 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernel Looping: Eliminating Synchronization Boundaries for Peak Inference Performance
Oct 31, 2024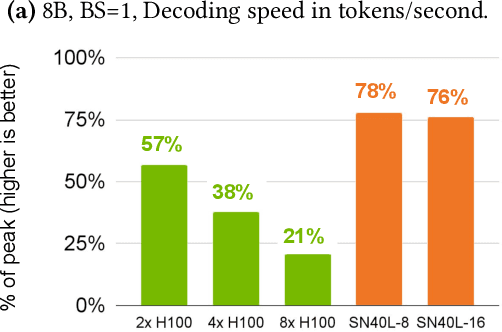
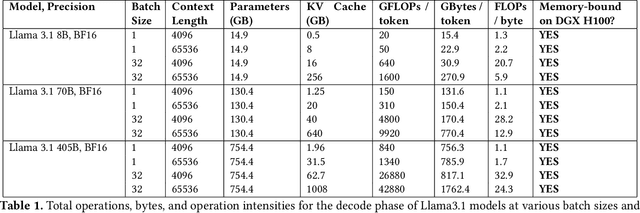
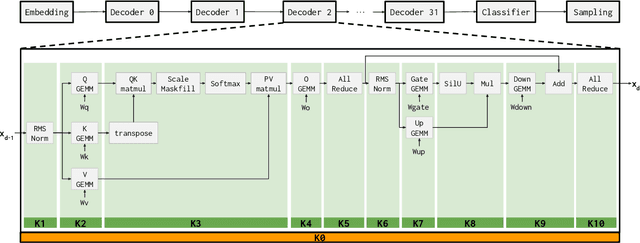

Token generation speed is critical to power the next wave of AI inference applications. GPUs significantly underperform during token generation due to synchronization overheads at kernel boundaries, utilizing only 21% of their peak memory bandwidth. While recent dataflow architectures mitigate these overheads by enabling aggressive fusion of decoder layers into a single kernel, they too leave performance on the table due to synchronization penalties at layer boundaries. This paper presents kernel looping, a specialized global optimization technique which exploits an optimization opportunity brought by combining the unique layer-level fusion possible in modern dataflow architectures with the repeated layer structure found in language models. Kernel looping eliminates synchronization costs between consecutive calls to the same kernel by transforming these calls into a single call to a modified kernel containing a pipelined outer loop. We evaluate kernel looping on the SambaNova SN40L Reconfigurable Dataflow Unit (RDU), a commercial dataflow accelerator for AI. Experiments demonstrate that kernel looping speeds up the decode phase of a wide array of powerful open-source models by up to 2.2$\times$ on SN40L. Kernel looping allows scaling of decode performance over multiple SN40L sockets, achieving speedups of up to 2.5$\times$. Finally, kernel looping enables SN40L to achieve over 90% of peak performance on 8 and 16 sockets and achieve a speedup of up to 3.7$\times$ over DGX H100. Kernel looping, as well as the models evaluated in this paper, are deployed in production in a commercial AI inference cloud.
Practical Design Space Exploration
Oct 11, 2018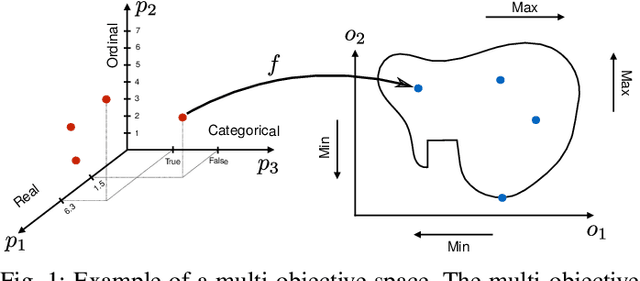

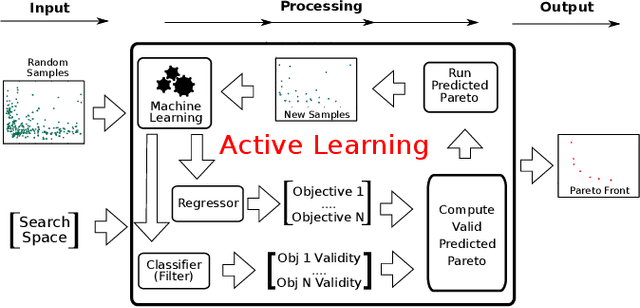
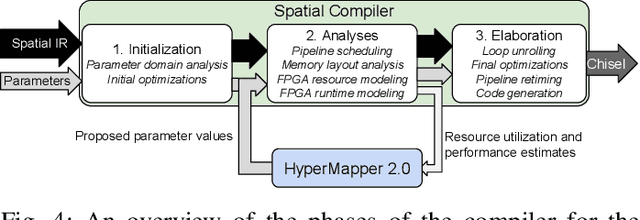
Multi-objective optimization is a crucial matter in computer systems design space exploration because real-world applications often rely on a trade-off between several objectives. Derivatives are usually not available or impractical to compute and the feasibility of an experiment can not always be determined in advance. These problems are particularly difficult when the feasible region is relatively small, and it may be prohibitive to even find a feasible experiment, let alone an optimal one. We introduce a new methodology and corresponding software framework, HyperMapper 2.0, which handles multi-objective optimization, unknown feasibility constraints, and categorical/ordinal variables. This new methodology also supports injection of user prior knowledge in the search when available. All of these features are common requirements in computer systems but rarely exposed in existing design space exploration systems. The proposed methodology follows a white-box model which is simple to understand and interpret (unlike, for example, neural networks) and can be used by the user to better understand the results of the automatic search. We apply and evaluate the new methodology to automatic static tuning of hardware accelerators within the recently introduced Spatial programming language, with minimization of design runtime and compute logic under the constraint of the design fitting in a target field programmable gate array chip. Our results show that HyperMapper 2.0 provides better Pareto fronts compared to state-of-the-art baselines, with better or competitive hypervolume indicator and with 8x improvement in sampling budget for most of the benchmarks explored.