 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernel Looping: Eliminating Synchronization Boundaries for Peak Inference Performance
Oct 31, 2024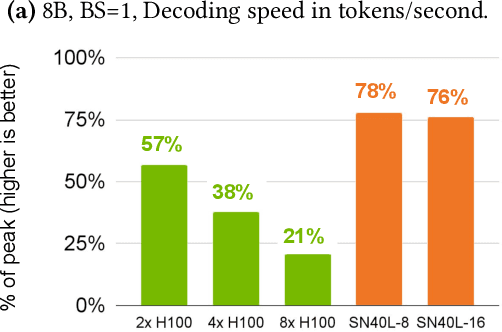
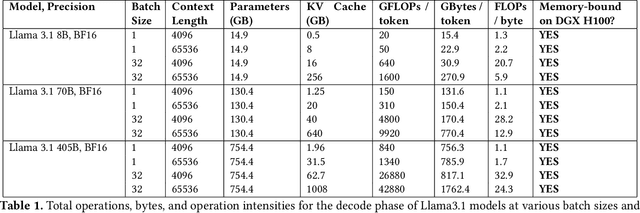
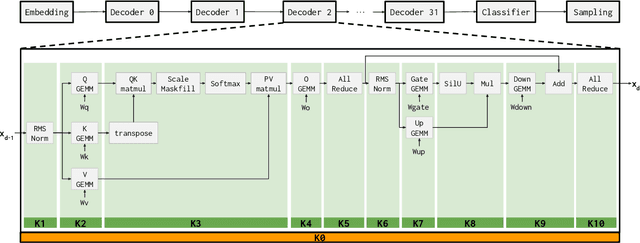

Token generation speed is critical to power the next wave of AI inference applications. GPUs significantly underperform during token generation due to synchronization overheads at kernel boundaries, utilizing only 21% of their peak memory bandwidth. While recent dataflow architectures mitigate these overheads by enabling aggressive fusion of decoder layers into a single kernel, they too leave performance on the table due to synchronization penalties at layer boundaries. This paper presents kernel looping, a specialized global optimization technique which exploits an optimization opportunity brought by combining the unique layer-level fusion possible in modern dataflow architectures with the repeated layer structure found in language models. Kernel looping eliminates synchronization costs between consecutive calls to the same kernel by transforming these calls into a single call to a modified kernel containing a pipelined outer loop. We evaluate kernel looping on the SambaNova SN40L Reconfigurable Dataflow Unit (RDU), a commercial dataflow accelerator for AI. Experiments demonstrate that kernel looping speeds up the decode phase of a wide array of powerful open-source models by up to 2.2$\times$ on SN40L. Kernel looping allows scaling of decode performance over multiple SN40L sockets, achieving speedups of up to 2.5$\times$. Finally, kernel looping enables SN40L to achieve over 90% of peak performance on 8 and 16 sockets and achieve a speedup of up to 3.7$\times$ over DGX H100. Kernel looping, as well as the models evaluated in this paper, are deployed in production in a commercial AI inference cloud.
SambaNova SN40L: Scaling the AI Memory Wall with Dataflow and Composition of Experts
May 13, 2024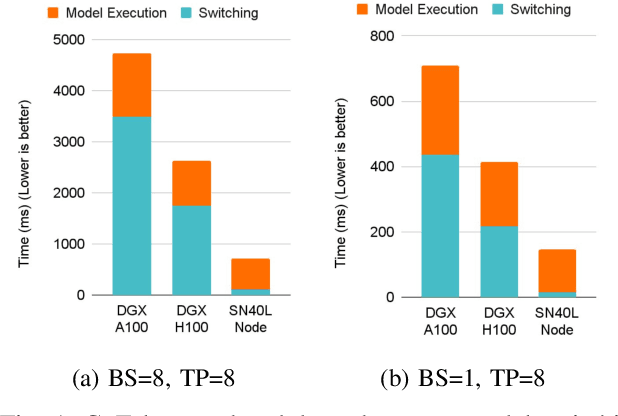
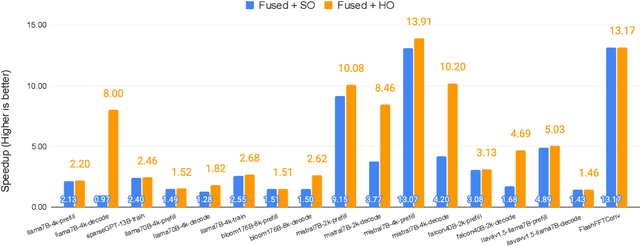
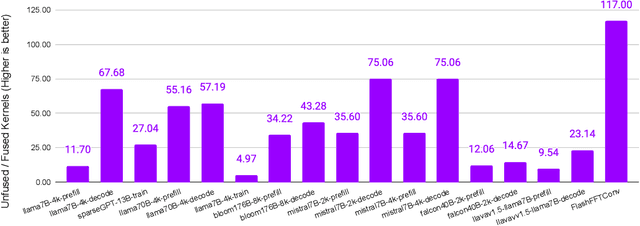
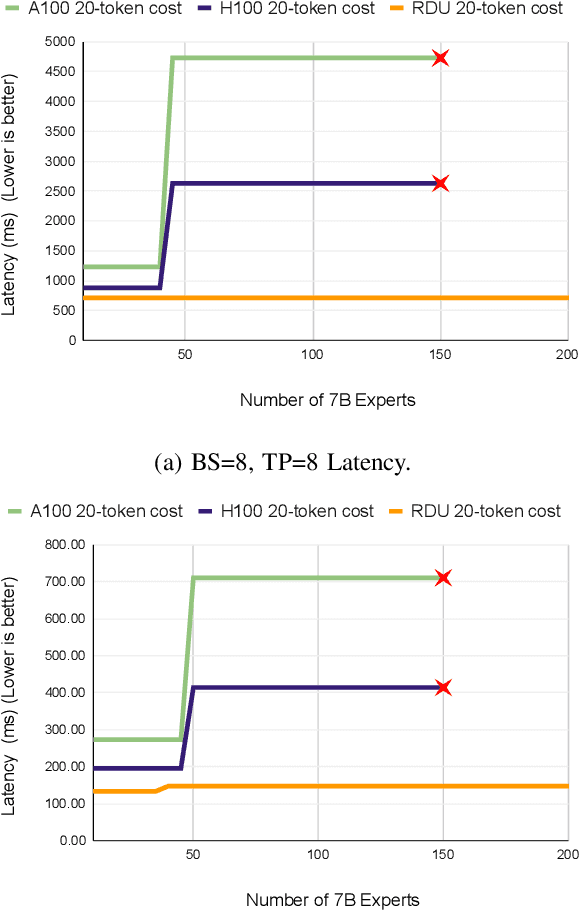
Monolithic large language models (LLMs) like GPT-4 have paved the way for modern generative AI applications. Training, serving, and maintaining monolithic LLMs at scale, however, remains prohibitively expensive and challenging. The disproportionate increase in compute-to-memory ratio of modern AI accelerators have created a memory wall, necessitating new methods to deploy AI. Composition of Experts (CoE) is an alternative modular approach that lowers the cost and complexity of training and serving. However, this approach presents two key challenges when using conventional hardware: (1) without fused operations, smaller models have lower operational intensity, which makes high utilization more challenging to achieve; and (2) hosting a large number of models can be either prohibitively expensive or slow when dynamically switching between them. In this paper, we describe how combining CoE, streaming dataflow, and a three-tier memory system scales the AI memory wall. We describe Samba-CoE, a CoE system with 150 experts and a trillion total parameters. We deploy Samba-CoE on the SambaNova SN40L Reconfigurable Dataflow Unit (RDU) - a commercial dataflow accelerator architecture that has been co-designed for enterprise inference and training applications. The chip introduces a new three-tier memory system with on-chip distributed SRAM, on-package HBM, and off-package DDR DRAM. A dedicated inter-RDU network enables scaling up and out over multiple sockets. We demonstrate speedups ranging from 2x to 13x on various benchmarks running on eight RDU sockets compared with an unfused baseline. We show that for CoE inference deployments, the 8-socket RDU Node reduces machine footprint by up to 19x, speeds up model switching time by 15x to 31x, and achieves an overall speedup of 3.7x over a DGX H100 and 6.6x over a DGX A100.
Evaluation of a Recommender System for Assisting Novice Game Designers
Aug 13, 2019
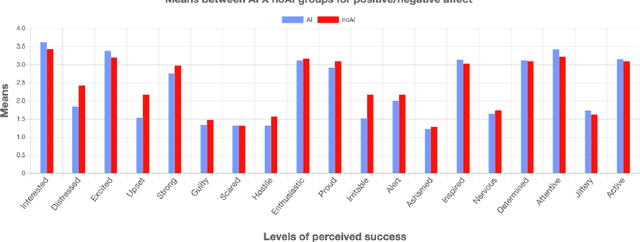
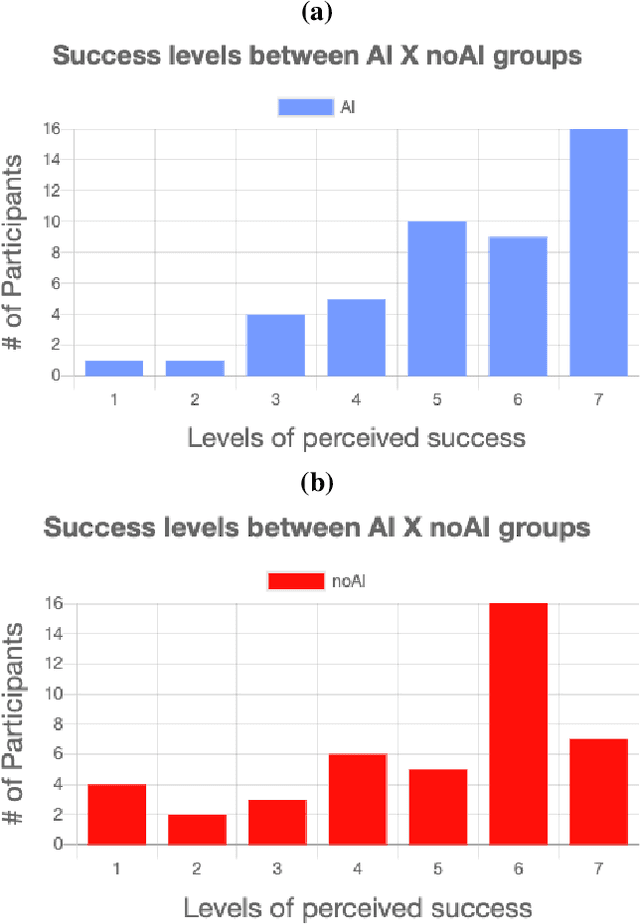
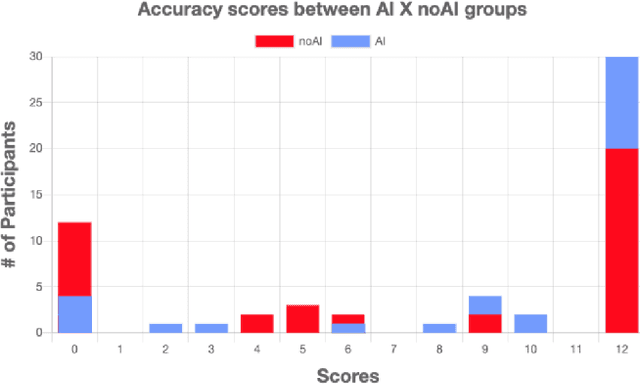
Game development is a complex task involving multiple disciplines and technologies. Developers and researchers alike have suggested that AI-driven game design assistants may improve developer workflow. We present a recommender system for assisting humans in game design as well as a rigorous human subjects study to validate it. The AI-driven game design assistance system suggests game mechanics to designers based on characteristics of the game being developed. We believe this method can bring creative insights and increase users' productivity. We conducted quantitative studies that showed the recommender system increases users' levels of accuracy and computational affect, and decreases their levels of workload.
Evaluating Word Embedding Models: Methods and Experimental Results
Jan 29, 2019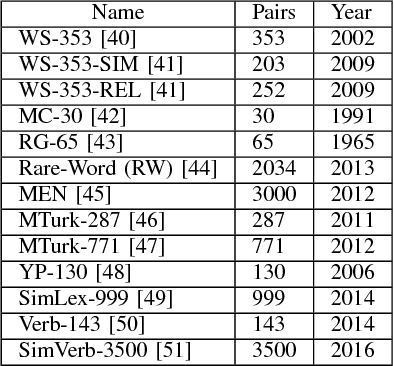

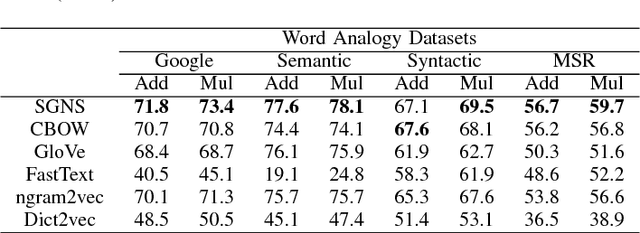
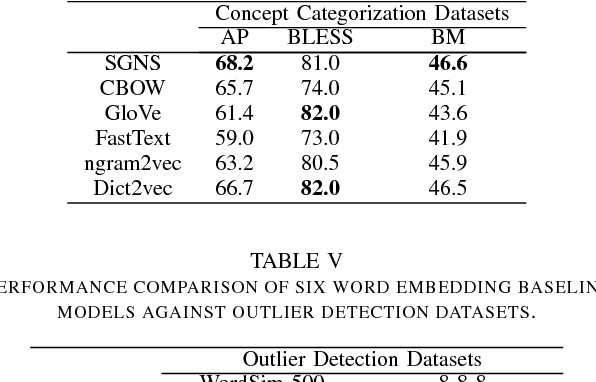
Extensive evaluation on a large number of word embedding models for language processing applications is conducted in this work. First, we introduce popular word embedding models and discuss desired properties of word models and evaluation methods (or evaluators). Then, we categorize evaluators into intrinsic and extrinsic two types. Intrinsic evaluators test the quality of a representation independent of specific natural language processing tasks while extrinsic evaluators use word embeddings as input features to a downstream task and measure changes in performance metrics specific to that task. We report experimental results of intrinsic and extrinsic evaluators on six word embedding models. It is shown that different evaluators focus on different aspects of word models, and some are more correlated with natural language processing tasks. Finally, we adopt correlation analysis to study performance consistency of extrinsic and intrinsic evalutors.
Post-Processing of Word Representations via Variance Normalization and Dynamic Embedding
Sep 05, 2018
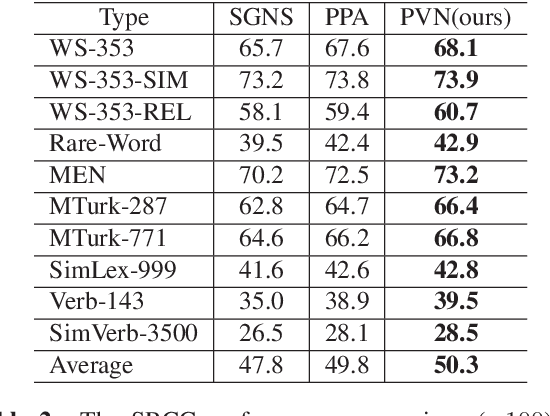
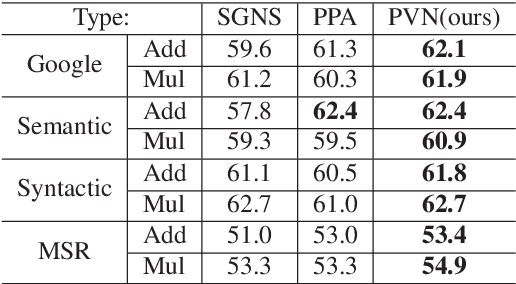
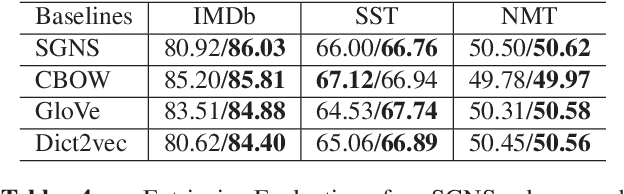
Although embedded vector representations of words offer impressive performance on many natural language processing (NLP) applications, the information of ordered input sequences is lost to some extent if only context-based samples are used in the training. For further performance improvement, two new post-processing techniques, called post-processing via variance normalization (PVN) and post-processing via dynamic embedding (PDE), are proposed in this work. The PVN method normalizes the variance of principal components of word vectors while the PDE method learns orthogonal latent variables from ordered input sequences. The PVN and the PDE methods can be integrated to achieve better performance. We apply these post-processing techniques to two popular word embedding methods (i.e., word2vec and GloVe) to yield their post-processed representations. Extensive experiments are conducted to demonstrate the effectiveness of the proposed post-processing techniques.