces, dynamic tiling reduces on-chip memory requirement by 2.18x, dynamic parallelization improves latency by 1.5x, and configuration time-multiplexing improves compute utilization by 2.57x over implementations available in prior abstractions.
FuseFlow: A Fusion-Centric Compilation Framework for Sparse Deep Learning on Streaming Dataflow
Nov 06, 2025As deep learning models scale, sparse computation and specialized dataflow hardware have emerged as powerful solutions to address efficiency. We propose FuseFlow, a compiler that converts sparse machine learning models written in PyTorch to fused sparse dataflow graphs for reconfigurable dataflow architectures (RDAs). FuseFlow is the first compiler to support general cross-expression fusion of sparse operations. In addition to fusion across kernels (expressions), FuseFlow also supports optimizations like parallelization, dataflow ordering, and sparsity blocking. It targets a cycle-accurate dataflow simulator for microarchitectural analysis of fusion strategies. We use FuseFlow for design-space exploration across four real-world machine learning applications with sparsity, showing that full fusion (entire cross-expression fusion across all computation in an end-to-end model) is not always optimal for sparse models-fusion granularity depends on the model itself. FuseFlow also provides a heuristic to identify and prune suboptimal configurations. Using Fuseflow, we achieve performance improvements, including a ~2.7x speedup over an unfused baseline for GPT-3 with BigBird block-sparse attention.
Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models
Oct 06, 2025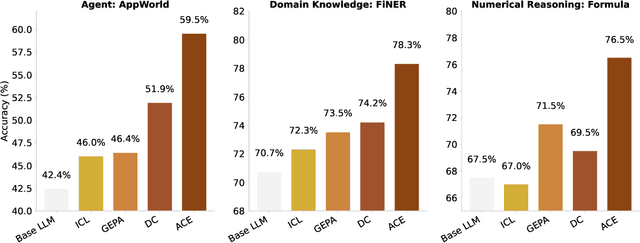
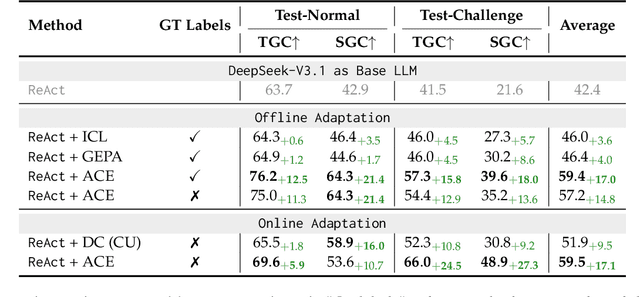
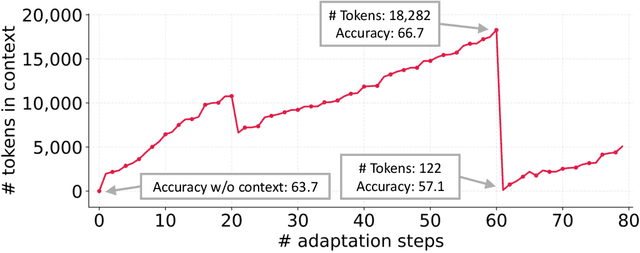
Large language model (LLM) applications such as agents and domain-specific reasoning increasingly rely on context adaptation -- modifying inputs with instructions, strategies, or evidence, rather than weight updates. Prior approaches improve usability but often suffer from brevity bias, which drops domain insights for concise summaries, and from context collapse, where iterative rewriting erodes details over time. Building on the adaptive memory introduced by Dynamic Cheatsheet, we introduce ACE (Agentic Context Engineering), a framework that treats contexts as evolving playbooks that accumulate, refine, and organize strategies through a modular process of generation, reflection, and curation. ACE prevents collapse with structured, incremental updates that preserve detailed knowledge and scale with long-context models. Across agent and domain-specific benchmarks, ACE optimizes contexts both offline (e.g., system prompts) and online (e.g., agent memory), consistently outperforming strong baselines: +10.6% on agents and +8.6% on finance, while significantly reducing adaptation latency and rollout cost. Notably, ACE could adapt effectively without labeled supervision and instead by leveraging natural execution feedback. On the AppWorld leaderboard, ACE matches the top-ranked production-level agent on the overall average and surpasses it on the harder test-challenge split, despite using a smaller open-source model. These results show that comprehensive, evolving contexts enable scalable, efficient, and self-improving LLM systems with low overhead.
Cost-Efficient Serving of LLM Agents via Test-Time Plan Caching
Jun 17, 2025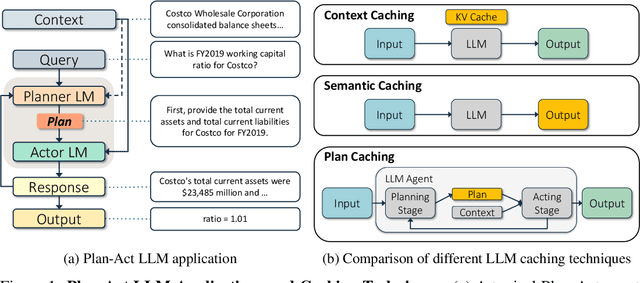

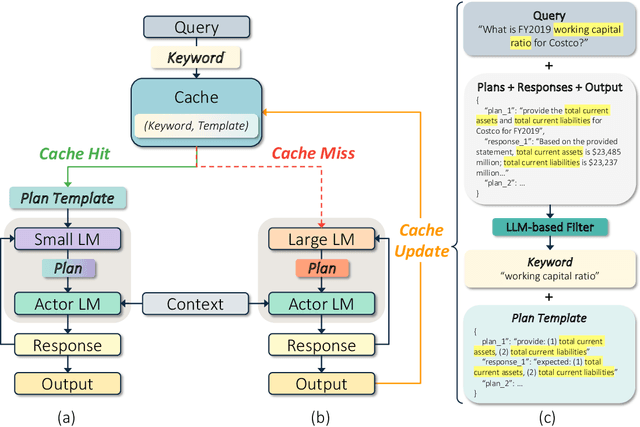
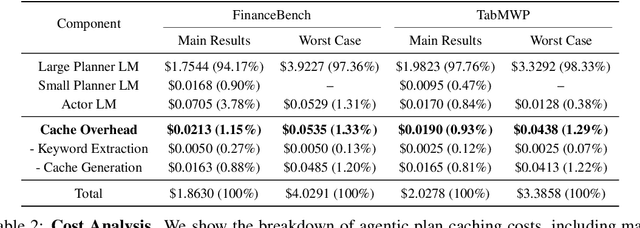
LLM-based agentic applications have shown increasingly remarkable capabilities in complex workflows but incur substantial costs due to extensive planning and reasoning requirements. Existing LLM caching techniques (like context caching and semantic caching), primarily designed for serving chatbots, are insufficient for agentic applications where outputs depend on external data or environmental contexts. We propose agentic plan caching, a novel approach that extracts, stores, adapts, and reuses structured plan templates from planning stages of agentic applications across semantically similar tasks to reduce the cost of serving. Unlike traditional semantic caching, our system extracts plan templates from completed agent executions at test-time, employs keyword extraction to match new requests against cached plans, and utilizes lightweight models to adapt these templates to task-specific plans with contexts. Evaluation across multiple real-world agentic applications shows that our system can reduce costs by 46.62% on average while maintaining performance, offering a more efficient solution for serving LLM-based agents that complements existing LLM serving infrastructures.
LowRA: Accurate and Efficient LoRA Fine-Tuning of LLMs under 2 Bits
Feb 12, 2025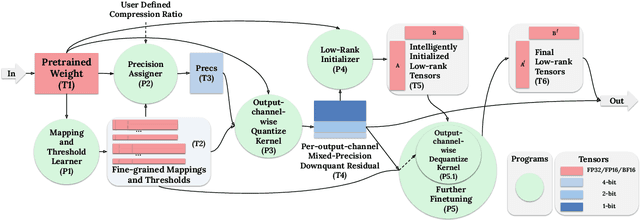

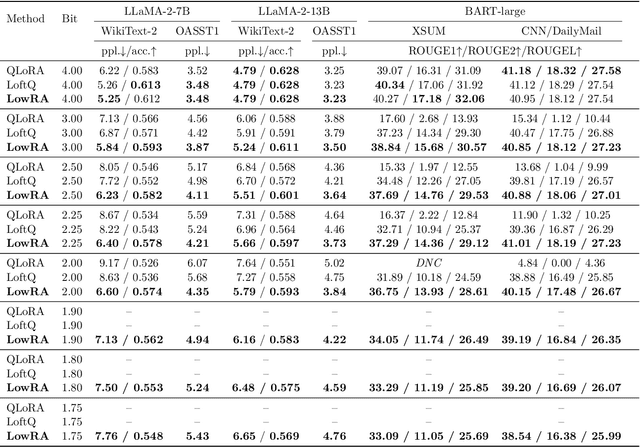
Fine-tuning large language models (LLMs) is increasingly costly as models scale to hundreds of billions of parameters, and even parameter-efficient fine-tuning (PEFT) methods like LoRA remain resource-intensive. We introduce LowRA, the first framework to enable LoRA fine-tuning below 2 bits per parameter with minimal performance loss. LowRA optimizes fine-grained quantization - mapping, threshold selection, and precision assignment - while leveraging efficient CUDA kernels for scalable deployment. Extensive evaluations across 4 LLMs and 4 datasets show that LowRA achieves a superior performance-precision trade-off above 2 bits and remains accurate down to 1.15 bits, reducing memory usage by up to 50%. Our results highlight the potential of ultra-low-bit LoRA fine-tuning for resource-constrained environments.
Adaptive Self-improvement LLM Agentic System for ML Library Development
Feb 04, 2025ML libraries, often written in architecture-specific programming languages (ASPLs) that target domain-specific architectures, are key to efficient ML systems. However, writing these high-performance ML libraries is challenging because it requires expert knowledge of ML algorithms and the ASPL. Large language models (LLMs), on the other hand, have shown general coding capabilities. However, challenges remain when using LLMs for generating ML libraries using ASPLs because 1) this task is complicated even for experienced human programmers and 2) there are limited code examples because of the esoteric and evolving nature of ASPLs. Therefore, LLMs need complex reasoning with limited data in order to complete this task. To address these challenges, we introduce an adaptive self-improvement agentic system. In order to evaluate the effectiveness of our system, we construct a benchmark of a typical ML library and generate ASPL code with both open and closed-source LLMs on this benchmark. Our results show improvements of up to $3.9\times$ over a baseline single LLM.
SambaNova SN40L: Scaling the AI Memory Wall with Dataflow and Composition of Experts
May 13, 2024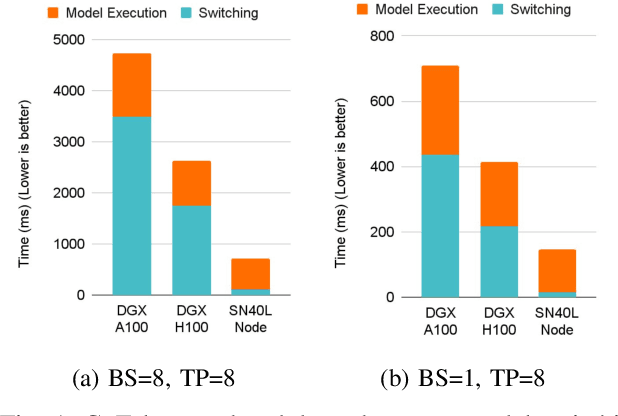
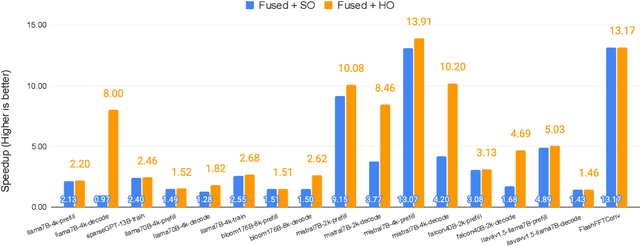
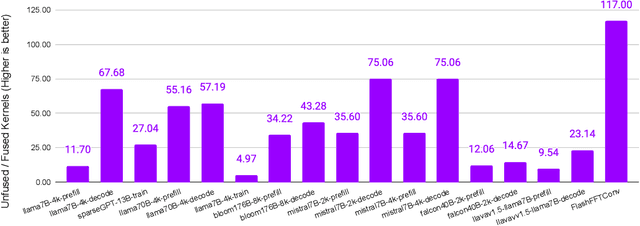
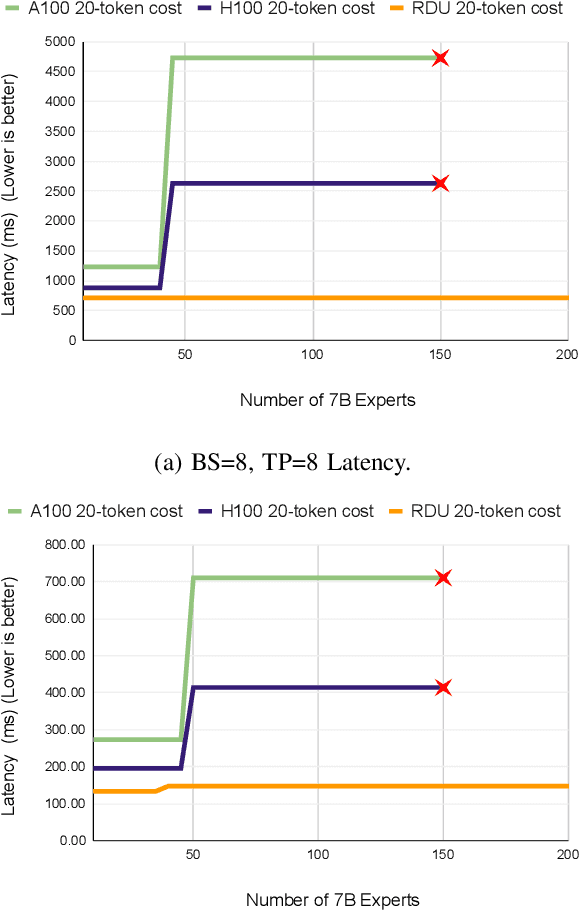
Monolithic large language models (LLMs) like GPT-4 have paved the way for modern generative AI applications. Training, serving, and maintaining monolithic LLMs at scale, however, remains prohibitively expensive and challenging. The disproportionate increase in compute-to-memory ratio of modern AI accelerators have created a memory wall, necessitating new methods to deploy AI. Composition of Experts (CoE) is an alternative modular approach that lowers the cost and complexity of training and serving. However, this approach presents two key challenges when using conventional hardware: (1) without fused operations, smaller models have lower operational intensity, which makes high utilization more challenging to achieve; and (2) hosting a large number of models can be either prohibitively expensive or slow when dynamically switching between them. In this paper, we describe how combining CoE, streaming dataflow, and a three-tier memory system scales the AI memory wall. We describe Samba-CoE, a CoE system with 150 experts and a trillion total parameters. We deploy Samba-CoE on the SambaNova SN40L Reconfigurable Dataflow Unit (RDU) - a commercial dataflow accelerator architecture that has been co-designed for enterprise inference and training applications. The chip introduces a new three-tier memory system with on-chip distributed SRAM, on-package HBM, and off-package DDR DRAM. A dedicated inter-RDU network enables scaling up and out over multiple sockets. We demonstrate speedups ranging from 2x to 13x on various benchmarks running on eight RDU sockets compared with an unfused baseline. We show that for CoE inference deployments, the 8-socket RDU Node reduces machine footprint by up to 19x, speeds up model switching time by 15x to 31x, and achieves an overall speedup of 3.7x over a DGX H100 and 6.6x over a DGX A100.
BaCO: A Fast and Portable Bayesian Compiler Optimization Framework
Dec 01, 2022

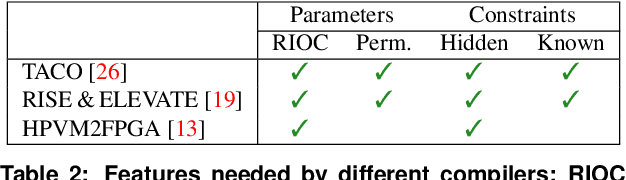
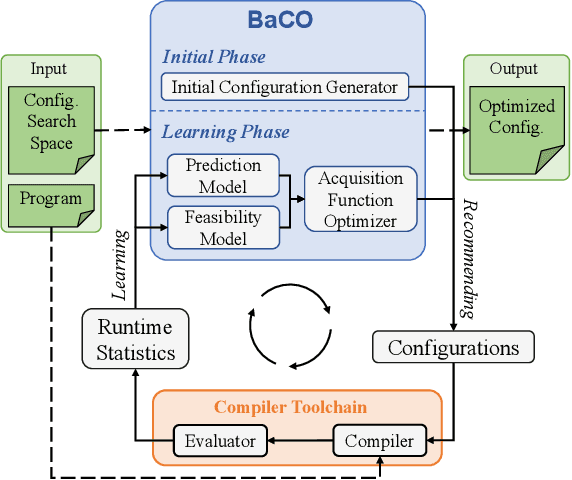
We introduce the Bayesian Compiler Optimization framework (BaCO), a general purpose autotuner for modern compilers targeting CPUs, GPUs, and FPGAs. BaCO provides the flexibility needed to handle the requirements of modern autotuning tasks. Particularly, it deals with permutation, ordered, and continuous parameter types along with both known and unknown parameter constraints. To reason about these parameter types and efficiently deliver high-quality code, BaCO uses Bayesian optimization algorithms specialized towards the autotuning domain. We demonstrate BaCO's effectiveness on three modern compiler systems: TACO, RISE & ELEVATE, and HPVM2FPGA for CPUs, GPUs, and FPGAs respectively. For these domains, BaCO outperforms current state-of-the-art autotuners by delivering on average 1.39x-1.89x faster code with a tiny search budget, and BaCO is able to reach expert-level performance 2.89x-8.77x faster.