 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Evidence Decoupling for Trusted Multi-view Learning
Oct 04, 2024



Multi-view learning methods often focus on improving decision accuracy, while neglecting the decision uncertainty, limiting their suitability for safety-critical applications. To mitigate this, researchers propose trusted multi-view learning methods that estimate classification probabilities and uncertainty by learning the class distributions for each instance. However, these methods assume that the data from each view can effectively differentiate all categories, ignoring the semantic vagueness phenomenon in real-world multi-view data. Our findings demonstrate that this phenomenon significantly suppresses the learning of view-specific evidence in existing methods. We propose a Consistent and Complementary-aware trusted Multi-view Learning (CCML) method to solve this problem. We first construct view opinions using evidential deep neural networks, which consist of belief mass vectors and uncertainty estimates. Next, we dynamically decouple the consistent and complementary evidence. The consistent evidence is derived from the shared portions across all views, while the complementary evidence is obtained by averaging the differing portions across all views. We ensure that the opinion constructed from the consistent evidence strictly aligns with the ground-truth category. For the opinion constructed from the complementary evidence, we allow it for potential vagueness in the evidence. We compare CCML with state-of-the-art baselines on one synthetic and six real-world datasets. The results validate the effectiveness of the dynamic evidence decoupling strategy and show that CCML significantly outperforms baselines on accuracy and reliability. The code is released at https://github.com/Lihong-Liu/CCML.
SambaNova SN40L: Scaling the AI Memory Wall with Dataflow and Composition of Experts
May 13, 2024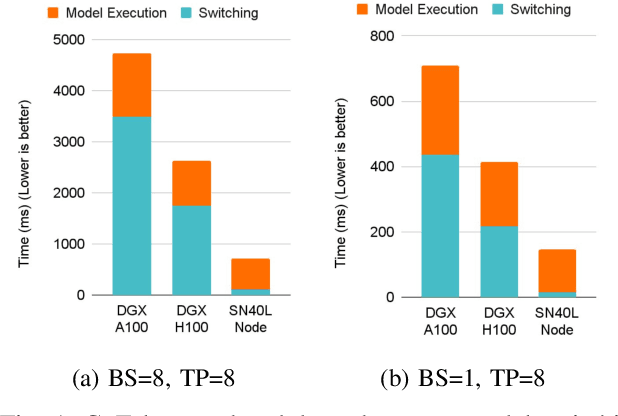
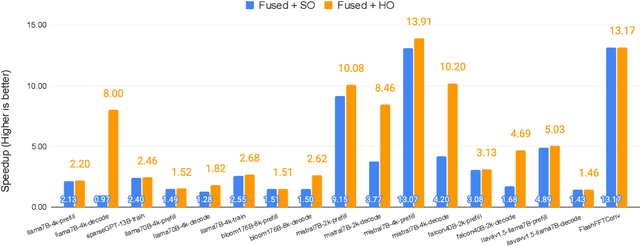
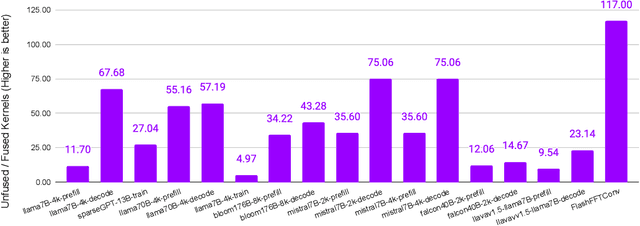
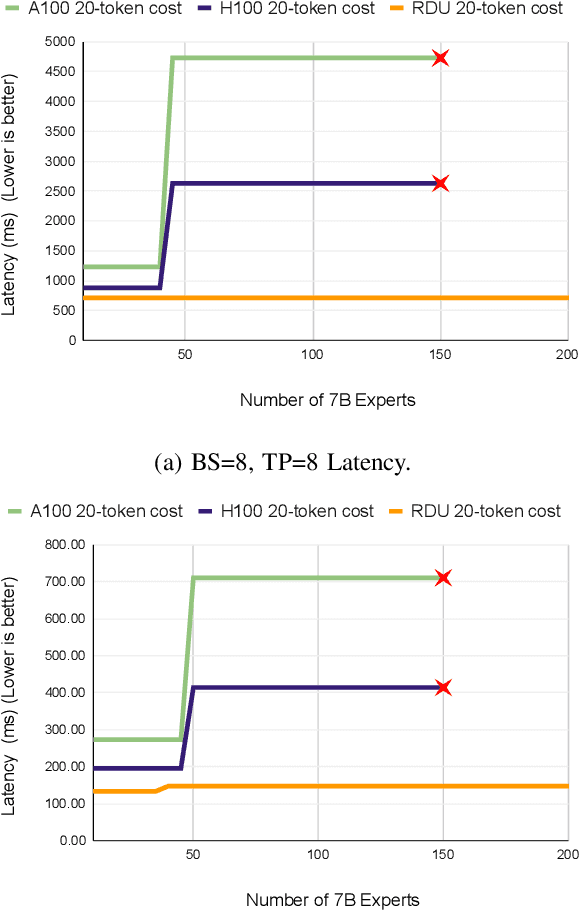
Monolithic large language models (LLMs) like GPT-4 have paved the way for modern generative AI applications. Training, serving, and maintaining monolithic LLMs at scale, however, remains prohibitively expensive and challenging. The disproportionate increase in compute-to-memory ratio of modern AI accelerators have created a memory wall, necessitating new methods to deploy AI. Composition of Experts (CoE) is an alternative modular approach that lowers the cost and complexity of training and serving. However, this approach presents two key challenges when using conventional hardware: (1) without fused operations, smaller models have lower operational intensity, which makes high utilization more challenging to achieve; and (2) hosting a large number of models can be either prohibitively expensive or slow when dynamically switching between them. In this paper, we describe how combining CoE, streaming dataflow, and a three-tier memory system scales the AI memory wall. We describe Samba-CoE, a CoE system with 150 experts and a trillion total parameters. We deploy Samba-CoE on the SambaNova SN40L Reconfigurable Dataflow Unit (RDU) - a commercial dataflow accelerator architecture that has been co-designed for enterprise inference and training applications. The chip introduces a new three-tier memory system with on-chip distributed SRAM, on-package HBM, and off-package DDR DRAM. A dedicated inter-RDU network enables scaling up and out over multiple sockets. We demonstrate speedups ranging from 2x to 13x on various benchmarks running on eight RDU sockets compared with an unfused baseline. We show that for CoE inference deployments, the 8-socket RDU Node reduces machine footprint by up to 19x, speeds up model switching time by 15x to 31x, and achieves an overall speedup of 3.7x over a DGX H100 and 6.6x over a DGX A100.
Simultaneous Multiple Object Detection and Pose Estimation using 3D Model Infusion with Monocular Vision
Nov 22, 2022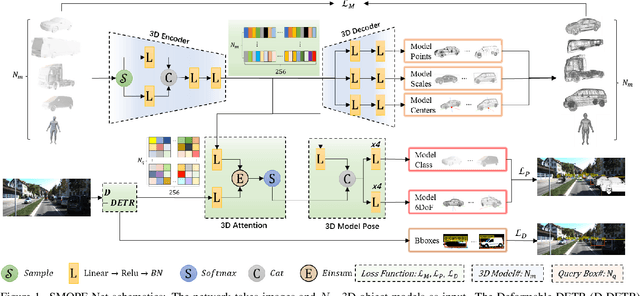

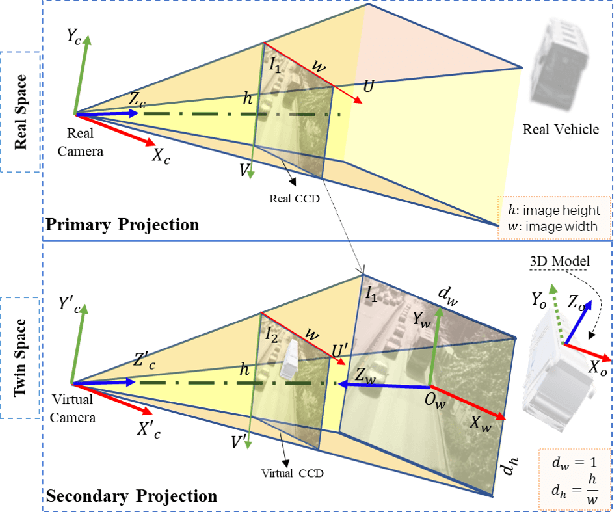
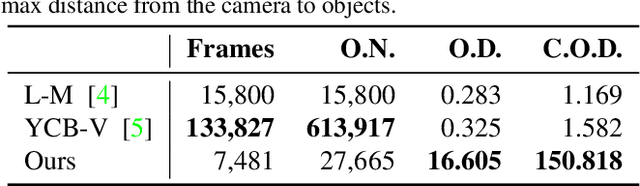
Multiple object detection and pose estimation are vital computer vision tasks. The latter relates to the former as a downstream problem in applications such as robotics and autonomous driving. However, due to the high complexity of both tasks, existing methods generally treat them independently, which is sub-optimal. We propose simultaneous neural modeling of both using monocular vision and 3D model infusion. Our Simultaneous Multiple Object detection and Pose Estimation network (SMOPE-Net) is an end-to-end trainable multitasking network with a composite loss that also provides the advantages of anchor-free detections for efficient downstream pose estimation. To enable the annotation of training data for our learning objective, we develop a Twin-Space object labeling method and demonstrate its correctness analytically and empirically. Using the labeling method, we provide the KITTI-6DoF dataset with $\sim7.5$K annotated frames. Extensive experiments on KITTI-6DoF and the popular LineMod datasets show a consistent performance gain with SMOPE-Net over existing pose estimation methods. Here are links to our proposed SMOPE-Net, KITTI-6DoF dataset, and LabelImg3D labeling tool.
Bi-CLKT: Bi-Graph Contrastive Learning based Knowledge Tracing
Jan 22, 2022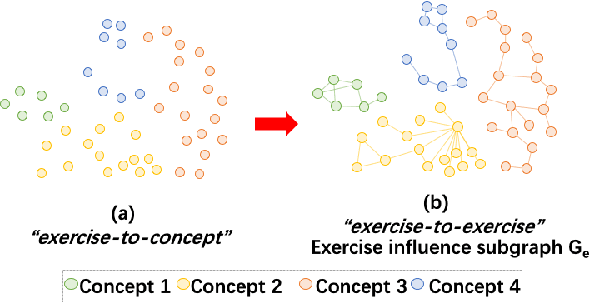
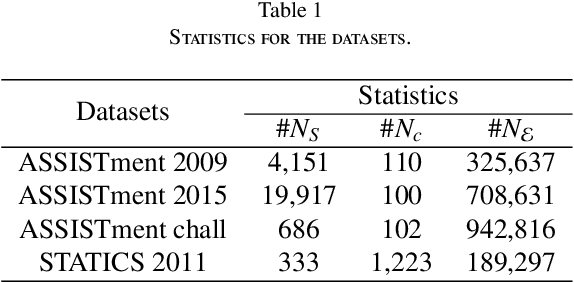
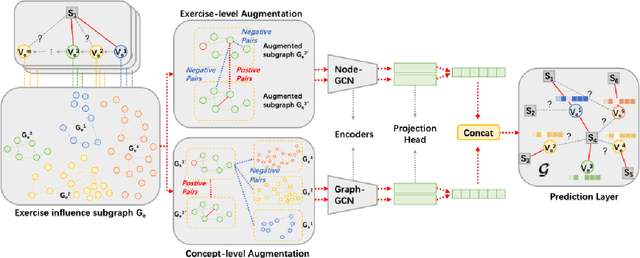
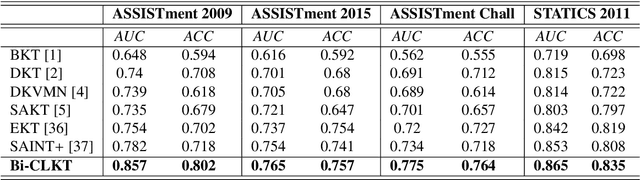
The goal of Knowledge Tracing (KT) is to estimate how well students have mastered a concept based on their historical learning of related exercises. The benefit of knowledge tracing is that students' learning plans can be better organised and adjusted, and interventions can be made when necessary. With the recent rise of deep learning, Deep Knowledge Tracing (DKT) has utilised Recurrent Neural Networks (RNNs) to accomplish this task with some success. Other works have attempted to introduce Graph Neural Networks (GNNs) and redefine the task accordingly to achieve significant improvements. However, these efforts suffer from at least one of the following drawbacks: 1) they pay too much attention to details of the nodes rather than to high-level semantic information; 2) they struggle to effectively establish spatial associations and complex structures of the nodes; and 3) they represent either concepts or exercises only, without integrating them. Inspired by recent advances in self-supervised learning, we propose a Bi-Graph Contrastive Learning based Knowledge Tracing (Bi-CLKT) to address these limitations. Specifically, we design a two-layer contrastive learning scheme based on an "exercise-to-exercise" (E2E) relational subgraph. It involves node-level contrastive learning of subgraphs to obtain discriminative representations of exercises, and graph-level contrastive learning to obtain discriminative representations of concepts. Moreover, we designed a joint contrastive loss to obtain better representations and hence better prediction performance. Also, we explored two different variants, using RNN and memory-augmented neural networks as the prediction layer for comparison to obtain better representations of exercises and concepts respectively. Extensive experiments on four real-world datasets show that the proposed Bi-CLKT and its variants outperform other baseline models.
Distributed Optimization of Graph Convolutional Network using Subgraph Variance
Oct 06, 2021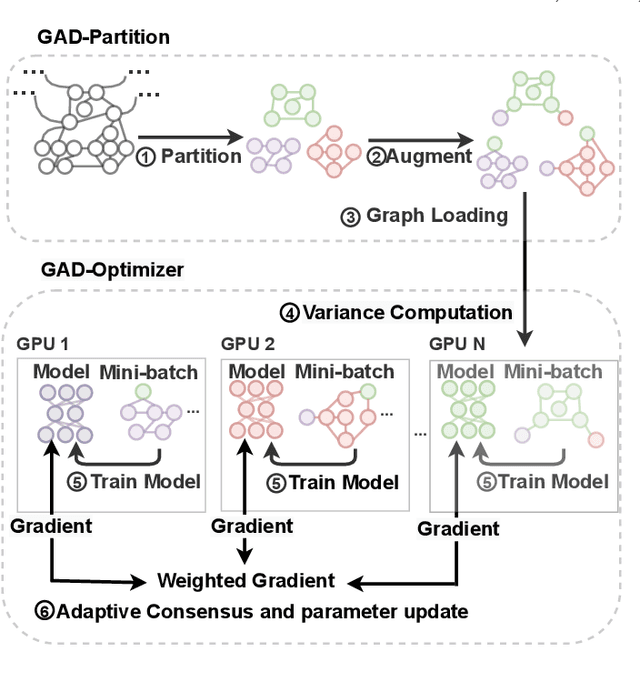


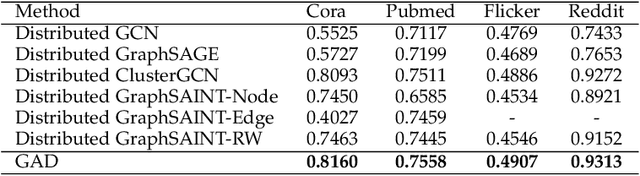
In recent years, Graph Convolutional Networks (GCNs) have achieved great success in learning from graph-structured data. With the growing tendency of graph nodes and edges, GCN training by single processor cannot meet the demand for time and memory, which led to a boom into distributed GCN training frameworks research. However, existing distributed GCN training frameworks require enormous communication costs between processors since multitudes of dependent nodes and edges information need to be collected and transmitted for GCN training from other processors. To address this issue, we propose a Graph Augmentation based Distributed GCN framework(GAD). In particular, GAD has two main components, GAD-Partition and GAD-Optimizer. We first propose a graph augmentation-based partition (GAD-Partition) that can divide original graph into augmented subgraphs to reduce communication by selecting and storing as few significant nodes of other processors as possible while guaranteeing the accuracy of the training. In addition, we further design a subgraph variance-based importance calculation formula and propose a novel weighted global consensus method, collectively referred to as GAD-Optimizer. This optimizer adaptively reduces the importance of subgraphs with large variances for the purpose of reducing the effect of extra variance introduced by GAD-Partition on distributed GCN training. Extensive experiments on four large-scale real-world datasets demonstrate that our framework significantly reduces the communication overhead (50%), improves the convergence speed (2X) of distributed GCN training, and slight gain in accuracy (0.45%) based on minimal redundancy compared to the state-of-the-art methods.
Representation Learning for Short Text Clustering
Sep 21, 2021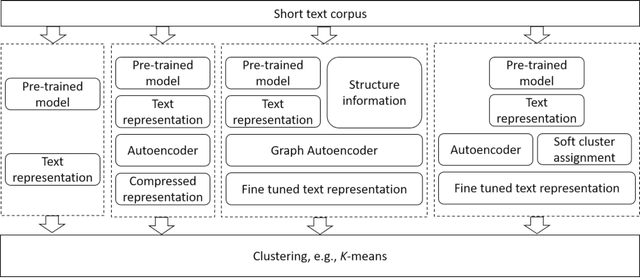
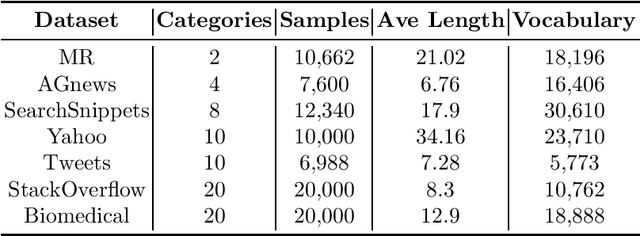
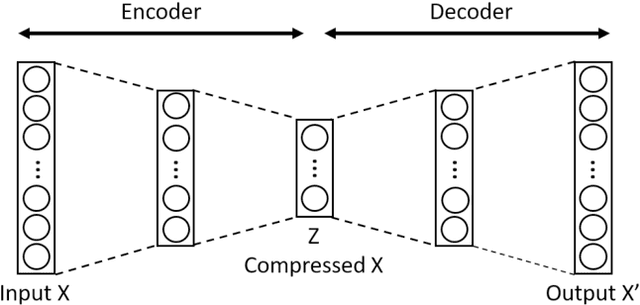
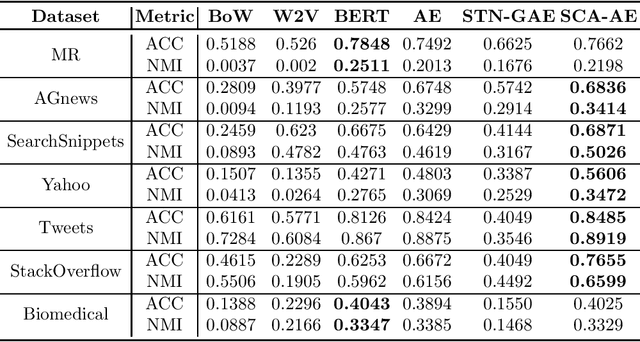
Effective representation learning is critical for short text clustering due to the sparse, high-dimensional and noise attributes of short text corpus. Existing pre-trained models (e.g., Word2vec and BERT) have greatly improved the expressiveness for short text representations with more condensed, low-dimensional and continuous features compared to the traditional Bag-of-Words (BoW) model. However, these models are trained for general purposes and thus are suboptimal for the short text clustering task. In this paper, we propose two methods to exploit the unsupervised autoencoder (AE) framework to further tune the short text representations based on these pre-trained text models for optimal clustering performance. In our first method Structural Text Network Graph Autoencoder (STN-GAE), we exploit the structural text information among the corpus by constructing a text network, and then adopt graph convolutional network as encoder to fuse the structural features with the pre-trained text features for text representation learning. In our second method Soft Cluster Assignment Autoencoder (SCA-AE), we adopt an extra soft cluster assignment constraint on the latent space of autoencoder to encourage the learned text representations to be more clustering-friendly. We tested two methods on seven popular short text datasets, and the experimental results show that when only using the pre-trained model for short text clustering, BERT performs better than BoW and Word2vec. However, as long as we further tune the pre-trained representations, the proposed method like SCA-AE can greatly increase the clustering performance, and the accuracy improvement compared to use BERT alone could reach as much as 14\%.