 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernel Looping: Eliminating Synchronization Boundaries for Peak Inference Performance
Oct 31, 2024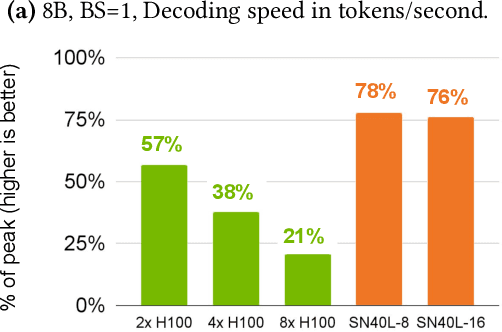
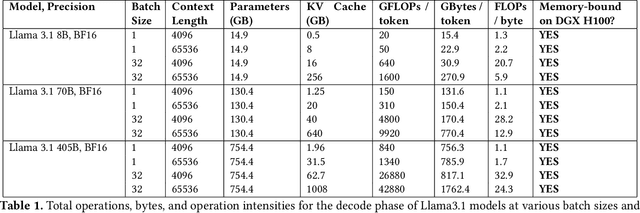
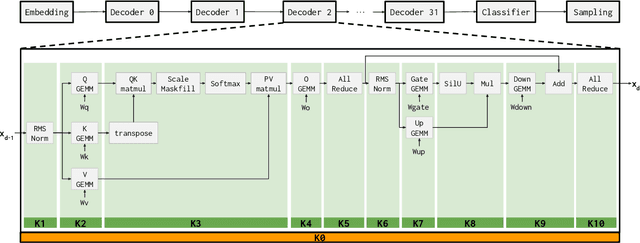

Token generation speed is critical to power the next wave of AI inference applications. GPUs significantly underperform during token generation due to synchronization overheads at kernel boundaries, utilizing only 21% of their peak memory bandwidth. While recent dataflow architectures mitigate these overheads by enabling aggressive fusion of decoder layers into a single kernel, they too leave performance on the table due to synchronization penalties at layer boundaries. This paper presents kernel looping, a specialized global optimization technique which exploits an optimization opportunity brought by combining the unique layer-level fusion possible in modern dataflow architectures with the repeated layer structure found in language models. Kernel looping eliminates synchronization costs between consecutive calls to the same kernel by transforming these calls into a single call to a modified kernel containing a pipelined outer loop. We evaluate kernel looping on the SambaNova SN40L Reconfigurable Dataflow Unit (RDU), a commercial dataflow accelerator for AI. Experiments demonstrate that kernel looping speeds up the decode phase of a wide array of powerful open-source models by up to 2.2$\times$ on SN40L. Kernel looping allows scaling of decode performance over multiple SN40L sockets, achieving speedups of up to 2.5$\times$. Finally, kernel looping enables SN40L to achieve over 90% of peak performance on 8 and 16 sockets and achieve a speedup of up to 3.7$\times$ over DGX H100. Kernel looping, as well as the models evaluated in this paper, are deployed in production in a commercial AI inference cloud.
SambaLingo: Teaching Large Language Models New Languages
Apr 08, 2024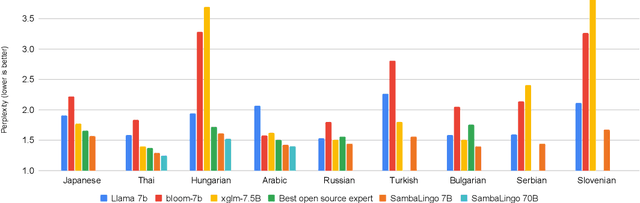
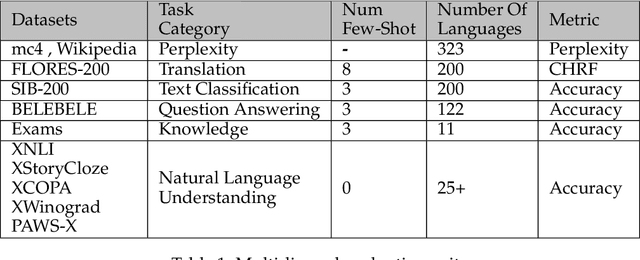
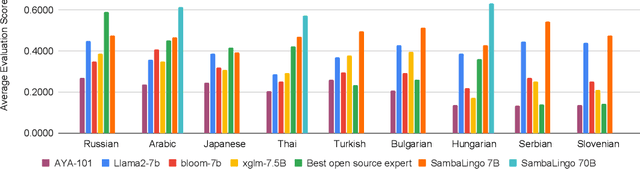

Despite the widespread availability of LLMs, there remains a substantial gap in their capabilities and availability across diverse languages. One approach to address these issues has been to take an existing pre-trained LLM and continue to train it on new languages. While prior works have experimented with language adaptation, many questions around best practices and methodology have not been covered. In this paper, we present a comprehensive investigation into the adaptation of LLMs to new languages. Our study covers the key components in this process, including vocabulary extension, direct preference optimization and the data scarcity problem for human alignment in low-resource languages. We scale these experiments across 9 languages and 2 parameter scales (7B and 70B). We compare our models against Llama 2, Aya-101, XGLM, BLOOM and existing language experts, outperforming all prior published baselines. Additionally, all evaluation code and checkpoints are made public to facilitate future research.
Sharp bounds for the number of regions of maxout networks and vertices of Minkowski sums
Apr 16, 2021



We present results on the number of linear regions of the functions that can be represented by artificial feedforward neural networks with maxout units. A rank-k maxout unit is a function computing the maximum of $k$ linear functions. For networks with a single layer of maxout units, the linear regions correspond to the upper vertices of a Minkowski sum of polytopes. We obtain face counting formulas in terms of the intersection posets of tropical hypersurfaces or the number of upper faces of partial Minkowski sums, along with explicit sharp upper bounds for the number of regions for any input dimension, any number of units, and any ranks, in the cases with and without biases. Based on these results we also obtain asymptotically sharp upper bounds for networks with multiple layers.